






一、Flume介绍
Apache Flume 是一个分布式、可靠且可用的系统,专门用于高效地从大量数据源(如日志文件、事件流)中收集、聚合和传输数据到集中式的数据存储系统(如 HDFS、HBase、Kafka 等)。它尤其适合处理日志数据的收集和传输,常用于大数据生态系统中。
Flume 的典型应用场景:
・服务器日志的收集:大量服务器产生的日志文件需要统一收集并存储到集中式存储系统 (如 HDFS 或 HBase)。
・实时流数据的传输:将实时产生的事件数据流(如社交媒体、传感器数据)传输到分析系统或数据仓库中。
・大规模数据的采集:当需要从多个数据源(如 Web 服务器、数据库、传感器等)持续采集大量数据时,Flume 可以提供高可用性和容错机制。
Flume 的架构
Flume 的架构基于流式数据处理,它的核心架构由三个主要组件组成:
1、Source(源):
・Source 负责从外部数据源(如日志文件、消息队列、数据库等)获取数据,并将其发送给 Flume 的 Channel。
・常见的 Source 有:
1)Syslog Source:从 Syslog 服务器获取日志数据。
2)Avro Source:从其他 Flume agents 或应用程序接收数据。
3)Exec Source:通过执行 Linux 命令(如 tail -F)获取实时日志。
2、Channel(通道):
・Channel 是临时存储数据的中间组件,它连接了 Source 和 Sink。Source 负责将数据放入 Channel,Sink 负责从 Channel 中取出数据。
・Channel 提供了缓冲区和流量控制功能,确保数据在传输过程中不会丢失或阻塞。
・常见的 Channel 类型:
1)Memory Channel:将数据缓存在内存中,速度快但不具备持久化能力。
2)File Channel:将数据持久化到磁盘,提供持久化能力以防止数据丢失。
3)Kafka Channel:使用 Kafka 作为 Channel,适用于大规模数据流的场景。
3、Sink(汇):
・Sink 负责从 Channel 中取出数据,并将它传输到目标存储系统(如 HDFS、HBase、Kafka 等)。
・常见的 Sink 类型:
1)HDFS Sink:将数据写入 HDFS 文件系统。
2)HBase Sink:将数据写入 HBase 数据库。
3)Kafka Sink:将数据写入 Kafka 消息队列。
4)ElasticSearch Sink:将数据发送到 ElasticSearch,用于日志分析和全文搜索。
Flume 的数据流
Flume 中的数据流是从 Source 开始,经过 Channel,最后到达 Sink。每个数据流可以被称为一个 Flume Agent。可以通过多个 Flume Agent 进行数据的多级传递和处理,即在一个 Flume Agent 的 Sink 输出的数据可以成为另一个 Flume Agent 的 Source 输入,从而实现数据的多跳传输。
Flume 的数据传输保证
Flume 提供三种常见的传输保证机制:
・At Most Once(最多一次):
1)数据可能会丢失,但绝不会重复传输。
2)适用于对数据完整性要求不高的场景。
・At Least Once(至少一次):
1)所有数据都会被传输,但可能会出现重复的数据。
2)适用于需要确保所有数据都被传输的场景(如日志采集),但需要在下游处理去重。
・Exactly Once(精确一次):
1)Flume 本身不提供端到端的精确一次传输保证,但可以通过结合其他系统(例如 Kafka、Hadoop 的 HDFS)来实现这种语义。
Flume 的特点
・可伸缩性强:Flume 可以轻松地扩展,支持多个 Flume Agent 进行数据的多级传输和处理,适用于大规模数据收集场景。
・可靠性高:Flume 支持多种 Channel 类型(如 Memory、File),可以根据需求选择不同的 Channel 实现不同的可靠性保证。
・灵活的配置方式:Flume 提供了灵活的配置文件方式,用户可以轻松定义 Source、Channel 和 Sink 的组合,适用于多种数据采集和传输场景。
・多种事件处理机制:Flume 支持事件聚合、数据压缩、加密等功能,满足不同应用场景对数据流处理的需求。
・容错和高可用性:Flume 支持多种容错机制,可以通过配置多个 Channel 和 Sink 来实现数据的冗余传输,防止数据丢失。
二、Flume安装
下载flume安装包,官方地址:Download — Apache Flume
