







 该论文探讨了一种使用卷积神经网络(CNN)进行关系分类的方法。通过词嵌入将单词转换为向量,利用CNN提取词汇和句子级别的特征。将这两种特征连接后,输入softmax分类器预测名词对之间的关系。实验表明,这种方法能够有效地自动提取语句特征,提高关系分类的准确性。
该论文探讨了一种使用卷积神经网络(CNN)进行关系分类的方法。通过词嵌入将单词转换为向量,利用CNN提取词汇和句子级别的特征。将这两种特征连接后,输入softmax分类器预测名词对之间的关系。实验表明,这种方法能够有效地自动提取语句特征,提高关系分类的准确性。
核心: 用卷积神经网络提取词语和语句级别的特征,将所有的单词标注作为输入(无预处理操作)。通过word embedding将单词标记转换为向量,根据给定的名词提取词汇级别的特征,同时使用卷积神经网络学习语句级特征。连接两个级别的特征形成最终特征向量,最后将其输入softmax分类器预测两个标记名词之间的关系。
整体框架: 主要包括三个组件:单词表示,特征提取和输出。(Word
Representation, Feature Extraction and Output)系统的输入是带有两个标记名词的句子。然后,通过查找单词嵌入(word embeddings)将单词标记转换为向量。然后分别提取词法和句子级别特征,然后直接连接以形成最终特征向量。最后,为了计算每个关系的置信度,将特征向量馈送到softmax分类器中,分类器的输出是向量,其维度等于预定义关系类型的数量,每个维度的值是对应关系的置信度得分。
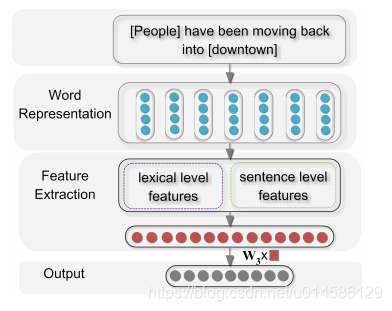
单词表示: 通过查找单词嵌入将每个输入单词标记变换为向量。
词汇级别特征: 本文使用通用字嵌入(generic word embeddings)作为基本特征的来源,选择标记名词的嵌入和上下文标记。

语句级别特征: 使用最大池卷积神经网络以提供语句级别表示并自动提取语句级别的特征。 下图显示了提取语句级别特征的框架。
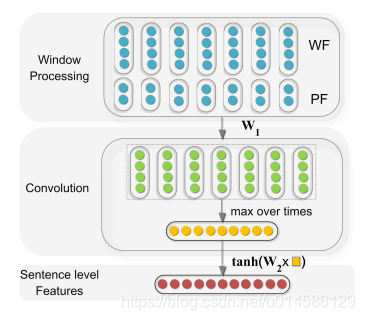
单词特征: 在相同语境中出现的单词往往具有相似含义,因此将单词的矢量表示和单词的矢量表示结合在其上下文中。
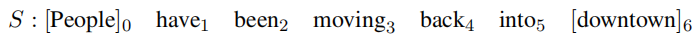
标记的名词与标签 yyy 相关联,标签 yyy 定义标记的对包含的关系类型。每个单词与单词嵌入的索引相关联。 然后将句子 SSS 的所有单词标记表示为向量列表(x0,x1,...,x6)(x_{0},x_{1},...,x_{6})(x0,x1,...,x6),其中xix_{i}xi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









