




今日CS.CV计算机视觉论文速览
Tue, 5 Mar 2019
Totally 63 papers

Interesting:
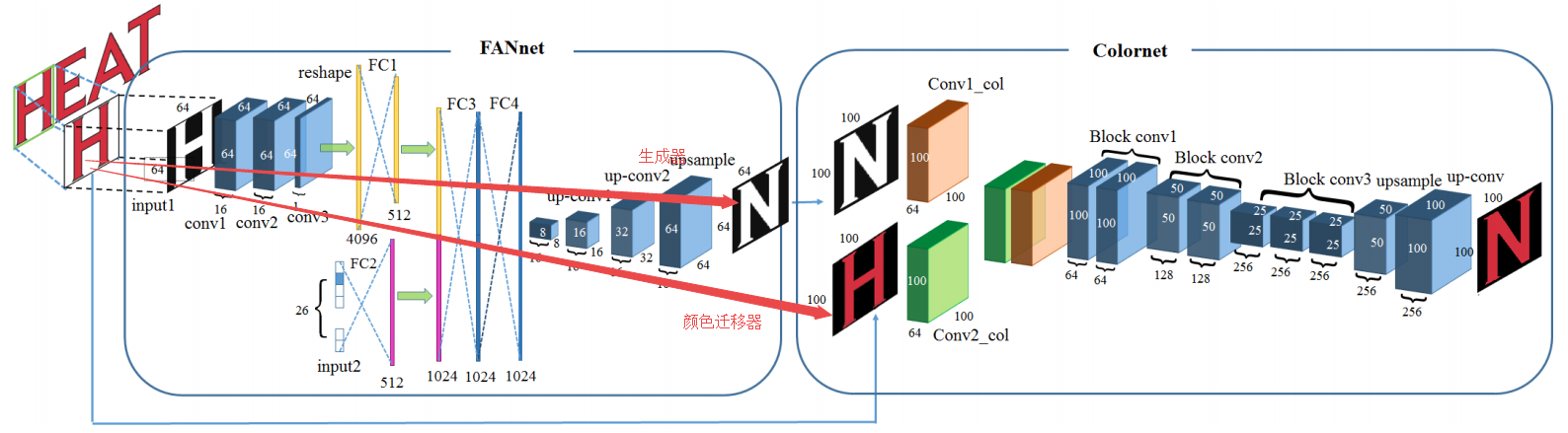
?STEFANN,基于字体自适应网络实现场景中的文字编辑修改。目前的场景文字识别很成功,按时对于场景中文字修改的工作还很少。这篇文章对于照片中文字进行自适应修改,不仅能够修复图像中的文字信息,同时可以得到戏剧性的效果。研究人员首先聚焦于如何生成不违和的文字,包括字体和颜色等。提出了一个多输入的字体特征生成器,并将原图的颜色迁移到目标图像上去。随后将生成的文字放置到原图的对应位置,并进行视觉连续性处理。(from Indian Statistical Institute Kolkata) CVPR
模型的架构如下,包含了字体生成器和颜色迁移器组成:
一些有趣的效果:


