




 提出了一种新的对抗性二进制编码框架,用于行人重新识别任务,该框架不仅提高了匹配效率,还保证了良好的识别准确性。通过采用生成对抗网络(GAN)的概念,该方法能够在不损失判别信息的情况下,将高维特征转换成紧凑的二进制代码。
提出了一种新的对抗性二进制编码框架,用于行人重新识别任务,该框架不仅提高了匹配效率,还保证了良好的识别准确性。通过采用生成对抗网络(GAN)的概念,该方法能够在不损失判别信息的情况下,将高维特征转换成紧凑的二进制代码。
论文链接:https://arxiv.org/pdf/1803.10914.pdf
摘要:行人重新识别(ReID)旨在匹配不同视图/场景的人。 除了准确性之外,由于使用大规模数据的苛刻应用,匹配效率受到越来越多的关注。 已经提出了几种基于二进制编码的方法用于有效的ReID,其可以学习将高维特征映射到紧凑二进制代码的投影,或者通过简单地插入具有类似tanh的激活的附加完全连接层来直接采用深度神经网络。然而,前一种方法需要耗时的手工特征提取和复杂(离散)优化; 由于直接的激活功能,后者极大地缺乏必要的判别信息。 在本文中,我们提出了一个简单而有效的框架,有效的ReID灵感来自对抗性学习的最新进展。 具体而言,提议的对抗性二进制编码(ABC)框架不是学习显式投影或添加完全连接的映射层,而是隐含且有效地指导二进制代码的提取。通过为ABC配备用于ReID任务的深度三元网络,可以进一步增强所提取代码的可辨别性。 更重要的是,ABC和三元组网络以端到端的方式同时进行优化。 对三个大规模ReID基准测试的广泛实验证明了我们的方法优于最先进的方法。
1、Introduction
给定行人的一个或多个图像,行人重新识别(ReID)旨在从在不同场景和各种视点中捕获的大量图像中检索具有相同身份的人。 ReID支持各种潜在的应用程序,例如长期跨场景跟踪和刑事检索。 然而,由于不同相机的姿势,视点和照明的显着变化,该任务仍然具有挑战性。
已经提出了许多ReID方法,其中大多数采用高维(通常是数千或更多)特征[1-6],以便用各种线索(例如颜色,纹理和空间时间线索)全面地表示人。 这直接为随后的相似性测量(例如度量学习)带来了更高的计算复杂度。 此外,目前的大规模ReID基准测试包含许多身份和摄像头来模拟真实场景,使现有的最先进的ReID方法在计算上难以承受[7]。 因此,尽管匹配精度有了显着的提高,但计算和存储器要求同时变得更具挑战性。
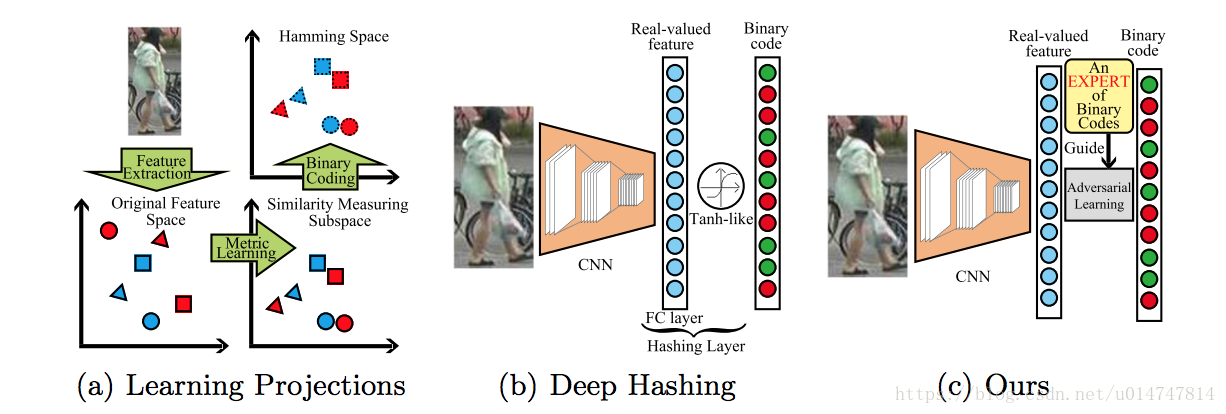
Fig.1. 用于有效ReID的不同二进制编码方案。 我们的方法避免了耗时的投影学习,并通过对抗性训练以直观的方式产生高质量的二进制代码,而不使用类似于tanh的激活。
二进制编码(即散列),被[8,9]采用,将高维特征映射到紧凑的二进制代码,并有效地测量低维汉明空间中的相似性。 它是高效ReID的有前途的解决方案之一。 基于散列的ReID方法可以主要分为两类:
1)图1(a)所示的方法学习多个投影矩阵以同时将原始特征映射到低维和判别汉明空间。 然而,其目标通常是若干子任务的非凸联合函数(例如,保持相似性的映射和二进制变换),这需要复杂函数的显式设计和耗时的非凸(离散)优化。 内存存储和计算效率是严重的问题,尤其是在处理大规模数据时。
2)图1(b)显示了一种基于深度神经网络的方法,与传统方法相比,通过使用小批量学习算法和高级GPU,能够更有效地处理大规模数据。 这里的二进制代码是通过在网络末端插入散列层来生成的。 然而,散列层只是一个完全连接的层,然后是类似tanh的激活,以强制二进制形式的输出。 这种简单的方案很难在散列的重要原则(例如平衡性和独立性[10])下限制输出,以获得高质量的二进制代码。 此外,散列层的输出倾向于位于类似tanh函数的近似线性部分中,以保持可辨别性。 因此,通过符号函数直接对输出进行二值化将丢失判别信息。
为解决上述问题,本文提出了一种统一的端到端深度学习框架,用于高效的ReID,旨在共同学习判别特征表示,准确的相似性度量和隐式二元变换。 特别地,我们通过采用生成性对抗网络(GAN)[11,12]来建议对抗性二进制编码(ABC),以将特征规则化为二进制形式而不损失可辨性(参见图2)。 对抗性学习不是明确的预测,而是使目标分布(以二进制形式)成为“专家”,隐含地指导网络在相同分布下生成样本。 具体来说,我们采用伯努利分布来指导CNN生成离散特征。 受益于伯努利分布的性质,我们的ABC可以生成符合散列的重要原则的高质量判别代码,例如:平衡性。如图1(c)所示,我们的策略避免了耗时的显式投影学习和低质量的代码,具有简单的tanh式激活。 更重要的是,我们的ABC可以灵活地嵌入到任何相似性回归网络(例如深三元网络)中,并以端到端的方式与网络共同优化。 本文的主要贡献概括如下:
1)我们提出了一种基于深层对抗性学习的二元转换策略。 所提出的架构由用于特征提取的CNN和用于区分实值和二进制特征的鉴别器网络组成,其中CNN被引导以二进制形式生成特征以混淆鉴别器。 因此,这些特征被隐式地规则化为二进制代码。
2)无缝容纳上述对抗性二进制编码模块的端到端深度神经网络是为高效的ReID而构建的。 我们联合优化二元变换和相似性测量。 因此,在特征二值化期间很大程度上保留了辨别信息。
3)在三个大规模ReID基准测试(即CUHK03 [13],Market-1501 [14]和DukeMTMC-reID [15])上的广泛实验清楚地证明了我们的框架在准确性和效率方面的优越性, 其他基于二进制编码和最先进的ReID方法。
2、 Related work
2.1 Person re-identification: 传统方法通常为ReID提出某些特征学习算法,包括低级颜色特征和局部渐变,以及高级特征。由于深度神经网络的突破性能,越来越多地提出基于深度学习的ReID方法。 例如, 暹罗CNN(siamese CNNs)和三联CNN广泛用于相似性测量。最近,出现了几种基于二进制编码的方法处理ReID中存在的高计算和存储成本问题。
