




注:本文为 “操作系统内存管理” 相关合辑。
英文引文,机翻未校。
中文引文,略作重排。
如有内容异常,请看原文。
Memory Management Techniques In Operating System
操作系统中的内存管理
By Sudhanshu Agarwal
May 26, 2020
Memory is the focal piece of the considerable number of operations of a computer system. So in this section, we will learn out about the various kinds of memory management techniques and furthermore the advantages and disadvantages of various memory management techniques. Figure 1 represents to the absolute most pivotal memory management techniques:
内存是计算机系统所有操作的核心组成部分。因此在本节中,我们将介绍各类内存管理技术,同时阐述不同内存管理技术的优缺点。图 1 展示了几种极为关键的内存管理技术:
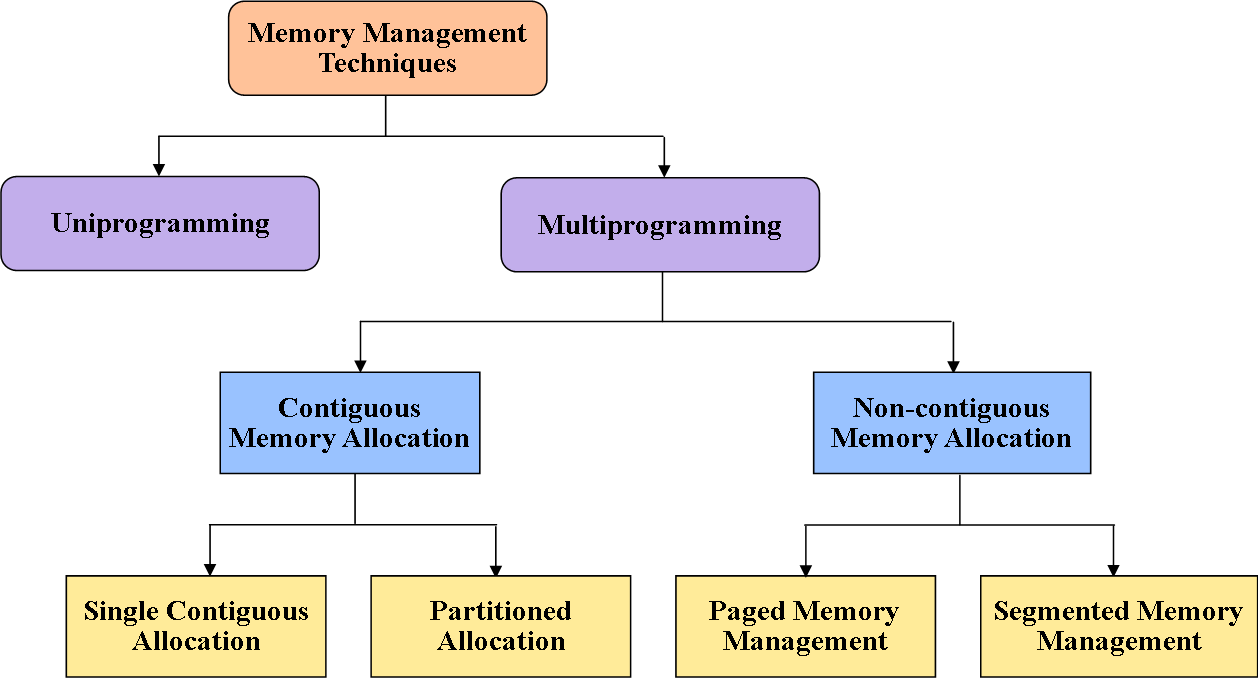
Memory Management Techniques
内存管理技术
Uni-programming memory management:
单道程序内存管理:
In uni-programming technique, the RAM is isolated into two categories where’s one category is for leaving the operating system and the other category is for the client process. Here the fence register is utilized which contains the last address of the parts of operating system. The operating system will contrast the client information addresses and the fence register and in the event that it is distinctive that implies the client isn’t entering the area of the operating system. The fence register is additionally called a limit register and is utilized to keep a client from entering the operating system region. Here the CPU use is poor and thus multiprogramming is utilized.
在单道程序技术中,随机存取存储器(RAM)被划分为两个部分,一部分用于存放操作系统,另一部分用于存放用户进程。该技术会使用界限寄存器,寄存器中存储着操作系统各部分的末地址。操作系统会将用户数据地址与界限寄存器中的地址进行对比,若二者不同,则说明用户未进入 操作系统 的内存区域。界限寄存器也被称为限值寄存器,其作用是防止用户进入操作系统的内存区域。单道程序内存管理方式下的 CPU 利用率较低,因此多道程序技术应运而生。
Multi-programming memory management
多道程序内存管理
In the multi-programming, the various clients can share the memory at the same time. By multiprogramming we mean there will be more than one procedure in the main memory and if the running procedure needs to hang tight for an occasion like input/output then as opposed to sitting on ideal conditions CPU will do a context switch and will pick another procedure.
在多道程序技术中,多个用户可以同时共享内存。多道程序设计指的是主存中同时存在多个进程,当正在运行的进程需要等待输入/输出(I/O)这类事件时,CPU 不会处于空闲状态,而是会执行上下文切换操作,选择另一个进程继续运行。

