







 本文介绍了机器翻译的传统方法,包括使用RNN进行编码和解码,并探讨了在对话系统中如何利用双encoder处理上下文。重点讲解了注意力机制,它允许解码器聚焦于源文本的特定部分,提高翻译质量。通过匹配规则确定重要信息的权重,从而影响解码器的输入。
本文介绍了机器翻译的传统方法,包括使用RNN进行编码和解码,并探讨了在对话系统中如何利用双encoder处理上下文。重点讲解了注意力机制,它允许解码器聚焦于源文本的特定部分,提高翻译质量。通过匹配规则确定重要信息的权重,从而影响解码器的输入。
我们以机器翻译为例。“机器学习”->“machine learning”
传统的做法是这样的:
我们先用RNN对“机器学习”进行编码(encoder),即把最后一个隐藏层的输出拿出来,作为输入丢进RNN生成器里面进行解码(decoder)。为了防止初始编码的影响力减弱,可以对每一个时间步都将初始编码作为一个输入。编码器和解码器是放在一起训练的。他们的参数可以是一样的,也可以是不一样的。
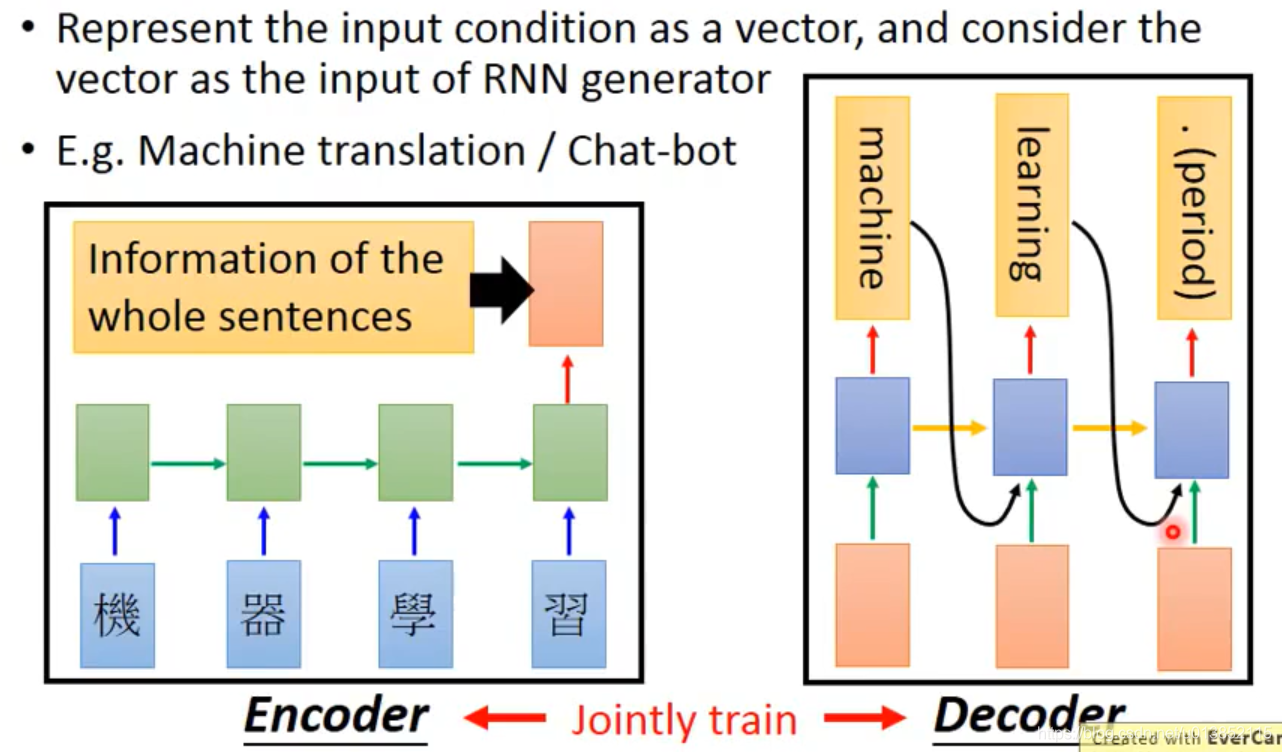
在做聊天机器人的时候,我们通常要考虑之前说过的句子。这时我们可以使用两个encoder。第一个encoder编码之前说过的所有句子,第二个encoder编码当前对方说的句子,将两个编码合成一个编码,输入到解码器里面。
Attention-based model
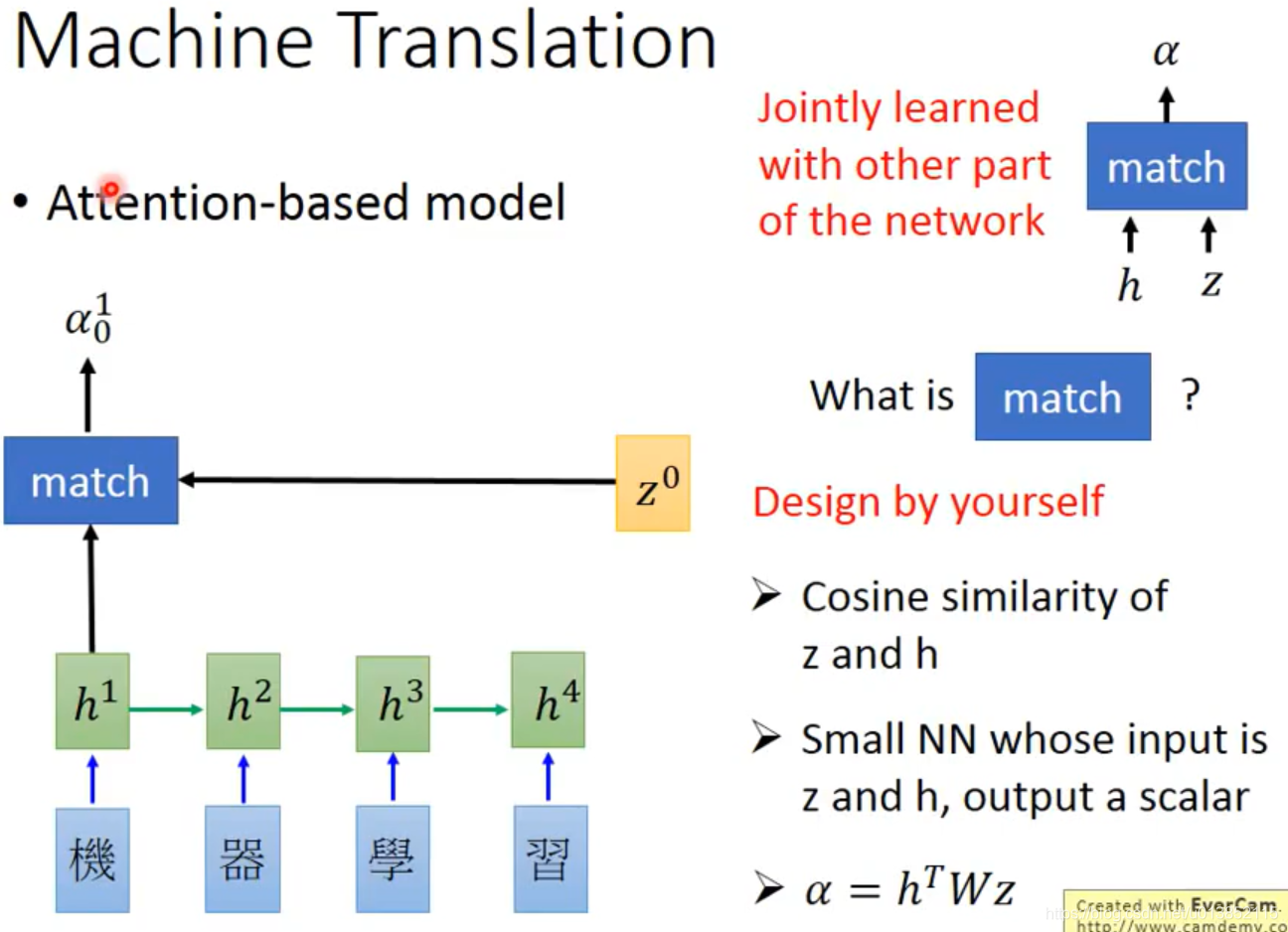
注意力机制可以使解码器重点关注一些重要的信息。