数据集:ICDAR
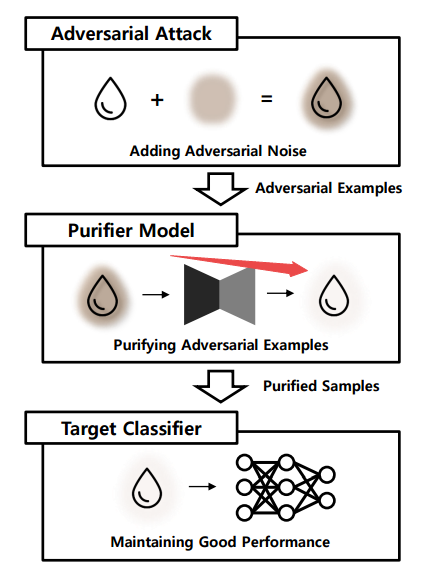
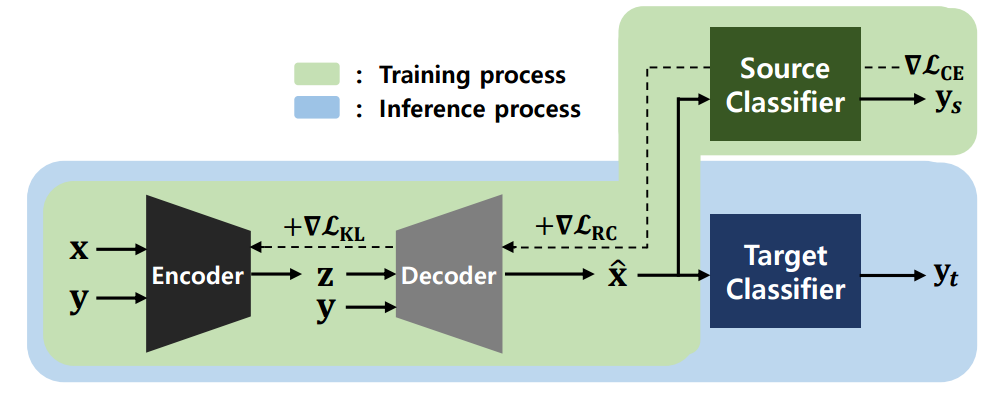
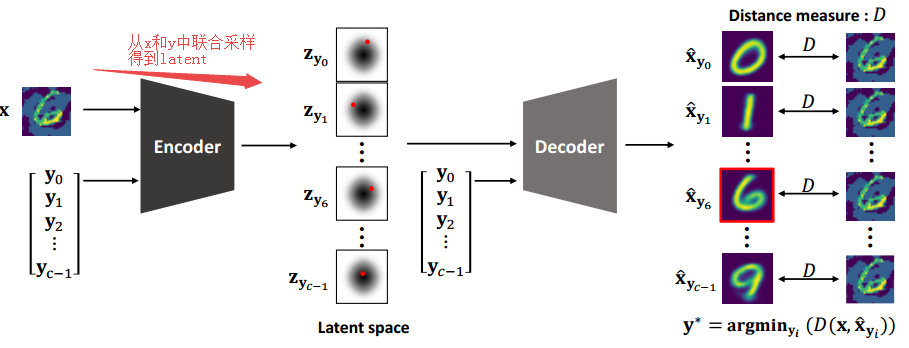
?PuVAE基于变分自编码器提纯对抗样本,提出了一种利用变分自编码器提出对抗样本,降低对抗噪声的模型。为了防御深度学习中对抗样本的影响,研究人员提出了一种基于变分自编码器提纯对抗样本的方法。通过将对抗样本投影到流型空间的不同类别上,来估计和消除对抗扰动。实验表面这种方法性能强劲并比普通DefenseGan快130倍。(首尔国立大学)
模型结构示例图:
训练和推理过程示例图:
推理过程的示意图:
与类似方法的比较:
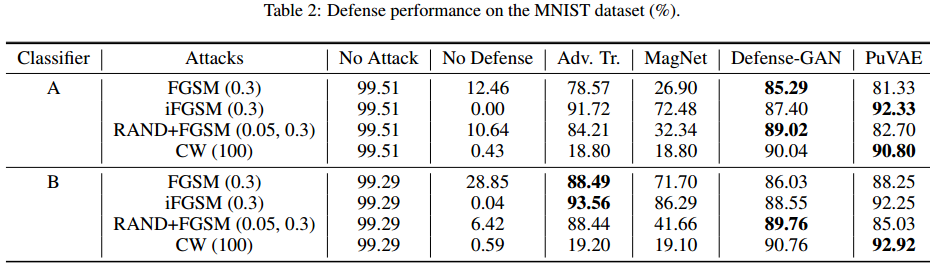
?SRNTT基于迁移学习的图像超分辨,单图像超分辨在近年来获得了较大的发展,但对于参考图片与目标图片不相似的情况下生成的超分辨率质量较差。研究人员提出了一种可以将高分辨图像中的细节纹理信息用于提高低分辨率图像分辨率的迁移学习方法,利用自然纹理迁移的技术实现了图像超分辨。利用多级神经空间匹配来代替像素间的配准,提高了模型利用语义相似片层的能力,并用优雅的方法提高了超分辨的能力。研究还建立了RefSR数据集,包含了低分辨图像和一系列层级相似性的配对图像。(from adobe)
一些结果:

