 OpenAI发布o3模型,开启视觉推理新时代
OpenAI发布o3模型,开启视觉推理新时代




又是在凌晨,OpenAI 发布了 o 系列模型的最新成果 o3 和 o4-mini,这是他们迄今为止发布的最智能模型,也标志着 ChatGPT 能力的巨大飞跃。
这次新发布的推理模型能够像智能体一样使用并组合 ChatGPT 中的每一个工具 —— 这包括搜索互联网、用 Python 分析上传的文件和其他数据、深入推理视觉输入,甚至生成图像。

至关重要的是,这些模型经过训练,能够推理何时以及如何使用工具,以在正确输出格式下产生详细且深思熟虑的答案,通常在不到一分钟的时间内解决更复杂的问题。这使得它们能够更有效地应对多面性问题,迈向一个更具自主性的 ChatGPT,独立为你执行任务。
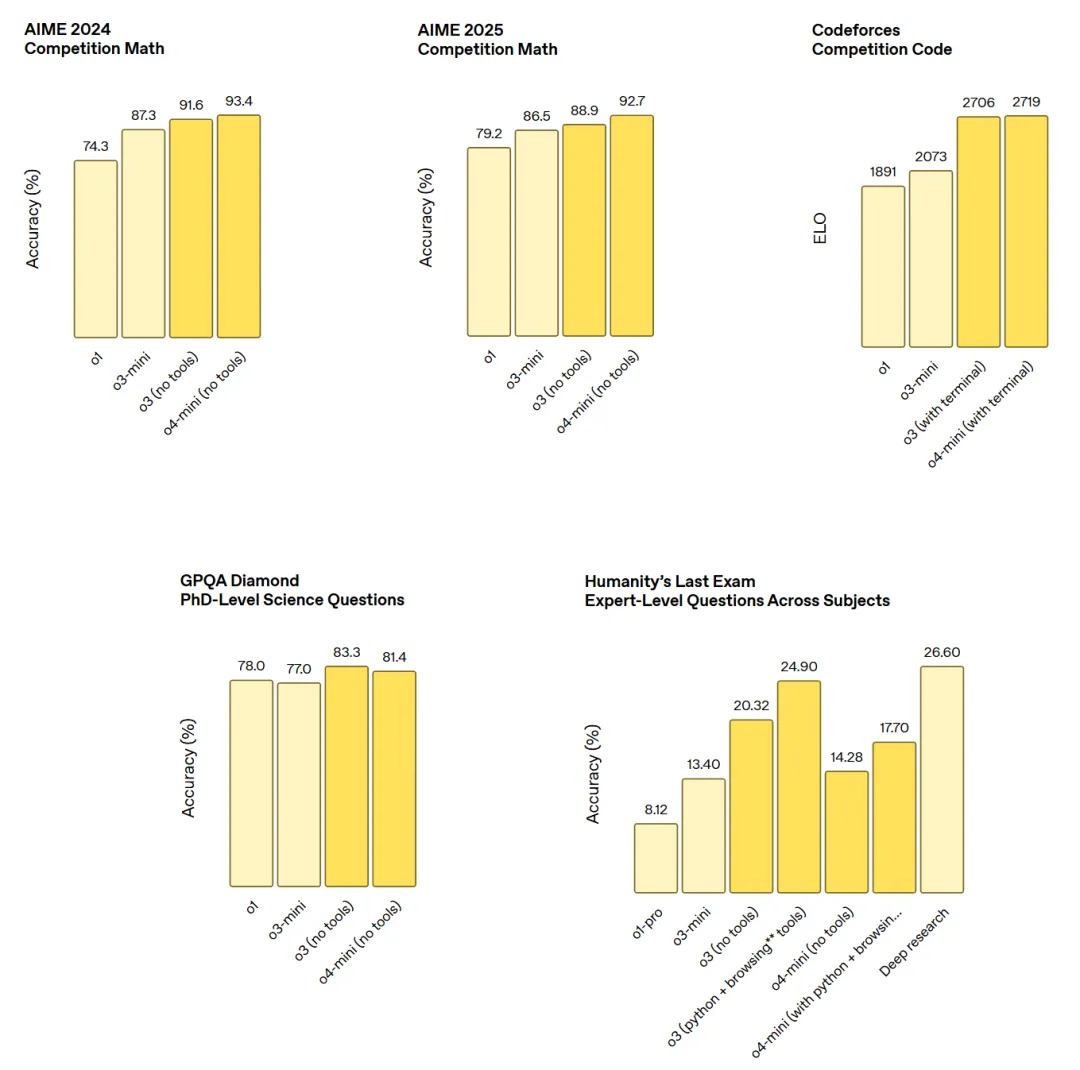
这是新模型的一些性能参数。
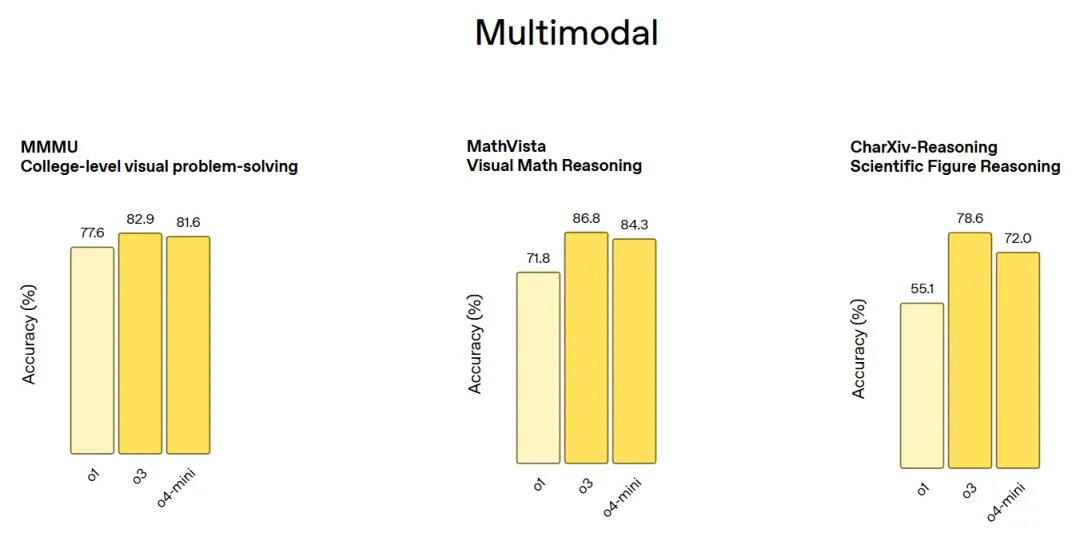
多模态基准测试(包括 MMMU 大学水平的视觉问答、MathVista 视觉数学推理和 CharXiv-Reasoning 论文图表推理):
