




Ollama部署LLaVA多模态大模型集成SpringBoot
1. 概述
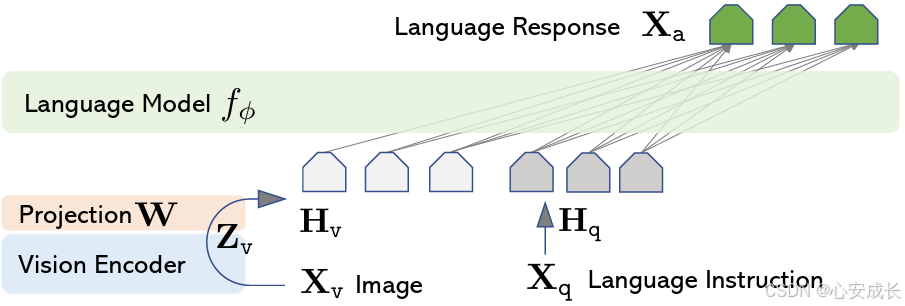
上一篇测试了在window下部署本地llama7b模型的测试效果,这一篇旨在记录部署LLaVA,大型语言和视觉助手 (LLaVA),这是一个端到端训练的大型多模态模型,它连接视觉编码器和 LLM,用于通用的视觉和语言理解。
2. 安装LLaVA
安装ollama过程可以参考《初探Ollama部署llama3集成SpringAI》
打开在powershell, 输入如下命令,这里我选用的llava 13b模型
3. 与Spring AI进行集成
3.1 部署环境
- 创建Spring Maven环境 https://start.spring.io/
- Java JDK 21
- Spring Boot 3.2.5
- ollama
3.2 配置URL模型
我们在application.yml中配置模型内容
spring:
application:
name: spring-ai-ollama-llava-demo
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: llava:13b
temperature: 0.7
server 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5865
5865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