安装包上传至Linux服务器,指定目录执行以下命令进行解压(作者目录:/usr/local/flume):
tar -zxvf apache-flume-1.11.0-bin.tar.gz解压成功后执行以下命令进行文件名称修改(看个人喜好):
mv apache-flume-1.11.0-bin flume-1.11进入flume目录,创建配置文件:
cd /usr/local/flume/flume-1.11.0/confvim flume-kafka.conf复制以下内容至flume-kafka.conf配置文件中:
# flume-kafka.conf: A Flume configuration file with a Kafka sink
# Name the components on this agent
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure the source
agent1.sources.source1.type = exec
#监听服务器80端口
agengt.sources.source1.port=80
#读取/var/log/nginx目录下的access.log日志
agent1.sources.source1.command = tail -F /var/log/nginx/access.log
agent1.sources.source1.batchSize = 100
agent1.sources.source1.interceptors = timestamp_interceptor
agent1.sources.source1.interceptors.timestamp_interceptor.type = timestamp
# Describe/configure the sink
agent1.sinks.sink1.type = org.apache.flume.sink.kafka.KafkaSink
#kafka的Topic
agent1.sinks.sink1.topic = testTopic
#kafka地址+端口
agent1.sinks.sink1.brokerList = 127.0.0.1:9092
# Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
agent1.channels.channel1.capacity = 1000
agent1.channels.channel1.transactionCapacity = 100
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1守护进程方式执行以下内容启动flume:
nohup /usr/local/flume/flume-1.11.0/bin/flume-ng agent --conf /usr/local/flume/flume-1.11.0/conf --conf-file /usr/local/flume/flume-1.11.0/conf/flume-kafka.conf --name agent1 -Dflume.root.logger=INFO,consol &三、测试
SpringBoot工程引入kafka依赖:
<!--kafka依赖-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.8.6</version>
</dependency>application.yml配置:
server:
port: 8081
spring:
application:
name: demo
kafka:
bootstrap-servers: 127.0.0.1:9092
producer:
batch-size: 16384 #批次大小,默认16k
acks: -1 #ACK应答级别,指定分区中必须要有多少个副本收到消息之后才会认为消息成功写入,默认为1只要分区的leader副本成功写入消息;0表示不需要等待任何服务端响应;-1或all需要等待ISR中所有副本都成功写入消息
retries: 3 #重试次数
value-serializer: org.apache.kafka.common.serialization.StringSerializer #序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
buffer-memory: 33554432 #缓冲区大小,默认32M