Types of multiprogramming memory management techniques
多道程序内存管理技术的分类
Contiguous memory allocation
连续内存分配
In the procedure of contiguous memory allocation, all the accessible memory space stays together in one spot. It implies openly accessible memory partitions are not dissipated to a whole extent over the entire memory space.
在连续内存分配机制中,所有可用的内存空间会集中在一个连续的区域。也就是说,空闲的内存分区不会分散在整个内存空间的各处。
In the contiguous memory allocation, both operating system and the client must live in the primary memory. The primary memory is isolated into two segments where’s one segment is for the operations and other is for the client program.
在连续内存分配方式下,操作系统与用户进程都必须驻留在主存中。主存会被划分为两个部分,一部分用于存放操作系统,另一部分用于存放用户程序。
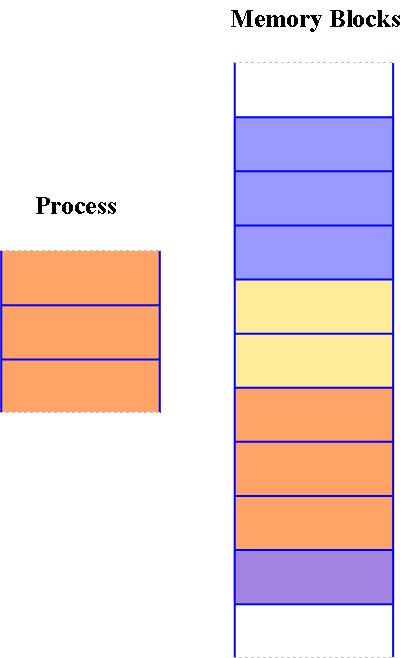
Contiguous Memory Allocation
连续内存分配
In the contiguous memory allocation when any client procedure demands the memory a solitary segment of the contiguous memory block is given to that procedure as indicated by its need. We can accomplish the contiguous memory allocation by separating memory into the fixed-sized partition.
在连续内存分配机制中,当任意用户进程发起内存请求时,系统会根据进程的需求,为其分配一块连续的内存分区。可以通过将内存划分为若干个固定大小分区的方式,实现连续内存分配。
A solitary procedure is distributed in that fixed-sized single partition. Yet, this will build the level of multiprogramming that implies more than one procedure in the principle memory that limits the quantity of fixed partition done in memory. Internal fragmentation expands in light of the contiguous memory allocation.
单个进程会被分配到一个固定大小的内存分区中。这种方式能够提高多道程序设计的程度,即主存中可以容纳多个进程,但这也会限制内存中固定分区的数量。连续内存分配会导致内部碎片的增加。
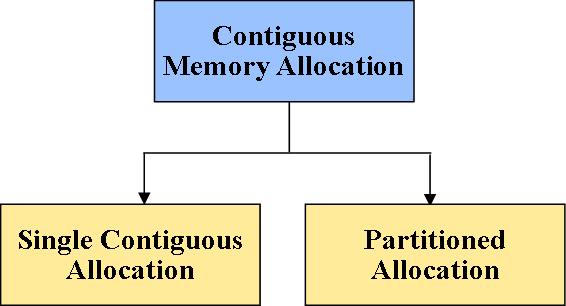
Types of Contiguous Memory Management Technique
连续内存管理技术的分类
Single Contiguous memory Allocation or fixed sized partition:
单一连续内存分配或固定大小分区分配:
It is the most effortless memory management technique. In this strategy, a wide range of computer memory aside from a little part which is held for the working framework is accessible for one application. In other words it is also known as fixed sized partition of the system that separates memory into fixed-size segments (might possibly be of a similar size). In this whole partition is permitted to a procedure and if there is some wastage inside the segment is apportioned to a procedure and if there is some wastage inside the segment, at that point it is called an internal fragmentation.