模型的架构如下图所示,将多层级的特征进行了交换,并将参考图像下采样得到与低分辨图频谱一致的约束:
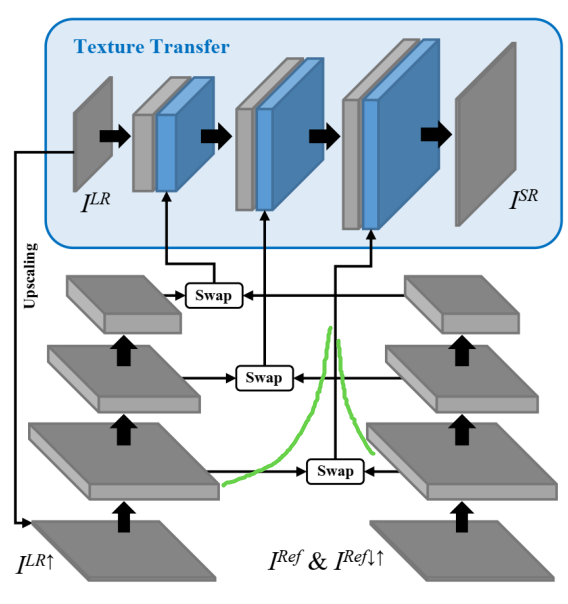
一些相似方法的对比:
Implementation of SR algorithms in comparison:
SRCNN, SelfEx, SCN, DRCN, LapSRN, MDSR, ENet, SRGAN, CrossNet,
code:https://github.com/ZZUTK/SRNTT
*****author:https://research.adobe.com/person/zhifei-zhang/ http://web.eecs.utk.edu/~zzhang61/
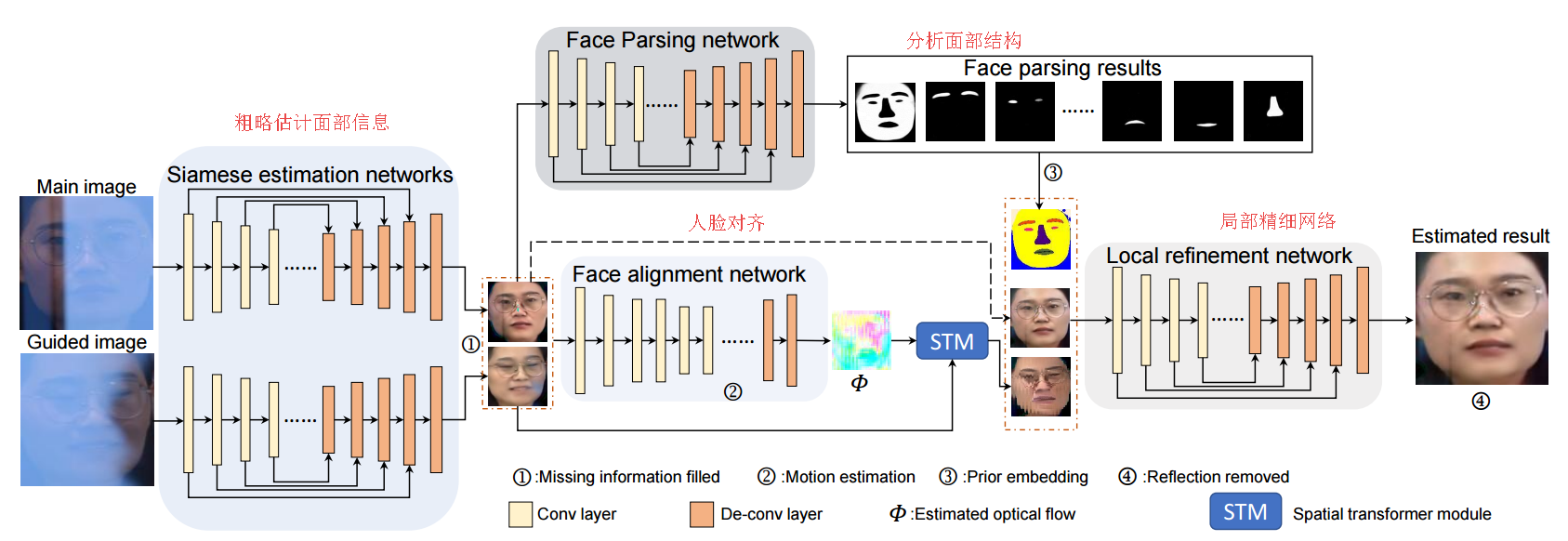
?提出了一种基于图像修复和面部先验的方法,用于移除面部照片中的玻璃反光,研究了透射、反射、非投射式反射等情况下的反射去除。(from 南洋理工)

模型的框架分为四个部分:
研究人员还构建了自己的面部反射数据集:

一些最终的结果:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









