







在现在的大模型时代,核心还得是Transformer,Transformer是由谷歌于2017年提出,最初用于机器翻译的神经网络模型,在此衍生出了一系列的模型,BERT、T5、GPT、GLM、BLOOM、LLaMa等等从小模型到大模型都少不了他。Transformer最经典的模型结构图还得是论文中原汁原味的图
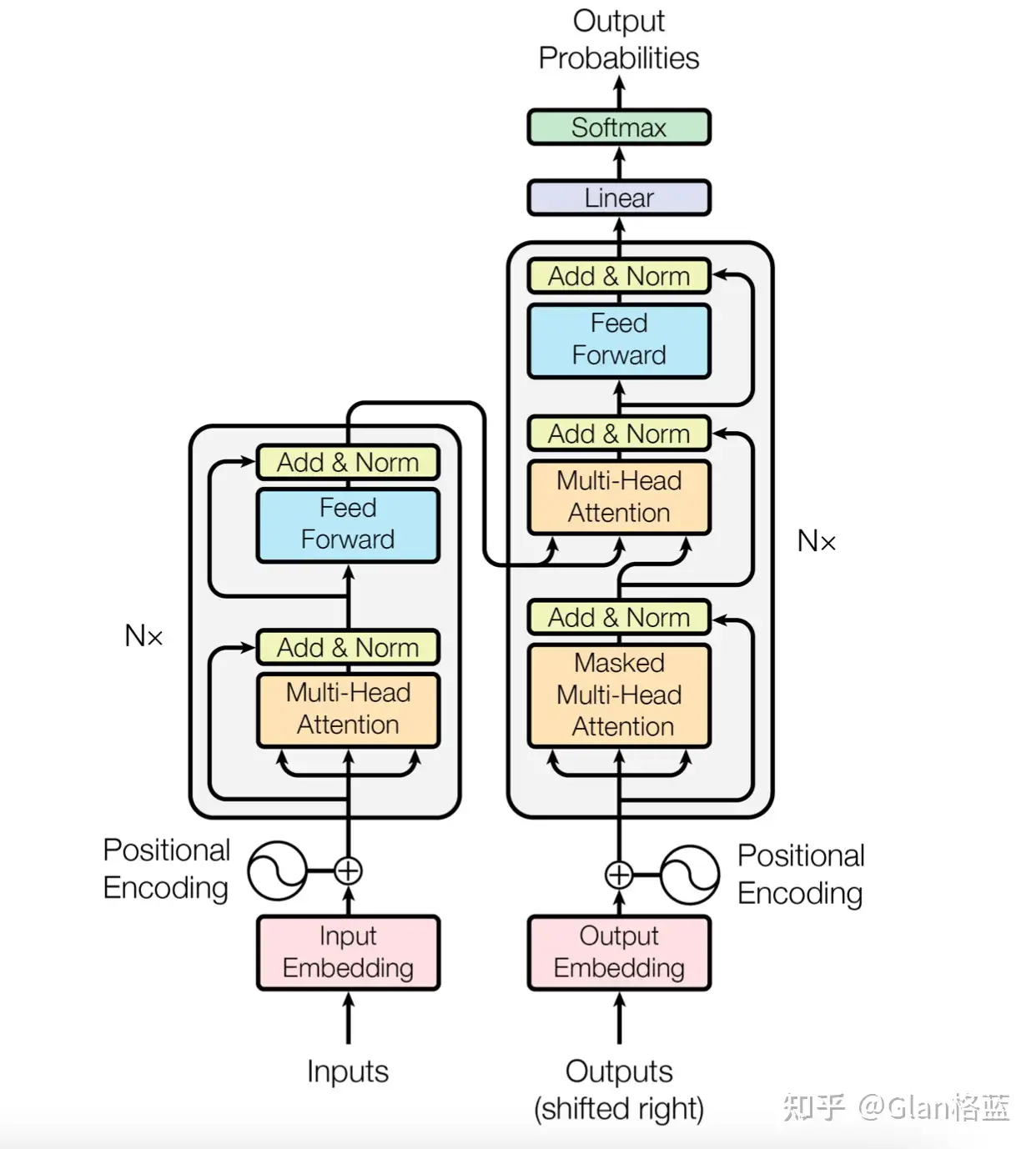
关于这张图的讲解在其他的回答中有很多,简单总结下,左边是编码器(Encoder),右边是解码器(Decoder),N× 表示进行了 N 次堆叠。主要可分成以下几个模块:
- 嵌入表示层(图中粉红Input Embedding和白色小圈Positional Encoding部分);
- 注意力层(图中淡黄Attention部分);
- 前馈层(图中淡蓝Feed Forward部分);
- 残差连接和层归一化(图中黄色Add&Norm部分);
接下来分别对每个模块进行简述以及代码实现。
嵌入表示层
主要由两部分组成即Embedding层和位置编码层。先看下Embedding层的实现,Embedding层的主要作用就是将文本序列通过分词器(tokenizer)分出的token,转换为其相对应的向量表示。假设:“我喜欢”,分为"我|喜欢",对应的token索引是[13,156],然后通过Embedding层转换成对应的向量,有一篇专门讲tokenization的文章详见:https://www.zhihu.com/question/64984731/answer/3183726323
下面是Embedding层的代码实现:
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math, copy, time
class TokenEmbedding(nn.Embedding):
"""
使用torch.nn的Embedding模块
"""
def __init__(self, vocab_size, d_model):
"""
TokenEmbedding类
:param vocab_size: 词汇表的大小
:param d_model: 模型的维度
:padding的索引为1,即token索引为1时,Embedding补0
"""
super(TokenEmbedding, self).__init__(vocab_size, d_model, padding_idx=1)
看一下参数,假设词汇表大小为1000,模型维度是512,则Embedding层的参数如下:
tok_emb = TokenEmbedding(1000, 512)
num_params = sum(p.numel() for p in tok_emb.parameters())
print("模块中的参数数量为:", num_params)
模块中的参数数量为: 512000
测试一下能否够正常使用:
# x是batch_size为2, seq_len为3,索引为1的会被padding为0
x = torch.LongTensor([[6, 5, 4], [3, 2, 1]])
res = tok_emb(x)
print("res:", res)
print("res.shape:", res.shape)
res: tensor([[[-0.3398, 0.6714, 0.5205, ..., 2.0852, -0.2745, -3.4193],
[ 0.9891, 1.1674, -0.0548, ..., -0.1365, -0.6469, -0.1807],
[ 0.4388, -0.3126, -0.8564, ..., -1.1363, -2.1417, 1.0565]],
[[ 1.8572, 0.5508, 1.3253, ..., -0.1493, -0.3859, -0.9570],
[ 0.4711, 0.1042, 1.3682, ..., -1.3991, -0.1269, -0.9717],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]],
grad_fn=<EmbeddingBackward0>)
res.shape: torch.Size([2, 3, 512])
接下来看位置编码层,如果只有Embedding层是不能让模型知道token之间的相对位置关系的,所以在进入编码器建模其上下文语义之前,编码其相对位置信息是一个很重要的操作,Transformer使用的是正余弦函数来编码其位置信息,目前大模型时代使用最多的是苏神的旋转位置编码(RoPE),在此不多赘述了。
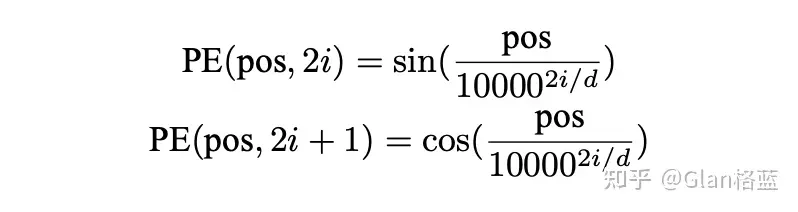