当我们翻译第一个单词“machine”的时候,我们希望解码器关注“机器”两个字。我们引入一个值z(z的取值是解码器中上一个时间步隐藏层的输出,初始的z0要自定义一个值)。使用这个值z对编码器中每个时间步隐藏层的输出h(i)进行匹配,匹配的规则需要自己定义。可以是h和z的余弦相似度,也可以是一个小型的神经网络,输入h和z,输出一个匹配度的值。
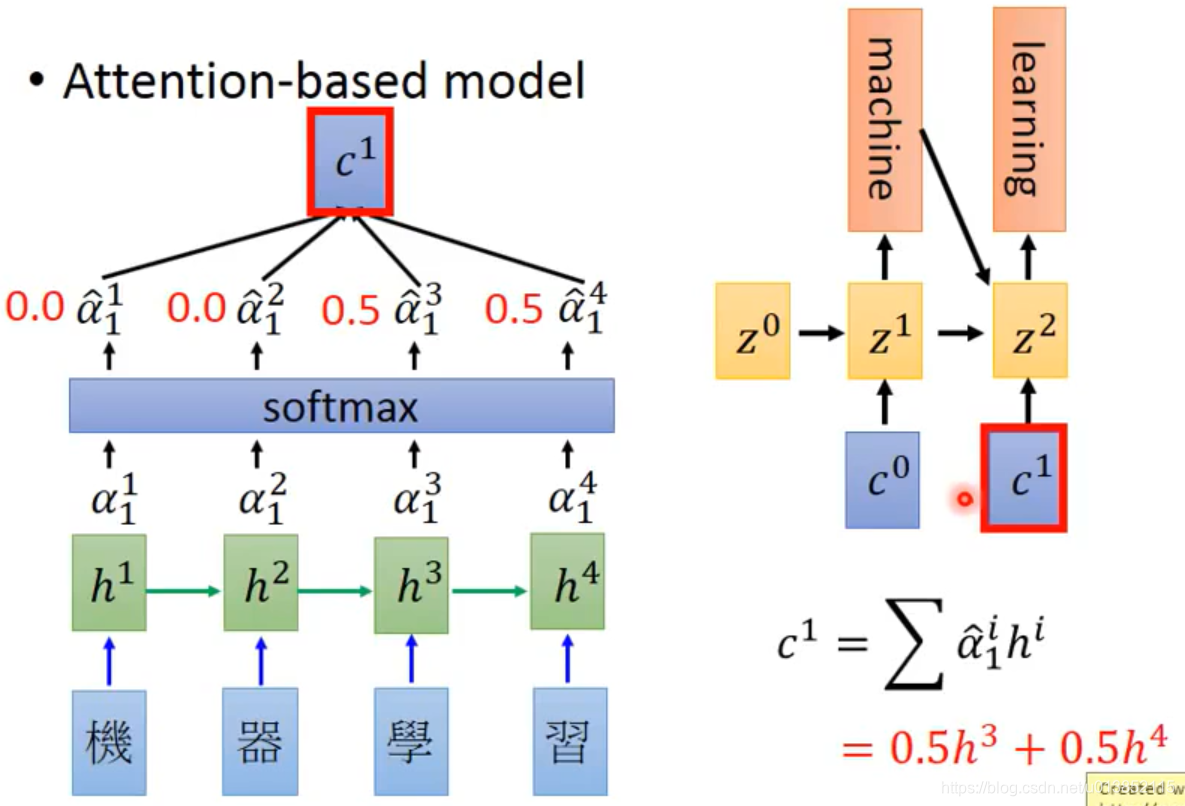
这样会输出4个值,每一个
乘上对应的h(这里的
可以理解为h的权重,即影响力),再求和,就得到了解码器第一个时间步的输入c0。
![]()
可以不加softmax层。

















 2056
2056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