2.2 Generative adversarial nets:GAN提供了一种将随机变量从简单分布映射到某个复杂分布的方法,并已广泛用于图像生成,风格转移和潜在特征学习。 为了稳定和量化GAN的训练,提出了一项名为Wasserstein GAN(WGAN)的改进,并在其中进行了改进。 最近,GAN也用于图像检索问题。在[44]中,采用GAN来区分合成图像和真实图像,目标是提高二进制代码的可辨性。 GAN也被用来增强[45]中发生器的中间表示。 但是,这些各种研究仍然简单地采用tanh式激活进行二值化。据我们所知,我们的ABC是第一部直观采用的工作对抗性学习的精神,为高效的ReID执行二进制转换。
3 、Approach
拟议的框架将高维实值特征转换为紧凑二进制代码主要基于对抗性学习。 在下面的,我们首先简要回顾3.1节中GAN的原理。 然后,我们介绍对抗二进制编码(ABC)详见3.2节。 在3.3节中,我们提出具有三元网络的联合端到端框架,以实现高效的ReID。
3.1 A Brief Review of GANs
GAN难以训练,因此生成器可能无法生成无论是真实的还是多样的样品。 Arjovsky等在[42,46]为解决这个问题引入WGAN,而WGAN则优化了Wasserstein损失Jensen-Shannon散度评估相似性。基于Wasserstein-1距离提供更强的梯度稳定性(也称为Earth-Mover(EM)距离)。 而且,WGAN提供了有意义的学习曲线对调试和超参数搜索很有用。 因此,在这项工作中,我们采用WGAN的策略进行对抗性学习。(关于WGAN 更多学习可参考https://zhuanlan.zhihu.com/p/25071913)
3.2 Adversarial Binary Coding
我们的二进制编码方案直观地受到GAN的启发。并非制定明确的散列函数(即学习显式投影),我们隐含地引导深度神经网络直接学习数据从原始分布(即图像)到GAN框架中的二元向量分布的转换。 在本节中,我们将重点介绍高效的端到端ReID框架中的二进制转换模块。 如何保持语义/判别力转换过程中的信息在第3.3节中解释。
所提出的对抗性二进制编码框架如图2所示。特征提取器可以是任何CNN架构(在这项工作中采用ResNet-50 [47]),最终将图像表示为特征向量。 与此同时,二进制代码采样器对二进制向量的每个位执行随机采样。 为了满足[10]中提到的有效二进制编码原理,我们从伯努利分布中抽样,基于此分布的概率为50%对于每个比特为0或1,并且不同的比特彼此独立。期望鉴别器将二元向量分类为正样本,将实值特征向量作为负样本。 因此,提取器训练使用(2)中的Wasserstein损失(W损失)生成在相同的正样本分布下的特征向量。
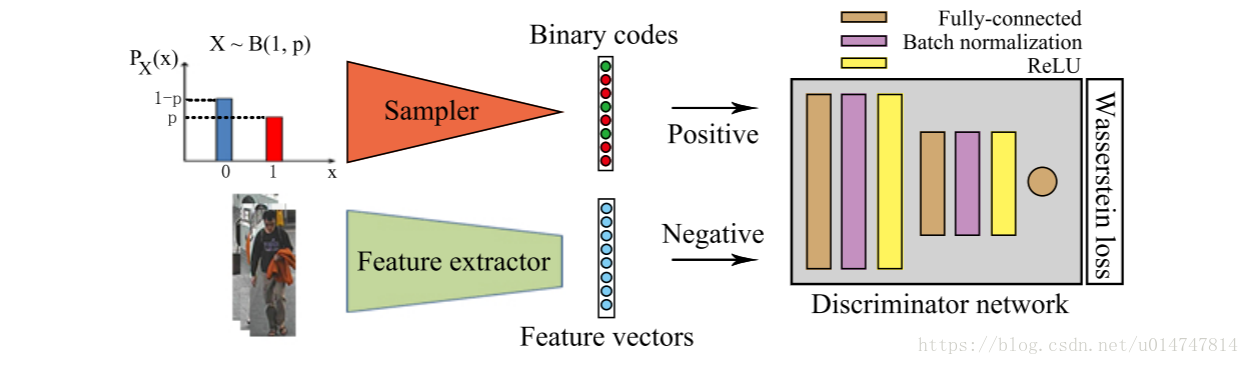
fig. 2. 对抗二进制编码(ABC)框架的图示。 鉴别者网络接收采样的二进制代码作为正样本并提取实值作为负样本的特征。 特征提取器网络和鉴别器网络在Wasserstein损失(W损失)下联合优化,这样提取器就被迫以二进制形式生成特征。