这是最为简单的内存管理技术。在该策略中,计算机的全部内存空间中,除了一小块预留用于存放操作系统的区域外,其余部分均分配给单个应用程序使用。换言之,该技术也被称为系统的固定大小分区分配,这种方式会将内存划分为若干个固定大小的分区(分区大小可以相同,也可以不同)。在该机制中,整个内存分区会被分配给单个进程,如果分配给进程的分区内部存在未被利用的空间,这类空间就被称为内部碎片。
For instance, the MS-DOS operating system designates memory along these lines. An embedded system likewise runs on a solitary application.
例如,微软磁盘操作系统(MS - DOS)就是采用这种方式进行内存分配的。嵌入式系统 通常也只运行单个应用程序。
-
Advantage: Management or accounting is simple.
优点:管理与记录工作较为简便。 -
Disadvantage: Occurrence of Internal fragmentation.
缺点:会产生内部碎片。
Partitioned Allocation
分区分配
It is also called variable size segments/partitions. In which system isolates essential memory into different memory segments, which are generally adjacent classes of memory. Each segment stores all the data for a particular task/job. This technique comprises allocating a segment to occupation when it begins and unallocated when it closes. In the variable size partition, the memory is treated as one unit, and space allotted to a procedure is actually equivalent to require and the extra space can be reused once more.
该技术也被称为可变大小分段/分区分配。在这种机制中,系统会将主存划分为多个内存分区,这些分区通常是相邻的内存块。每个分区用于存储特定任务或作业的全部数据。该技术的工作方式是,在任务开始执行时为其分配一个内存分区,任务结束时回收该分区。在可变大小分区分配机制中,内存被视为一个整体单元,分配给进程的空间大小与进程的实际需求完全匹配,剩余的空闲空间可以被再次利用。
-
Advantage: This technique is free from internal fragmentation.
优点:该技术不会产生内部碎片。 -
Disadvantage: Management is troublesome as memory is getting absolutely divided after some time.
缺点:随着时间推移,内存会被完全划分,导致管理工作变得困难。
Non-contiguous memory allocation
非连续内存分配
In the allocation of non-contiguous memory, the accessible free memory space is dispersed to a great extent and all the free memory space isn’t in one spot. This technique is time-consuming. In the non-contiguous memory allocation, a procedure will procure the memory space however it isn’t at one spot it is at the various areas as indicated by the procedure prerequisite. This strategy of non-touching memory allocation reduces the wastage of memory which prompts internal and external fragmentation. This uses all the free memory space which is made by alternate processes.
在非连续内存分配机制中,可用的空闲内存空间大多是分散的,不会集中在单个连续区域。该技术的执行过程耗时较长。在非连续内存分配方式下,进程会获取满足自身需求的内存空间,但这些内存空间并非连续的一块,而是分布在多个不同的区域。这种非连续的内存分配策略能够减少由内部碎片和外部碎片导致的内存浪费,并且可以充分利用其他进程释放的所有空闲内存空间。
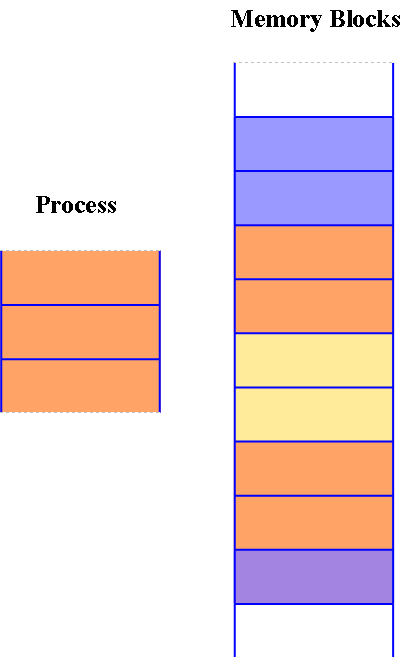
Non-Contiguous Memory Allocation
非连续内存分配
Types of non-contiguous memory allocation
非连续内存分配的分类
