







1 Python中的编码
python对多国语言的处理是支持的很好的,它可以处理现在任意编码的字符,这里深入的研究一下python对多种不同语言的处理。
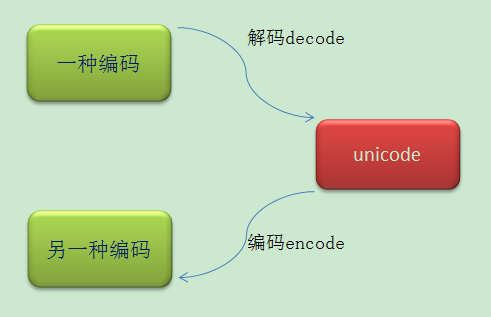
有一点需要清楚的是,当python要做编码转换的时候,会借助于内部的编码,转换过程请参考上图。
Unicode编码有两种,一种是UCS-2,用两个字节编码,共65536个码位;另一种是UCS-4,用4个字节编码,共2147483648个码位。
python都是支持的,这个是在编译时通过--enable- unicode=ucs2或--enable-unicode=ucs4来指定的。那么我们自己默认安装的python有的什么编码怎么来确定呢?有一个 办法,就是通过sys.maxunicode的值来判断:
import sys
print sys.maxunicode
如果输出的值为65535,那么就是UCS-2,如果输出是1114111就是UCS-4编码。
import sys
# python idle 的默认编码方式
sys.getdefaultencoding()
我们要认识到一点:当一个字符串转换为内部编码后,它就不是str类型了!它是unicode类型
a = " 风卷残云 "
print type(a)
b = unicode(a,‘gb2312')
print type(b)
运行结果:
<type 'str'>
<type 'unicode'>
2 Codecs编解码
# -*- encoding: gb2312 -*-
import codecs, sys
print ' - ' * 60
# 创建gb2312编码器
look = codecs.lookup( " gb2312 " )
# 创建utf-8编码器
look2 = codecs.lookup( " utf-8 " )
a = " 我爱北京 "
print len(a), a
# 把a编码为内部的unicode, 但为什么方法名为decode呢,我的理解是把gb2312的字符串解码为unicode
b = look.decode(a)
# 返回的b[0]是数据,b[1]是长度,这个时候的类型是unicode了
print b[ 1 ], b[0], type(b[0])
# 把内部编码的unicode转换为gb2312编码的字符串,encode方法会返回一个字符串类型
b2 = look.encode(b[0])
# 发现不一样的地方了吧?转换回来之后,字符串长度由14变为了7! 现在的返回的长度才是真正的字数,原来的是字节数
print b2[ 1 ], b2[0], type(b2[0])
# 虽然上面返回了字数,但并不意味着用len求b2[0]的长度就是7了,仍然还是14,仅仅是codecs.encode会统计字数
print len(b2[0])
3 Codec的简单使用--IO
读写文件是最常见的IO操作。Python内置了读写文件的函数,用法和C是兼容的。
读文件
打开一个文件,读取后应该close(),为了保证无论是否出错都能正确地关闭文件,我们可以使用try ... finally来实现:
[python] view plain copy print?![]()
![]()
- try:
- f = open('/path/to/file', 'r')
- print f.read()
- finally:
- if f:
- f.close()
Python引入了with语句来自动帮我们调用close()方法:
[python] view plain copy print?![]()
![]()
- <pre name="code" class="python">with open('/path/to/file', 'r') as f:
- print f.read()
这和前面的try ... finally是一样的,但是代码更佳简洁,并且不必调用f.close()方法。调用read()方法可以一次读取文件的全部内容,Python把内容读到内存,用一个str对象表示
读大文件时,建议下面的方式:
[python] view plain copy print?![]()
![]()
- with open('/path/to/file', 'r') as f:
- for line in f:
- print line
这种迭代的方式不会一次性的把大文件都读入内存。
二进制文件
前面讲的默认都是读取文本文件,并且是ASCII编码的文本文件。要读取二进制文件,比如图片、视频等等,用'rb'模式打开文件即可。
[python] view plain copy print?![]()
![]()
- >>> f = open('/Users/michael/test.jpg', 'rb')
- >>> f.read()
- '\xff\xd8\xff\xe1\x00\x18Exif\x00\x00...' # 十六进制表示的字节
字符编码
要读取非ASCII编码的文本文件,就必须以二进制模式打开,再解码。比如GBK编码的文件:
[python] view plain copy print?![]()
![]()
- >>> f = open('/Users/michael/gbk.txt', 'rb')
- >>> u = f.read().decode('gbk')
- >>> u
- u'\u6d4b\u8bd5'
- >>> print u
- 测试
如果每次都这么手动转换编码嫌麻烦(写程序怕麻烦是好事,不怕麻烦就会写出又长又难懂又没法维护的代码),Python还提供了一个codecs模块帮我们在读文件时自动转换编码,直接读出unicode:
[python] view plain copy print?![]()
![]()
- import codecs
- with codecs.open('/Users/michael/gbk.txt', 'r', 'gbk') as f:
- f.read() # u'\u6d4b\u8bd5'
以gbk编码打开文件/Users/michael/gbk.txt,读取后直接自动转换成python内部的unicode编码。
写文件写文件和读文件是一样的,唯一区别是调用open()函数时,传入标识符'w'或者'wb'表示写文本文件或写二进制文件:
[python] view plain copy print?![]()
![]()
- >>> f = open('/Users/michael/test.txt', 'w')
- >>> f.write('Hello, world!')
- >>> f.close()
你可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件。当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险:
[python] view plain copy print?![]()
![]()
- with open('/Users/michael/test.txt', 'w') as f:
- f.write('Hello, world!')
要写入特定编码的文本文件,请效仿codecs的示例,在open()指定以什么编码打开文件,在写入时将待写入内容先解码成unicode,既(str.decode("unicode_escape")),那么在write()时,codecs就会自动将内容转换成指定编码写入文件。
读写文件是最常见的IO操作。Python内置了读写文件的函数,用法和C是兼容的。
读文件
打开一个文件,读取后应该close(),为了保证无论是否出错都能正确地关闭文件,我们可以使用try ... finally来实现:
[python] view plain copy print?![]()
![]()
- try:
- f = open('/path/to/file', 'r')
- print f.read()
- finally:
- if f:
- f.close()