编程基准测试(包括 SWE-Lancer: IC SWE Diamod Freelancer 编程任务和 SWE-Bench Verified 软件工程任务):
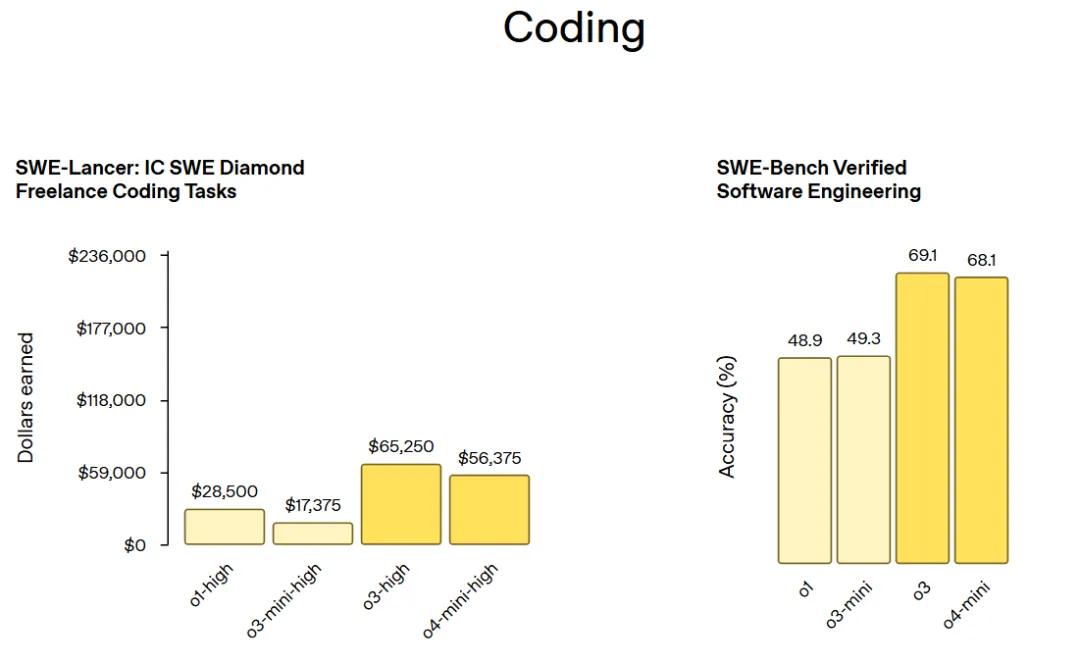
Aider Polyglot 代码编辑任务:
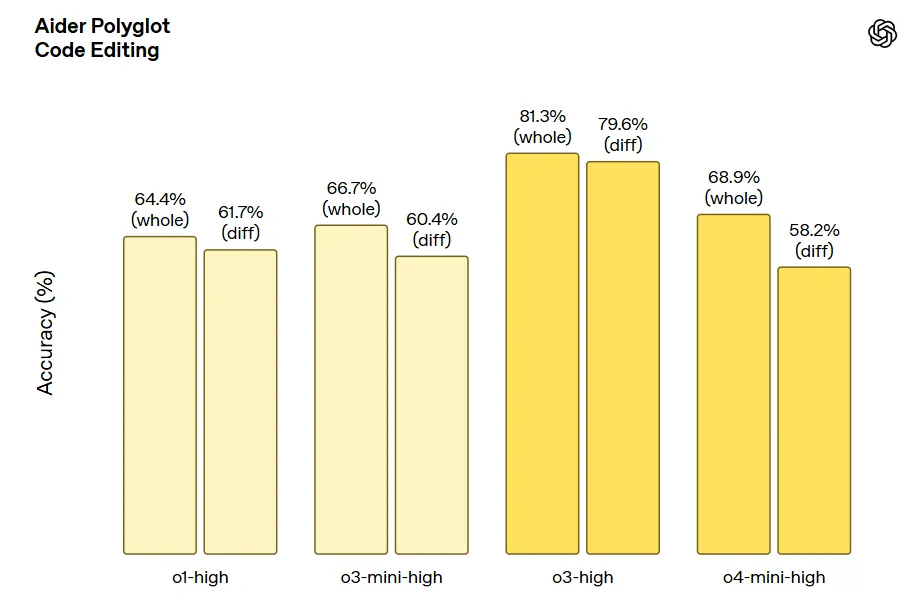
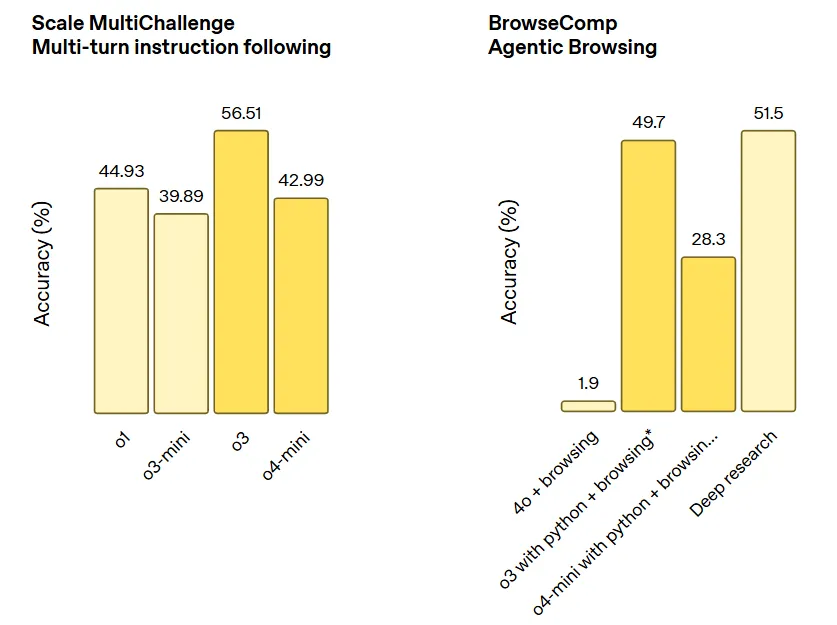
指令遵循和智能体工具使用任务(包括 Scale MultiChallenge 多轮指令遵循和 BrowerComp 智能体浏览):
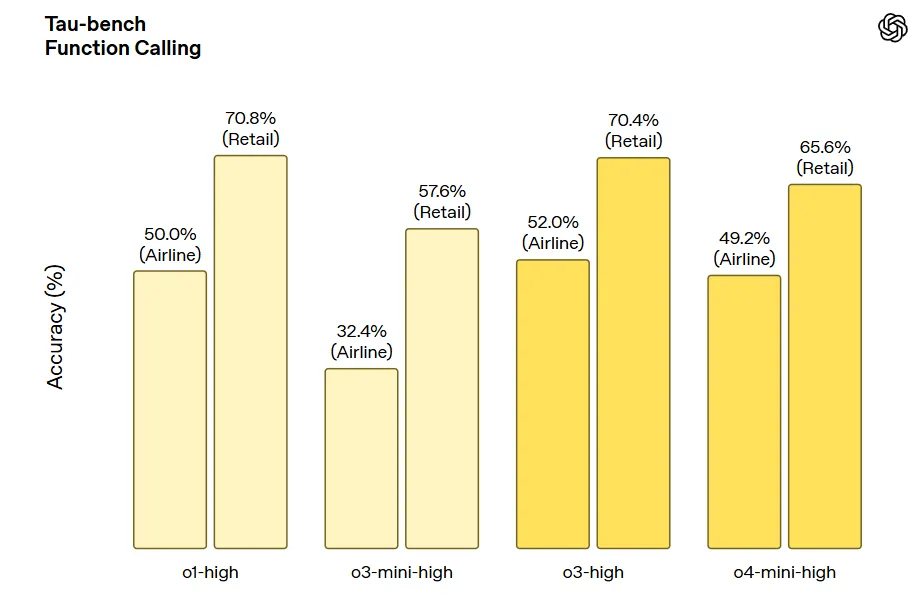
Tau-bench 函数调用:
以下案例来自于卡神,原文链接如下:
https://mp.weixin.qq.com/s?__biz=MzIyMzA5NjEyMA==&mid=2647670512&idx=1&sn=b78a84a56ed19aa9c27a1d8294c0130e&scene=21#wechat_redirect
