







视频自监督一. STCR: 一个基于数据增强的简单有效正则项 (降低静态信息的影响)
Self-supervised learning using consistency regularization of spatio-temporal data augmentation for action recognition, https://arxiv.org/pdf/2008.02086.pdf; code;

1. Overview
本文针对视频自监督任务基于Consistency Regularization设定了一个通用/简单有效的正则项。
2. Motivation
对于Action Recognition这个task, 对比Image, Video包含的额外Temporal information扮演很重要的角色, 进年来如何从无标数据里面学习到temporal信息,从Shuffle&Learn 到 Net。我们观察到现有的模型有两个显著的问题:
(1). 3D CNN在feature encoding 的过程中部分丧失了direction information, eg. 一个强力的强监督模型仍然关于Sit/Stand Up两个动作会有很严重的混淆;
(2). 由于真实的video不可避免的存在显著的implicit bias (比如通过看到水识别游泳,看到马识别骑马), 现有的模型很容易遇到 object 或者 background的影响, 从而损害时序信息的学习, 使得在类似场景或者有同样物体存在的时候泛化性很差。
因此,我们想让模型用自监督的方法去缓解3D Backbone存在的问题。
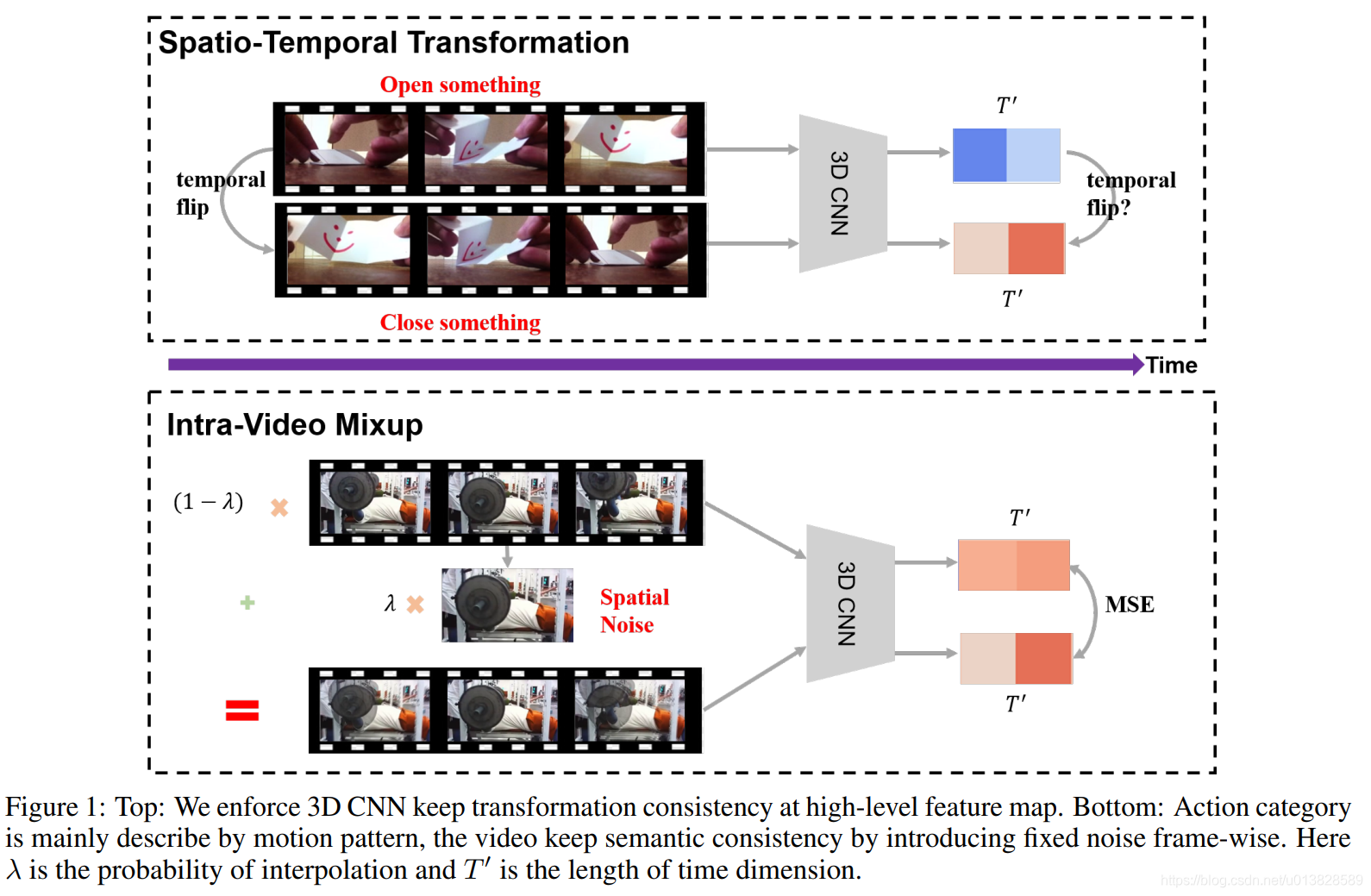
3. 从Consistency Regularization 讲起
Consistency Regularization 是在semi-supervised learning 里面非常典型的方法; 想法是对同一个样本 x x x, 经过不同的 Augmentation之后模型的预测结果应该保持不变;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









