







SpringBoot启动流程
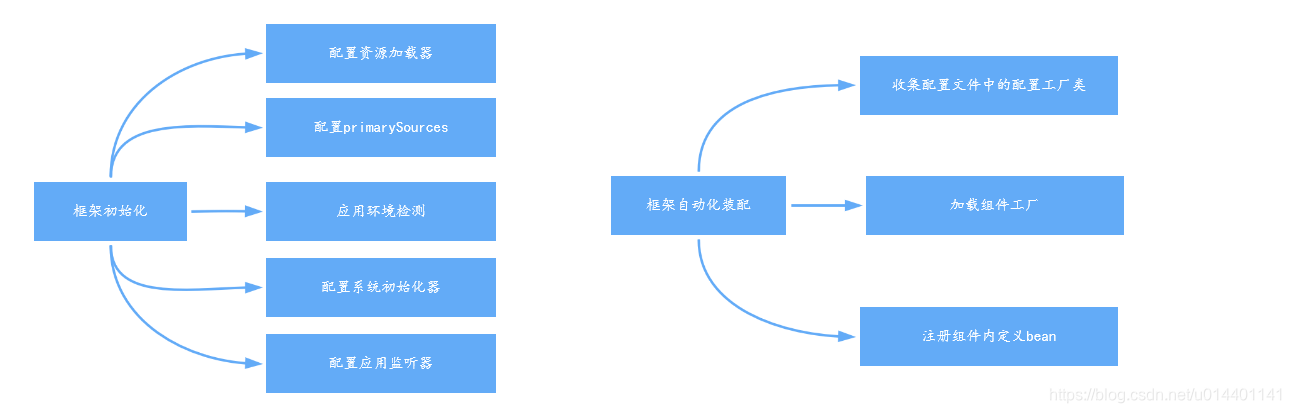
框架的初始化
框架的启动
自动化装配
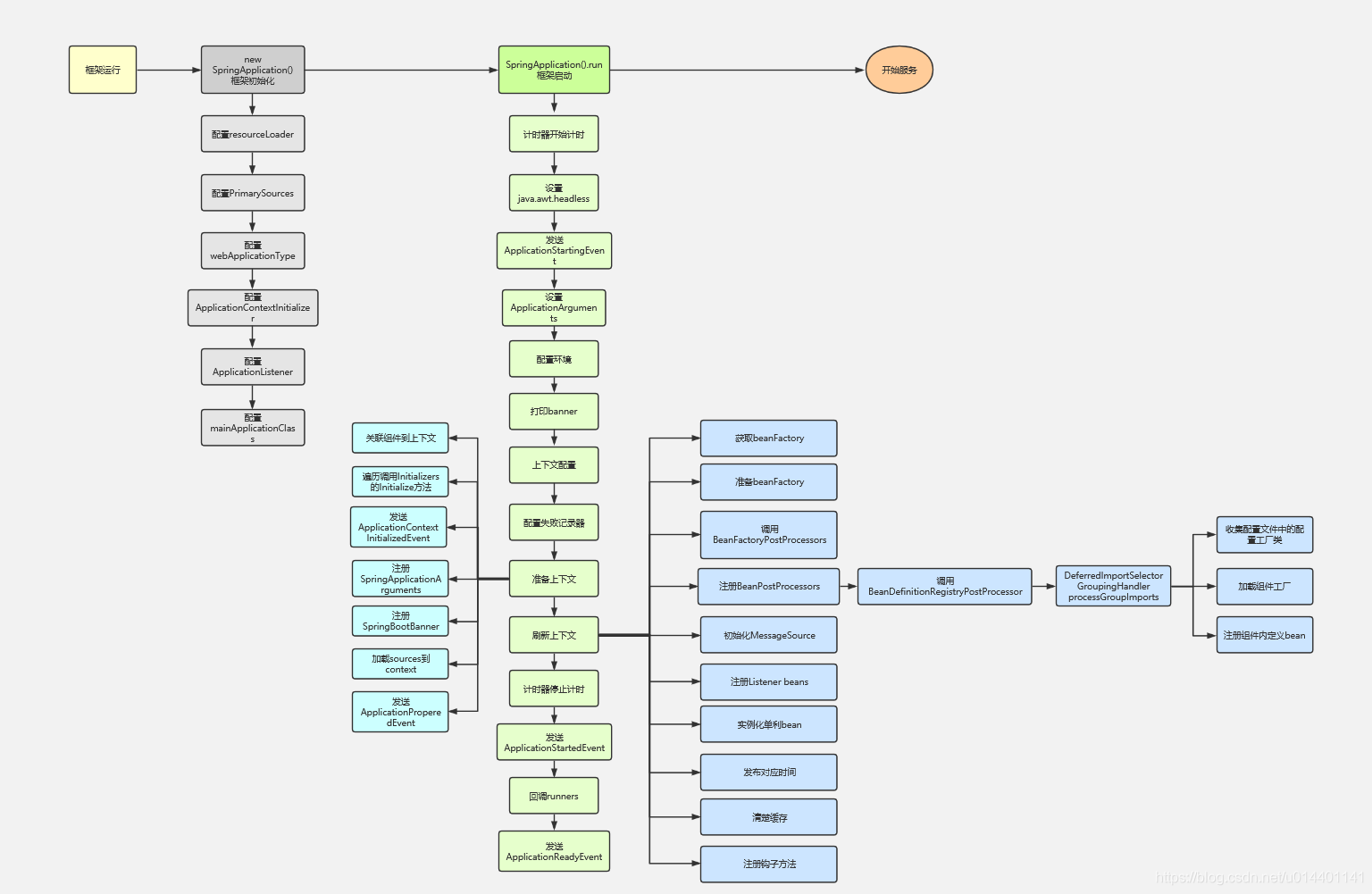
入口
SpringApplication.run(CoreFacadeApplication.class, args);然后调用
public static ConfigurableApplicationContext run(Class<?>[] primarySources, String[] args) {
return new SpringApplication(primarySources).run(args);
}初始化SpringApplication
public SpringApplication(ResourceLoader resourceLoader, Class<?>... primarySources) {
//1.配置resourceLoader
this.resourceLoader = resourceLoader;
Assert.notNull(primarySources, "PrimarySources must not be null");
//2.配置PrimarySources
this.primarySources = new LinkedHashSet<>(Arrays.asList(primarySources));
//3.配置webApplicationType
this.webApplicationType = org.springframework.boot.WebApplicationType.deduceFromClasspath();
//4.配置ApplicationContextInitializer,初始化实例
//从类路径下找到META-INF/spring.factories配置的所有ApplicationContextInitializer
setInitializers((Collection) getSpringFactoriesInstances(ApplicationContextInitializer.class));
//5.从类路径下找到ETA-INF/spring.factories配置的所有ApplicationListener,到容器里
setListeners((Collection) getSpringFactoriesInstances(ApplicationListener.class));
//6.配置mainApplicationClass,从多个配置类中找到有main方法的主配置类
//在进行main方法的推断时,主要使用了堆栈信息一层层的判断,来获得main方法
//基本流程就是创建一个运行时异常,然后获得堆栈数组,遍历StackTraceElement数组,判断方法名称是否为“mian”,
// 如果过是则通过Class.forName()方法创建Class对象
//这逻辑有点狠
this.mainApplicationClass = deduceMainApplicationClass();
}
框架启动
public ConfigurableApplicationContext run(String... args) {
//1.打印启动时间
StopWatch stopWatch = new StopWatch();
stopWatch.start();
ConfigurableApplicationContext context = null;
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>();
//2.设置java.awt.headless,Headless模式是系统的一种配置模式。在系统可能缺少显示设备、键盘或鼠标这些外设的情况下可以使用该模式。