正式地,我们将一批n个图像I = {I1,I2,...。。 ,ln}表示为位于分布pI下。 特征提取器表示为映射函数f(I)它在GAN( 编码分布为q(Z | I)其中Z = {z1,z2,...。。 ,zn}表示提取的特征向量)中起着生成器G的作用。 q(Z | I)旨在从原始分布pI转换数据到目标分布q:
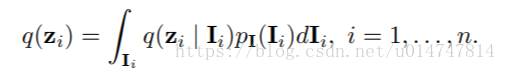
由于二项分布相当于具有相同概率的多个伯努利样本,因此提取器基本上通过使用Wasserstein距离将后验q与先前二项分布匹配来正则化。
如上所述,我们使用ResNet-50 [47]作为骨干模型,其中采用整流线性单元(ReLU)作为激活功能。因此,由于ReLU的非负输出,我们用{0,1}而不是{-1,1}表示二进制代码的每一位。我们进一步发现,如果直接输入特征向量和二进制代码到鉴别器和相似性回归损失,而没有归一化 (例如图3中的三元损失),由于预期的0或1输出与学习算法之间的矛盾,性能将严重恶化。更具体地,神经网络的权重通常被初始化为非常小的值(远小于1)。同时,学习算法仔细控制权重的比例(例如通过学习速率和体重衰减机制)以避免梯度消失或在损失函数下爆炸。因此,网络提取的特征也将非常接近0,因为它们与权重共享相同的比例。相反,我们的ABC期望输出功能的每个维度被约束在0或1附近。结果,我们将遇到不稳定优化过程如果不采用任何规范化。
为了解决上述问题,我们通过l2归一化将输出特征向量和采样二进制代码标准化为相同的比例。 至于实值特征,我们采用标准的l2-Norm操作。 就二进制代码而言,我们具体如下进行归一化。 给定一批随机二进制向量{Bi},其中Bi∈{0,1}二进制向量可以直接归一化如下
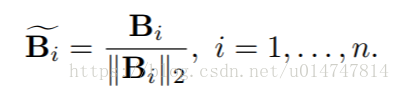
然而,每个向量的l2归一化可能是不同的,因为每个二进制向量可能包含不同数量比特的1。换句话说,归一化向量{Bi~}中的非零条目的值将是不同的。 这导致不稳定的训练过程,其中损失无法明确指导优化。 因此,在本研究中,我们采用伯努利分布的期望来计算二元向量的l2-范数。 具体而言,我们计算均匀归一化因子λ:

3.3 Triplet Loss based Efficient ReID Framework
为了不仅将特征转换为二进制形式,还测量二进制代码之间的相似性,ABC进一步嵌入到三元组网络中以确保所学习的二进制代码的可辨别性。以下为三元组网络的损失函数L:
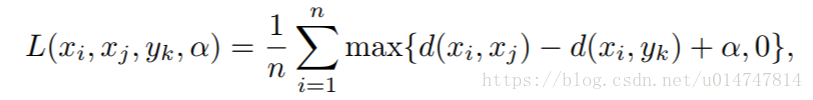
其中xi,xj和yk是输入特征,α是正负对之间的施加距离边界,d(·)测量相似距离。 xi和xj是来自同一类的特征(在ReID中具有相同的标识),而yk来自另一个类(不同的标识)。 三元组损失迫使负对中的样本之间的距离大于正对中的样本之间的距离。 因此,它广泛用于旨在检索具有高相关性的数据的任务中。