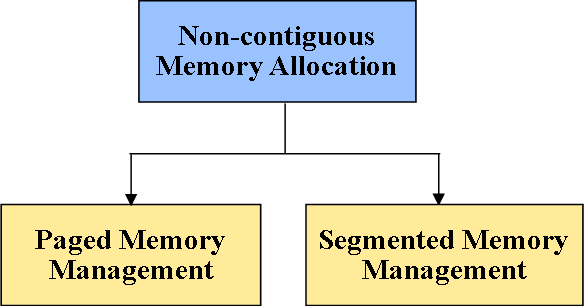
Types of non-contiguous memory allocation
非连续内存分配的分类
Paged Memory Management
分页内存管理
This strategy category the computer’s primary memory into the fixed-size units that is known as page frames. This hardware memory management unit maps pages into frames that ought to be apportioned on a page premise.
该策略会将计算机的主存划分为若干个固定大小的单元,这些单元被称为页帧。硬件内存管理单元(MMU)负责将进程的页面映射到页帧中,内存分配工作会以页面为基本单位进行。
-
Advantages of paged memory management: It is free of external fragmentation.
-
分页内存管理的优点:不会产生外部碎片。
-
Disadvantages of paged memory management:
-
分页内存管理的缺点:
-
It makes the interpretation extremely delayed as primary memory get to multiple times.
由于需要多次访问主存,会导致地址转换过程的执行速度大幅变慢。 -
A page table is a burden over the framework which consumes impressive space.
页表会占用大量内存空间,对系统造成一定的负担。
-
Segmented Memory Management
分段内存管理
Management of Segmented memory is the only memory management technique that doesn’t provide the client’s program with a direct and adjoining address space.
分段内存管理是唯一一种不会为用户程序提供连续的直接地址空间的内存管理技术。
Segments need equipment support as a segment table. It contains the physical address of the area in memory, size, and other information like access assurance bits and status.
分段机制需要硬件提供段表作为支撑。段表中存储了内存分区的物理地址、分区大小,以及访问权限位、状态位等其他相关信息。
Advantages of segmented memory management technique
分段内存管理技术的优点
-
Allow the memory ability to be 1 MB despite the fact that the addresses related with the individual directions are 16 bits wide.
即便单个指令的地址宽度为 16 位,也可以使内存的寻址能力达到 1 MB。 -
Allow the utilization of independent memory regions for the program code and information and stack part of the program.
可以为程序的代码段、数据段和栈段分配相互独立的内存区域。 -
It permits a program and additionally its information to be put into various areas of memory at whatever point the program is end.
当程序结束运行时,可以将程序及其对应的数据存放在内存的不同区域。 -
Multitasking turns out to be simple
使多任务处理的实现变得更加简便
Disadvantages of segmented memory management technique:
分段内存管理技术的缺点:
-
Availability of external fragmentation
会产生外部碎片 -
Algorithms of memory management are costly.
内存管理算法的实现成本较高 -
Segmentation discovers free memory areas sufficiently large.
需要查找足够大的空闲内存区域 -
Paging keeps rundown of free pages.
分页机制需要维护空闲页的列表 -
Segments of inconsistent size not fit also for trading.
大小不一致的段不适合进行交换操作
20 张图揭开「内存管理」的迷雾,瞬间豁然开朗
小林coding 于 2020-06-30 14:40:44 发布
本文深入解析操作系统如何通过虚拟内存、内存分段、分页、多级页表及 TLB 等技术,解决多进程环境下的内存隔离与高效利用问题。