*
*
对,就这么个东西,让你猜这是中国的哪,在右下角的地图上打标,离终点越近,分越高。
我直接把这个扔给了o3,我们来看看,他的思考过程。

非常离谱的,自己去看图,把图片放大,一点一点思考,这个地方不对,哎换个地方我再放大看看。
以前模型的思维链,只有文字,而这次,这是大模型第一次,真正的把图片,也融入到了推理中。
我们再回过头来看看,刚才那道猜地题,它给出的答案。

虽然没有那么肯定,但是也给出了答案,北京门头沟、房山,109国道,妙峰山那一段。
我们来揭晓答案。
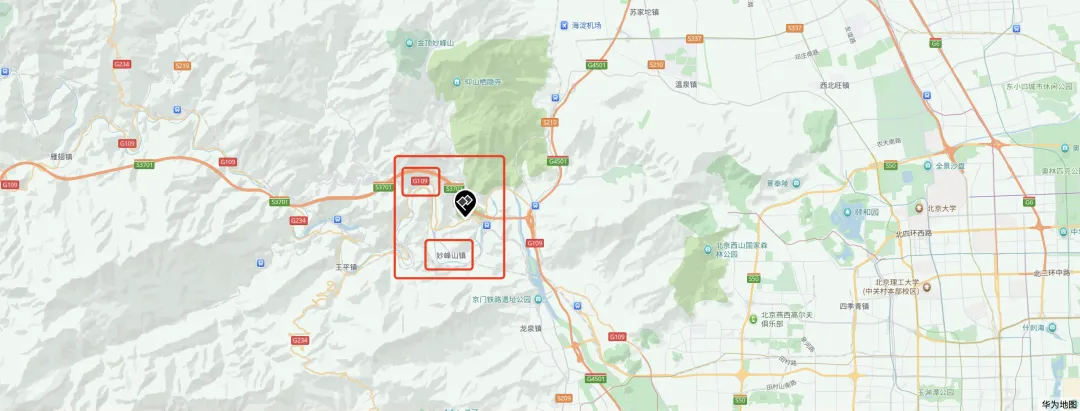
可能有些人对这个地点不熟悉,这个地方,叫北京,门头沟,109国道,妙峰山。
那一刻,我真的有点起鸡皮疙瘩了。
因为你会发现,AI开始像人一样去看图、像人一样去思考了。
以前你说AI懂图,懂什么?懂像素?懂特征?是的,它会提特征、会分类、会打标签,但它并不看图思考。
它是一个图像识别器,但不是一个图像思考者。
而今天,o3,是第一次让模型学会了看图思考,学会了视觉推理。
这个变化,堪称范式级别的跃迁。
是不是效果很惊艳,但是真正从底层来看的话,技术原理并没有0-1的变革性创新,甚至不足以称之为范式级跃迁。
换个角度来看,o3更像一个智能体了,具备了工具使用能力,在推理的基础上去调用了图片截取、放大、解析的能力。
这或许也是以后通用大模型发展的趋势,在参数性能没有巨幅提升的背景下,逐步扩展模型能力,向上渗透,与智能体的边界也会越来越模糊。
其实真正0-1创新,还是那些通用大模型、多模态大模型、推理大模型、智能体、多智能体协调等。在MCP和A2A协议诞生之后,在Manus出现以后,未来几年的发展趋势已经确定,剩下的只是时间问题,大家共同去见证。
就比如说,不久之后肯定还会出视频推理,工具使用进化为大模型调用基础编辑器给自己写工具(类比于使用工具和创造工具的区别),视频生成也会进一步突破10s、20s、直到120分钟直出影片。
用一个比较幽默的评论结尾吧:
程序员第一天:这也太厉害了吧!第二天:N+1

















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