上图中pos 表示单词所在的位置,2i 和 2i + 1 表示位置编码向量中的对应维度,d 则对应位置编码的总维度。这种位置编码有两个优点:1.第 pos + n 个位置的编码是第 pos 个位置的编码的线性组合,包含了相对位置信息;2.正余弦函数的范围是在 [-1,+1],相加后的总嵌入改变不会太大。下面是位置编码层代码实现:
class PositionalEncoding(nn.Module):
"""
计算正余弦位置编码。
"""
def __init__(self, d_model, max_len):
"""
正余弦位置编码类
:param d_model: 模型的维度
:param max_len: 最大序列长度
"""
super(PositionalEncoding, self).__init__()
# 初始化位置编码矩阵
self.encoding = torch.zeros(max_len, d_model)
self.encoding.requires_grad = False # 不需要计算梯度
pos = torch.arange(0, max_len)
pos = pos.float().unsqueeze(dim=1)
# 'i'表示d_model的索引(例如,嵌入大小=50,'i' = [0,50])
# “step=2”表示将'i'乘以二(与2 * i相同)
_2i = torch.arange(0, d_model, step=2).float()
self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / d_model)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / d_model)))
def forward(self, x):
# self.encoding
# [max_len = 512, d_model = 512]
batch_size, seq_len = x.size()
# [batch_size = 8, seq_len = 30]
return self.encoding[:seq_len, :]
# [seq_len = 30, d_model = 512]
# 将与 tok_emb 相加:[8, 30, 512]
看一下参数,假设最大序列长度为512,模型维度也是512,则位置编码层的参数如下:
pe = PositionalEncoding(512,512)
num_params = sum(p.numel() for p in pe.parameters())
print("模块中的参数数量为:", num_params)
模块中的参数数量为: 0
会发现结果结果打印出来是0,因为这个参数矩阵不需要训练,直接生成的,大小是max_len*d_model = 512*512的一个矩阵。看一下使用,如果对这个位置编码有疑惑可以将函数中每一步的中间结果打印出来更容易理解:
# x是batch_size为2, seq_len为3
x = torch.LongTensor([[6, 5, 4], [3, 2, 1]])
res = pe.forward(x)
print("res:", res)
# 返回的形状是[seq_len = 3, d_model = 512]
print("res.shape:", res.shape)
res: tensor([[ 0.0000e+00, 1.0000e+00, 0.0000e+00, ..., 1.0000e+00,
0.0000e+00, 1.0000e+00],
[ 8.4147e-01, 5.4030e-01, 8.2186e-01, ..., 1.0000e+00,
1.0366e-04, 1.0000e+00],
[ 9.0930e-01, -4.1615e-01, 9.3641e-01, ..., 1.0000e+00,
2.0733e-04, 1.0000e+00]])
res.shape: torch.Size([3, 512])
把Embedding层和位置编码层集成在一起即嵌入表示层:
class TransformerEmbedding(nn.Module):
"""
token embedding + positional encoding
"""
def __init__(self, vocab_size, d_model, max_len, drop_prob):
"""
包含Embedding和位置编码的类
:param vocab_size: 词汇表大小
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