前言
此前,诸多读者反馈希望作者撰写图解操作系统相关内容。
基于读者的广泛需求,作者近期正系统复习操作系统相关知识。
操作系统属于计算机专业课程体系中难度较高的科目,其学习难度高于计算机网络课程,该课程的重要性无需赘述。
操作系统学习过程中的主要难点在于,课程涉及大量抽象且难以理解的概念与术语,学习者极易因此产生畏难情绪。
即便以饱满的热情开启操作系统的学习,学习者也可能在短时间内陷入困倦状态。
操作系统知识的学习无法回避,图解形式的讲解也需推进,备受期待的「图解操作系统」系列由此开篇。
本文聚焦操作系统中的内存管理模块展开讲解。内存管理是操作系统的重要组成部分,理解该模块的工作机制,能够帮助学习者构建起操作系统运行原理的初步框架,这也是内存管理成为面试高频考点的原因。
下文为本文的内容提纲:

1 虚拟内存
电子信息相关专业学习者,在大学阶段通常接触过单片机相关实验。
单片机系统未搭载操作系统,因此每次编写程序后,需借助专用工具将程序烧录至单片机存储介质中,程序方可运行。
此外,单片机的 CPU 直接对内存的物理地址进行操作。

在此类运行模式下,内存中无法同时运行两个程序。若第一个程序向地址 2000 写入新值,将会覆盖第二个程序存储于同一地址的全部数据,进而导致两个程序均立即崩溃。
操作系统如何解决上述问题?
该问题的核心症结在于两个程序均直接引用物理地址,而这正是操作系统需要规避的运行方式。
操作系统可对进程使用的地址空间进行隔离,即为每个进程分配一套独立的虚拟地址空间。各进程仅需在自身虚拟地址空间内完成数据读写,进程间不会产生地址冲突。进程无需关注物理地址的具体分配,虚拟地址至物理地址的映射过程由操作系统完成,该过程对进程透明。

操作系统提供地址映射机制,将不同进程的虚拟地址与物理内存的不同物理地址建立关联。
当程序访问虚拟地址时,由操作系统将虚拟地址转换为对应的物理地址。在此机制下,不同进程运行时的数据写入操作将指向不同的物理地址,从而避免地址冲突问题。
由此引出两种地址的定义:
- 程序编写与运行过程中使用的内存地址称为虚拟内存地址(Virtual Memory Address)
- 计算机硬件内存中实际存在的存储单元地址称为物理内存地址(Physical Memory Address)
操作系统引入虚拟内存机制后,进程持有的虚拟地址需通过 CPU 芯片内置的内存管理单元(MMU)完成地址映射,转换为物理地址后,方可访问内存,具体流程如下图所示:

操作系统如何管理虚拟地址与物理地址之间的映射关系?
主流的地址映射方式分为两种,分别为内存分段与内存分页。内存分段是较早提出的地址映射技术,下文首先对该技术展开讲解。
2 内存分段
程序由若干个具有独立逻辑功能的段构成,典型的程序段包括代码段、数据段、栈段与堆段。不同程序段具备不同的属性特征,内存分段(Segmentation)技术的作用在于将这些不同属性的程序段进行分离存储。
分段机制下,虚拟地址与物理地址如何实现映射?
分段机制下的虚拟地址由两部分构成,分别为段选择子与段内偏移量。