client-id: kafka.producer.client.id #客户端ID
compression-type: none #消息压缩方式,默认为none,另外有gzip、snappy、lz4
properties:
retry.backoff.ms: 100 #重试时间间隔,默认100
linger.ms: 0 #默认为0,表示批量发送消息之前等待更多消息加入batch的时间
max.request.size: 1048576 #默认1MB,表示发送消息最大值
connections.max.idle.ms: 540000 #默认9分钟,表示多久后关闭限制的连接
receive.buffer.bytes: 32768 #默认32KB,表示socket接收消息缓冲区的大小,为-1时使用操作系统默认值
send.buffer.bytes: 131072 #默认128KB,表示socket发送消息缓冲区大小,为-1时使用操作系统默认值
request.timeout.ms: 30000 #默认30000ms,表示等待请求响应的最长时间
consumer:
auto-commit-interval: 5000 #自动提交消费位移时间隔时间
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
max-poll-records: 500 #批量消费每次最多消费多少条消息
enable-auto-commit: false #开启手动提交消费位移
auto-offset-reset: latest #其他earliest、none
group-id: kafka.consumer.group #消费者组名称
client-id: kafka.consumer.client.id #消费者客户端ID
fetch-max-wait: 400 #最大等待时间
fetch-min-size: 1 #最小消费字节数
heartbeat-interval: 3000 #分组管理时心跳到消费者协调器之间的预计时间
isolation-level: read_committed
listener: # 配置监听容器的ackmode
concurrency: 5
ack-mode: manual_immediate
missing-topics-fatal: false
创建Listener类,实现Kafka消息监听:
package com.example.demo;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import java.util.Optional;
@Slf4j
@Component
public class Listener {
/**
* 监听消息
*/
@KafkaListener(topics = {"testTopic"}, groupId = "group1")
public void kafkaListener(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
log.info("topic.group1 消费了: Topic:" + topic + ",Message:" + msg);
ack.acknowledge();
}
}
}
Postman请求访问服务器的80端口(需开放80端口),主要是让Linux服务器产生access.log日志,Flume监听的是access.log日志,并将日志的内容推送到kafka。这样我们的监听程序才能消费消息。
启动SpringBoot工程,以下是监听的消息内容:
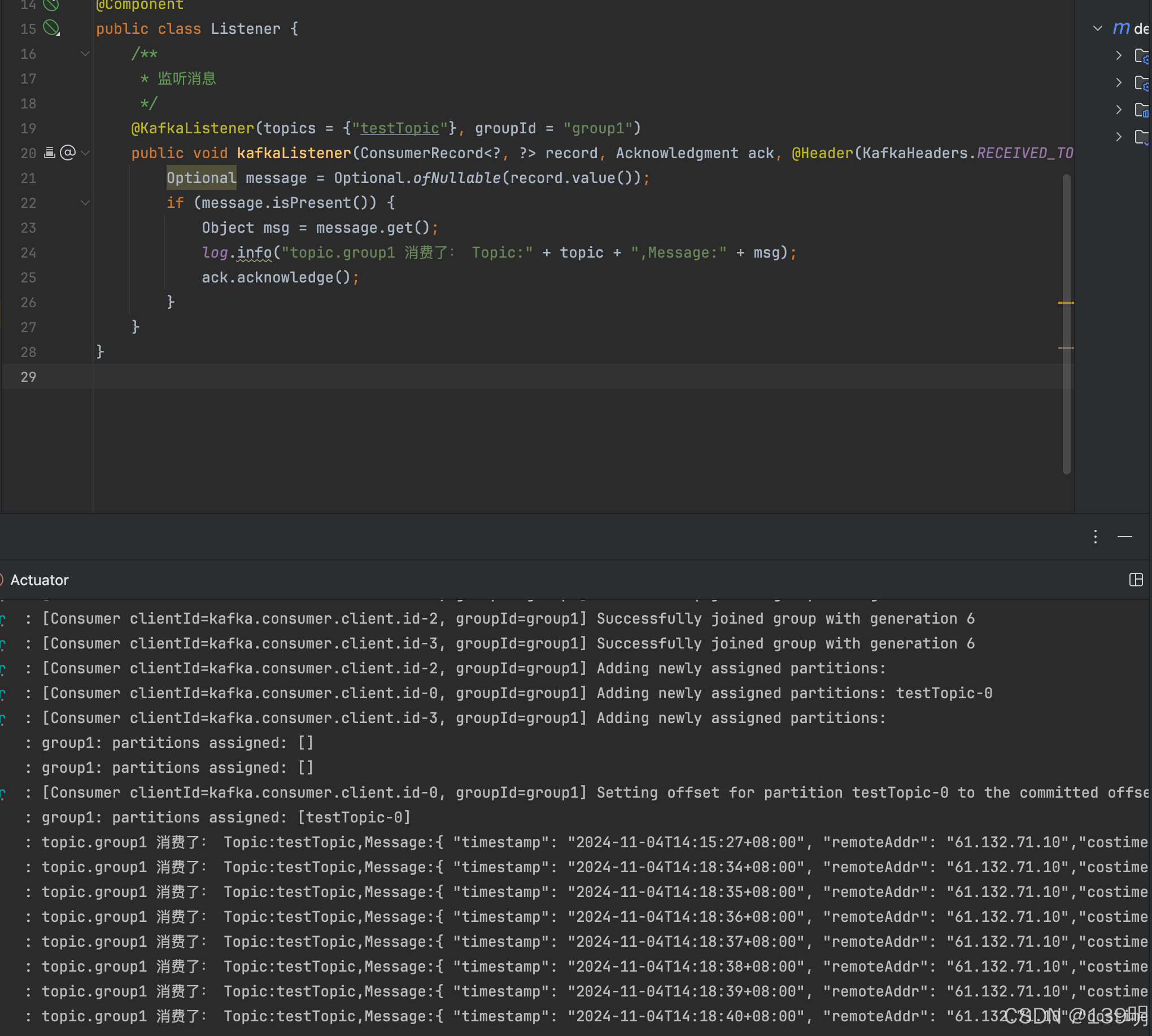
Nginx默认配置的access.log并不会打印Post请求的参数信息,需要自己定制化配置。相关的资料请参考文档:Nginx设置日志打印请求参数_nginx 日志 输出请求参数和响应-优快云博客
定制化想要的Nginx日志后,需要修改上述对应的flume-kafka.conf的内容,使用以下命令查询Flume进程,并删除对应的进程,重启。
查询命令:
ps -ef|grep flume查询结果:

删除命令:
kill -9 2167371Flink读取Kafka 消息并批量写入到 MySQL8.0源码地址:flink-kafka-mysql: Flink读取Kafka 消息并批量写入到 MySQL8.0

















 1654
1654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