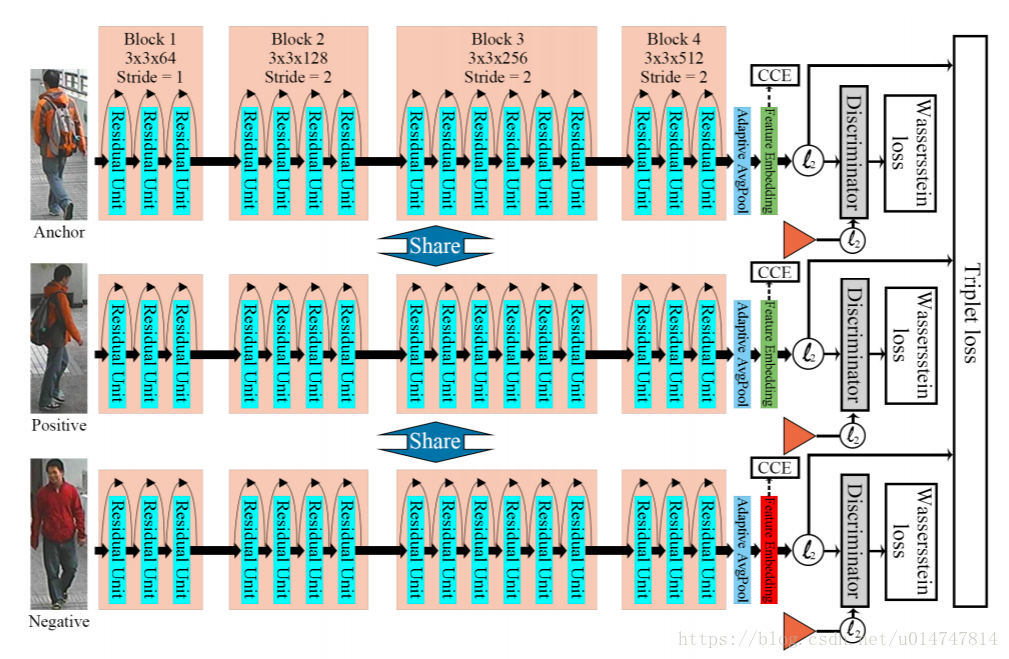
Fig.3.基于三元组损失的对抗二进制编码嵌入高效ReID框架的图示。 特征提取网络是预先训练的ResNet-50模型。 首先通过训练图像上的交叉熵误差(CCE)损失对网络进行微调,然后通过triplet损失和Wasserstein损失进行训练,以生成有区别的二元特征。
高效ReID的总体框架如图3所示。采用ImageNet [49]预训练的ResNet-50作为骨干模型,其中固定平均池化层被自适应平均池替换,以适应不同的输入大小,然后是特征嵌入(完全连接)层,以将特征尺寸减少到预期长度。 在训练开始时,我们通过解决传统的分类问题来微调具有交叉熵误差(CEE)损失的行人图像上的模型,即每个类包含一个人的图像。 因为对小型数据集上的大型图像集预先训练的模型进行微调已经被验证为知识转移的有效方法。 与从头开始的训练相比,这对于具有较少数据的深度网络而言更有助于更容易地找到最佳参数并且更快地达到收敛。注意,在该阶段中,最后一层的输出未通过l2范数归一化,就像用于图像分类的传统CNN一样。 之后,我们通过联合优化用于二进制编码的Wasserstein损失和用于相似性测量的三元损失来训练具有归一化的模型,如图3所示。 特别是对于三联批的组成,我们随机选择n个不同的人,并从每个人的不同视图中挑选两个图像作为锚和阳性样本。 然后我们随机选择不同于锚的人的图像作为每个三联体中的阴性样本。(注:关于微调的更多知识可以查看:https://blog.youkuaiyun.com/hlx371240/article/details/40398657)
特别是,在训练阶段,我们采用欧几里德距离来测量三元损失的实值特征之间的相似性,而不进行二值化。 因为欧几里德距离提供比汉明距离更明显更稳定的梯度,同时获得等效距离测量结果作为汉明距离。 通过这种方式,三元损失侧重于减少类内距离并根据实值特征扩大类间距离,而Wasserstein损失侧重于实值特征的二元变换。
在测试阶段,图像被发送到训练有素的CNN以获得实值特征,其中每个条目应非常接近二进制值,最后我们将特征二值化如下:
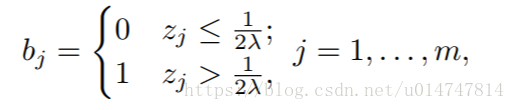
其中zj是实值特征的第j个条目的值zi = [z1 ,... ,zm]∈R由f函数提取,并且bj∈{0,1}是二值化后zj的二进制位。查询和图集之间的汉明距离进一步使用极快的XOR运算来计算相似度。
4、 Experiments
我们在三个大规模ReID数据集上评估我们的方法的性能:CUHK03 [13],Market-1501 [14]和DukeMTMC-reID [15,50]。 我们的实验目标主要是回答以下三个研究问题:
问题1:与实际值相比,我们学习的二进制代码的计算和存储效率如何? (4.2节)
问题2:与基于二进制编码的ReID方法(4.3节)和最先进的非散列ReID方法(第4.4节)相比,我们的方法如何执行?