Python引入了with语句来自动帮我们调用close()方法:
[python] view plain copy print?![]()
![]()
- <pre name="code" class="python">with open('/path/to/file', 'r') as f:
- print f.read()
这和前面的try ... finally是一样的,但是代码更佳简洁,并且不必调用f.close()方法。调用read()方法可以一次读取文件的全部内容,Python把内容读到内存,用一个str对象表示
读大文件时,建议下面的方式:
[python] view plain copy print?![]()
![]()
- with open('/path/to/file', 'r') as f:
- for line in f:
- print line
这种迭代的方式不会一次性的把大文件都读入内存。
二进制文件
前面讲的默认都是读取文本文件,并且是ASCII编码的文本文件。要读取二进制文件,比如图片、视频等等,用'rb'模式打开文件即可。
[python] view plain copy print?![]()
![]()
- >>> f = open('/Users/michael/test.jpg', 'rb')
- >>> f.read()
- '\xff\xd8\xff\xe1\x00\x18Exif\x00\x00...' # 十六进制表示的字节
字符编码
要读取非ASCII编码的文本文件,就必须以二进制模式打开,再解码。比如GBK编码的文件:
[python] view plain copy print?![]()
![]()
- >>> f = open('/Users/michael/gbk.txt', 'rb')
- >>> u = f.read().decode('gbk')
- >>> u
- u'\u6d4b\u8bd5'
- >>> print u
- 测试
如果每次都这么手动转换编码嫌麻烦(写程序怕麻烦是好事,不怕麻烦就会写出又长又难懂又没法维护的代码),Python还提供了一个codecs模块帮我们在读文件时自动转换编码,直接读出unicode:
[python] view plain copy print?![]()
![]()
- import codecs
- with codecs.open('/Users/michael/gbk.txt', 'r', 'gbk') as f:
- f.read() # u'\u6d4b\u8bd5'
以gbk编码打开文件/Users/michael/gbk.txt,读取后直接自动转换成python内部的unicode编码。
写文件
写文件和读文件是一样的,唯一区别是调用open()函数时,传入标识符'w'或者'wb'表示写文本文件或写二进制文件:
[python] view plain copy print?![]()
![]()
- >>> f = open('/Users/michael/test.txt', 'w')
- >>> f.write('Hello, world!')
- >>> f.close()
你可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件。当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险:
[python] view plain copy print?![]()
![]()
- with open('/Users/michael/test.txt', 'w') as f:
- f.write('Hello, world!')

要写入特定编码的文本文件,请效仿codecs的示例,在open()指定以什么编码打开文件,在写入时将待写入内容先解码成unicode,既(str.decode("unicode_escape")),那么在write()时,codecs就会自动将内容转换成指定编码写入文件。


















 2673
2673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