configureHeadlessProperty();
//3.实例化SpringApplicationRunListener接口实现类//EventPublishingRunListener,设置启动类监听,
//用来在整个启动流程中接收不同执行点事件通知的监听者
SpringApplicationRunListeners listeners = getRunListeners(args);
listeners.starting();
try {
//设置ApplicationArguments
ApplicationArguments applicationArguments = new DefaultApplicationArguments(args);
//配置环境和相关属性
ConfigurableEnvironment environment = prepareEnvironment(listeners, applicationArguments);
configureIgnoreBeanInfo(environment);
//打印banner
Banner printedBanner = printBanner(environment);
//根据环境获取应用上下文类
context = createApplicationContext();
//实例化异常处理器, //org.springframework.boot.SpringBootExceptionReporter=\
//org.springframework.boot.diagnostics.FailureAnalyzers
exceptionReporters = getSpringFactoriesInstances(SpringBootExceptionReporter.class,
new Class[] { ConfigurableApplicationContext.class }, context);
//准备上下文
prepareContext(context, environment, listeners, applicationArguments, printedBanner);
//刷新上下文
refreshContext(context);
afterRefresh(context, applicationArguments);
stopWatch.stop();
if (this.logStartupInfo) {
new StartupInfoLogger(this.mainApplicationClass).logStarted(getApplicationLog(), stopWatch);
}
//执行EventPublishingRunListner中的started方法
listeners.started(context);
//回调runners
callRunners(context, applicationArguments);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, listeners);
throw new IllegalStateException(ex);
}
try {
//发送ApplicationReadyEvent
listeners.running(context);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, null);
throw new IllegalStateException(ex);
}
return context;
}

















 3752
3752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