问题3:我们的性能如何随着不同的配置而变化(例如,不同的相似性网络,有和没有l2归一化 /微调)?(4.5节)
4.1 Datasets and Settings
Market-1501 在六个摄像机下包含32,668个自动检测到的128×64个包围框,包括1,501个行人,并提供固定的评估协议。 在实验中,训练迭代的次数设置为8,000,并且三元组损失的边缘初始化为0.2并且在1,000次迭代之后增加到0.3并且在4,000次迭代之后增加到0.4。
我们基于PyTorch深度学习库实现了我们的框架。硬件环境是一台配备Intel Core CPU(3.4GHz),32 GB内存和NVIDIA GTX TITAN X GPU的PC。 对于所有数据集,图像被水平翻转以增强训练样本。 批量大小在训练前阶段设置为64,在随后的训练中更改为128。 实验中提取器的学习率初始化为0.001,并随着迭代次数降低至0.0001。 鉴别器的学习率始终设置为0.01。为了确保稳定性,我们在每20次全局优化迭代后单独更新GAN 10迭代。 每个GAN迭代包括5次鉴别器更新迭代和1次生成器(提取器)更新迭代。 在实验中,如果代码可公开获得,我们会重新运行比较方法,以评估其效率以进行公平比较。
4.2 Evaluation of Computation and Storage Efficiency
我们首先用不同的比特长度来评估我们方法的效率,因为较短的二进制代码更有效但可能导致精度下降,而较长的代码则相反。检索查询的时间(Q.时间)和存储图库功能的内存(Mem)如图4所示。可以看出,二进制代码消耗的查询时间和内存远小于实值特征。与具有比特长度的二进制特征相比,实值特征的匹配时间和存储器显着增加得更快。此外,我们比较表1中实值和二进制特征的秩-1匹配率。从表的最后两行可以看出,具有更多位(例如1024或2048)的二值化特征仅比相应的实值特征稍差,证明了具有足够容量的,使用我们的方法通过二元特征很好地保留了判别信息。 值得注意的是,即使使用2048位,我们的二进制特征也需要比实值对应物少得多的查询时间和内存。
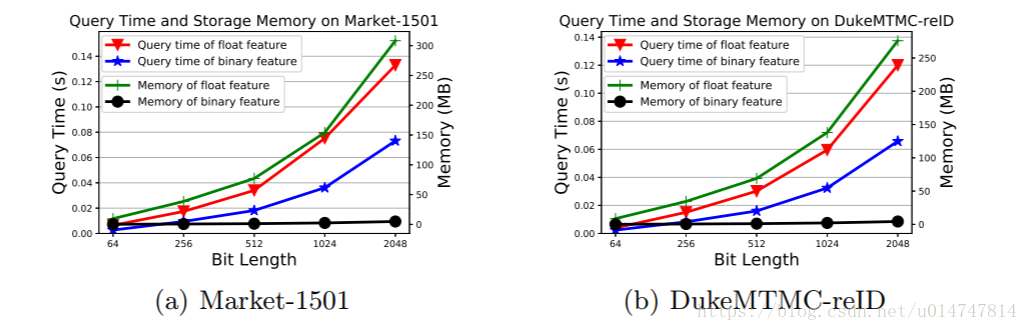
Fig.4 根据不同的比特长度比较实值/二进制特征的匹配时间和存储器成本
除了匹配时间之外,还应考虑特征提取所消耗的时间(F.时间)。 随着ReID中的数据规模变大,有必要在短时间内处理大量查询。 因此,我们比较了通过两种最先进的方法提取我们方法的特征所消耗的时间,即局部最大发生表示(LOMO)[2]和分层高斯描述符(GOG)[3],它们被传统的ReID方法广泛采用。如表2所示,我们的方法比LOMO和GOG更快地提取特征。
此外,我们在图5中提供了2048位长的框架的训练损失。我们可以观察到,随着训练的进行,与GAN相对应的损失稳定下降。 Market1501的三元亏损在每个边界值都得到了很好的优化。 CUHK03和DukeMTMC-reID上的三元损失在某些边际值处变为波动,但是在训练结束时损失可以达到稳定状态。
4.3 Comparison with Binary Coding based Methods
在这里,我们将我们的框架与基于以下最先进的二进制编码(散列)的ReID方法进行比较:1)深度散列:深度规范化相似性比较散列(DRSCH)[33],基于散列的深度语义排序。。。。
4.4 Comparison with the State-of-the-Art Methods
。。。显然,我们的框架不仅优于许多现有的非散列方法,而且在匹配效率方面也取得了显着的优势。 如果图库集包含更多样本,则优势更加突出。 例如,ABC的查询时间至少比Market-1501上的非哈希方法快几十倍,其中有19,732个图库样本。 有几种方法采用LOMO,它将图像表示为26960-dim实值特征。 不同的是,我们的方法只是将图像表示为2048位二进制代码,这需要更少的内存。
4.5 Effects of Different Network Settings
在本节中,我们将建议的ABC嵌入到不同的相似性测量网络中,并评估不同设置下的性能。 我们首先评估两种广泛用于测量相似性的网络,即Siamese网络[27,28]和三元网络。 Siamese网络接收一对图像,如果它们来自同一类,则最小化图像之间的距离,如果它们具有不同的标签,则最大化距离。 在我们的实验中评估的Siamese网络采用与三元网络相同的ResNet-50骨干模型,并使用收缩损失来测量相似性。
从表8中可以看出,采用Siamese网络的性能比三元网络差。 这是因为Siamese网络的损失太严格了,即,强制将一个身份的图像投影到子空间中的单个点上。 不同的是,三元损失允许来自一个人的图像位于歧管上,同时在不同人的图像之间实施更大的距离。 我们还可以观察到,将ABC嵌入三元组网络可以获得比Siamese网络更好的结果。
如3.2节所述,我们将生成的特征和二进制代码规范化为相同的比例,以消除两个模块之间的冲突。 在这里,我们还比较了有和没有l2标准化的网络。 从表8中可以看出,在归一化之后性能显着提高。
此外,我们评估微调对三个数据集的影响。 图6显示微调的三元损失比没有微调的三元损失快。 由于所使用的ResNet-50网络在ImageNet上经过预先培训,因此它已经捕获了各种有用的图像功能。 微调网络进一步使得能够比从头开始训练网络更有效地学习专门用于人物表示的特征。
5 、Conclusion
在这项工作中,提出了用于有效行人重新识别的对抗性二进制编码(ABC)框架,其可以从行人图像生成有区别且有效的二进制特征。 具体来说,我们的ABC训练了一个鉴别器网络来区分实值特征和二元特征,以指导特征提取器网络在Wasserstein损失下生成二进制形式的特征。 ABC框架进一步嵌入到深三元网络中,以保留ReID任务的二进制特征的语义信息。对三个大规模ReID数据集的大量实验表明,我们的方法优于最先进的基于散列的ReID方法,并且与最先进的非散列ReID方法相比具有竞争力,同时显著减少了时间和内存 成本。 考虑到三元网络已被最近提出的其他网络架构所取代,未来这项工作的一个可能的改进是探索ABC框架和其他更复杂的相似性测量框架的组合。

















 1472
1472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