- 段选择子存储于段寄存器中,其核心组成部分为段号,段号作为段表的索引值使用。段表中存储的信息包括对应段的基地址、段的界限以及段的特权等级等。
- 虚拟地址中的段内偏移量需满足取值范围在
0与段界限之间的条件。若段内偏移量合法,则将段基地址与段内偏移量相加,计算结果即为对应的物理内存地址。
前文已明确虚拟地址通过段表与物理地址建立映射关系。分段机制将程序的虚拟地址空间划分为 4 个段,每个段在段表中对应一个表项。通过查询段表项获取段的基地址,基地址与段内偏移量相加即可得到物理内存地址,具体流程如下图所示:

以访问段 3 中偏移量为 500 的虚拟地址为例,对应的物理地址计算方式为:段 3 的基地址 7000 + 偏移量 500 = 7500。
内存分段技术有效解决了程序无需关注物理内存地址的问题,但该技术存在以下两方面缺陷:
- 第一,存在内存碎片问题
- 第二,存在内存交换效率低下问题
下文将对上述两个问题的产生原因展开分析。
首先分析内存分段产生内存碎片问题的原因。
以一个具体场景为例:假设物理内存总容量为 1 GB,系统中同时运行多个程序,各程序占用的内存空间如下:
- 游戏程序占用
512 MB内存 - 浏览器程序占用
128 MB内存 - 音乐播放程序占用
256 MB内存
此时关闭浏览器程序,系统空闲内存容量为 1024 - 512 - 256 = 256 MB。
若该 256 MB 空闲内存并非连续空间,而是被划分为两个 128 MB 的不连续内存块,则系统无法为一个需要 200 MB 连续内存空间的新程序分配内存。

内存分段机制产生的内存碎片问题分为两类:
- 外部内存碎片:系统中存在多个不连续的小容量物理内存块,无法满足新程序对连续内存空间的需求
- 内部内存碎片:程序占用的全部内存均被加载至物理内存,但程序运行过程中仅使用部分内存空间,未被使用的内存区域造成内存资源浪费
针对上述两类内存碎片问题,需采用不同的解决方式。
外部内存碎片问题的解决方式为内存交换。
具体操作流程为:将音乐播放程序占用的 256 MB 内存数据写入硬盘,随后将数据从硬盘重新读取至内存。数据重新加载时,不再写入原内存地址,而是紧邻游戏程序占用的 512 MB 内存空间进行存储。此时系统中将出现一块连续的 256 MB 空闲内存空间,可满足新程序的内存需求。
在 Linux 系统中,上述用于内存交换的硬盘空间被称为 Swap 空间。该空间从硬盘中划分而来,专门用于内存数据与硬盘数据的交换存储。
接下来分析内存分段导致内存交换效率低下问题的原因。
在多进程系统中,内存分段机制极易产生内存碎片。为解决内存碎片问题,需频繁执行内存交换操作,而该操作将成为系统性能的瓶颈。
硬盘的访问速度远低于内存,每次内存交换均需将一整块连续的内存数据写入硬盘。
因此,若内存交换操作涉及占用大量内存空间的程序,将导致整个系统运行出现明显卡顿。
为解决内存分段机制存在的内存碎片与内存交换效率低下问题,内存分页技术应运而生。
3 内存分页
内存分段技术的优势在于可分配连续的内存空间,但同时存在内存碎片与内存交换数据量大的问题。
要解决上述问题,需采用能够减少内存碎片产生,且在内存交换时减少数据传输量的内存管理技术,该技术即为内存分页(Paging)。
内存分页技术将整个虚拟地址空间与物理地址空间划分为若干个固定尺寸的内存块,这种尺寸固定且连续的内存块被称为页(Page)。在 Linux 系统中,每页的大小为 4 KB。
虚拟地址与物理地址之间通过页表建立映射关系,具体流程如下图所示:

页表实际存储于 CPU 的内存管理单元(MMU)中,因此 CPU 可直接通过 MMU 查询页表,获取待访问的物理内存地址。
当进程访问的虚拟地址在页表中无对应表项时,系统将触发缺页异常。此时系统将进入内核空间,为进程分配物理内存,并更新进程对应的页表,最后返回用户空间,恢复进程的运行状态。
内存分页技术如何解决内存分段机制存在的内存碎片与内存交换效率低下问题?
由于内存空间被预先划分为尺寸固定的页,因此不会产生内存分段机制下的小容量不连续内存块,而这正是内存碎片产生的根源。采用内存分页技术后,内存的释放操作以页为单位进行,从而避免产生无法被进程利用的小容量内存块。
当系统物理内存空间不足时,操作系统会将其他正在运行的进程中「最近未被使用」的内存页释放,即将数据暂时写入硬盘,该操作称为换出(Swap Out)。当进程需要访问这些数据时,再将数据从硬盘加载至物理内存,该操作称为换入(Swap In)。内存交换过程中,写入硬盘的数据仅为少数几个内存页,数据传输量较小,因此内存交换的效率得到显著提升。

更进一步,内存分页技术使程序加载方式发生优化。程序加载时,无需将全部数据一次性加载至物理内存,而是在建立虚拟内存页与物理内存页的映射关系后,仅在程序运行过程中需要访问某虚拟内存页的指令或数据时,才将该页加载至物理内存。
分页机制下,虚拟地址与物理地址如何实现映射?
分页机制下的虚拟地址由两部分构成,分别为页号与页内偏移。页号作为页表的索引值,页表中存储了各物理页对应的物理内存基地址。物理页基地址与页内偏移量相加,即可得到对应的物理内存地址,具体流程如下图所示:

综上所述,虚拟地址至物理地址的转换流程分为以下三步:
- 将虚拟内存地址拆分为页号与页内偏移量两部分
- 根据页号查询页表,获取对应的物理页号
- 将物理页号与页内偏移量相加,计算得到物理内存地址
以下为虚拟内存页通过页表映射至物理内存页的示例,具体流程如下图所示:

上述分页机制在理论层面可行,但在实际操作系统中,这种简单的分页机制存在明显缺陷。
简单分页机制存在哪些缺陷?
该机制的主要缺陷体现在内存空间占用方面。
操作系统可同时运行大量进程,而每个进程均需维护独立的页表,这将导致页表占用的内存空间急剧增加。
在 32 位系统环境下,虚拟地址空间总容量为 4 GB。假设每页大小为 4 KB(
2
12
2^{12}
212),则虚拟地址空间共包含约
100
100
100 万个(
2
20
2^{20}
220)内存页。每个页表项需占用 4 字节内存空间存储映射信息,因此映射整个 4 GB 虚拟地址空间的页表需占用 4 MB 内存空间。
4 MB 的页表内存占用量看似不大,但需注意每个进程均拥有独立的虚拟地址空间,即每个进程均需维护一份独立的页表。
若系统中同时运行 100 个进程,则页表总共需占用 400 MB 内存空间,这将造成大量内存资源消耗,在 64 位系统环境下,该问题将更加突出。
3.1 多级页表
为解决简单分页机制的内存占用问题,操作系统引入多级页表(Multi-Level Page Table)技术。
前文已明确,在 32 位系统、页大小为 4 KB 的环境下,单个进程的单级页表包含超过
100
100
100 万个页表项,每个页表项占用 4 字节内存空间,因此单级页表需占用 4 MB 内存空间。
多级页表技术的实现方式为:将包含
100
100
100 万个页表项的单级页表进行分页处理,划分为 1024 个二级页表,每个二级页表包含 1024 个页表项,由此形成二级分页机制,具体结构如下图所示:

可能存在的疑问:二级分页机制下,映射
4 GB虚拟地址空间需占用4 KB(一级页表) +4 MB(二级页表)的内存空间,内存占用量反而增加,该技术的优势体现在何处?
若 4 GB 虚拟地址空间全部映射至物理内存,二级分页机制的内存占用量确实高于单级页表。但在实际系统运行过程中,进程不会占用全部虚拟地址空间。
此处需引入计算机组成原理中的局部性原理进行分析:
每个进程均拥有 4 GB 虚拟地址空间,但多数程序运行时占用的内存空间远低于 4 GB,因此页表中存在大量未被使用的空表项,这些空表项无需分配物理内存空间。对于已分配的页表项,若对应内存页在一定时间内未被访问,当系统物理内存紧张时,操作系统会将这些内存页换出至硬盘,即这些页表项不会持续占用物理内存。
采用二级分页机制后,一级页表可覆盖整个 4 GB 虚拟地址空间,但仅当一级页表的某一页表项被访问时,才会创建对应的二级页表。通过简单计算可知,假设仅 20% 的一级页表项被使用,则页表占用的内存空间为 4 KB(一级页表) + 20% * 4 MB(二级页表) = 0.804 MB,与单级页表的 4 MB 内存占用量相比,实现了内存资源的大幅节约。
单级页表无法实现上述内存节约效果的原因在于:页表的核心功能是完成虚拟地址至物理地址的转换,若虚拟地址在页表中无对应表项,系统将无法正常运行。因此单级页表必须覆盖全部虚拟地址空间,需包含 100 100 100 万个页表项;而二级分页机制中,仅需 1024 1024 1024 个一级页表项即可覆盖全部虚拟地址空间,二级页表可在需要时动态创建。
将二级分页机制进一步扩展,可得到多级页表机制,多级页表能够进一步降低页表的内存占用量,这一优势的实现完全得益于对局部性原理的充分应用。
在 64 位系统中,二级分页机制无法满足地址映射需求,因此采用四级页表目录结构,各级目录的定义如下:
- 全局页目录项 PGD(Page Global Directory)
- 上层页目录项 PUD(Page Upper Directory)
- 中间页目录项 PMD(Page Middle Directory)
- 页表项 PTE(Page Table Entry)

3.2 TLB
多级页表机制解决了页表的内存占用问题,但同时增加了虚拟地址至物理地址的转换步骤,导致地址转换速度降低,产生时间开销。
程序运行过程中遵循局部性原理,即一段时间内,程序的执行范围局限于某一特定区域,对应的内存访问操作也集中于某一内存区域。

基于局部性原理,可将程序频繁访问的页表项存储于访问速度更快的硬件存储介质中。为此,计算机科学家在 CPU 芯片中集成了专用缓存,用于存储程序高频访问的页表项,该缓存被称为 TLB(Translation Lookaside Buffer),通常也被称为页表缓存、转址旁路缓存或快表。

CPU 芯片内部封装了内存管理单元(Memory Management Unit)芯片,该芯片负责完成地址转换以及 TLB 的访问与数据交互操作。
引入 TLB 后,CPU 寻址流程优化为:首先查询 TLB,若未找到对应页表项,再查询常规页表。
TLB 的命中率较高,原因在于程序运行过程中频繁访问的内存页数量有限。
4 段页式内存管理
内存分段与内存分页并非对立的内存管理技术,二者可结合应用于同一操作系统中,这种结合的内存管理方式被称为段页式内存管理。

段页式内存管理的实现流程如下:
- 按照程序的逻辑功能,将程序划分为若干个段,此过程即前文所述的内存分段机制
- 将每个段进一步划分为若干个尺寸固定的页,即对分段后的连续内存空间执行分页操作
在段页式内存管理机制下,虚拟地址结构由段号、段内页号与页内位移三部分组成。
段页式地址转换的数据结构包括:每个程序对应一张段表,每个段对应一张页表。段表中的表项存储对应页表的起始地址,页表中的表项存储对应物理页的页号,具体映射关系如下图所示:

段页式地址转换过程中,需经过三次内存访问操作才能得到物理地址,具体步骤如下:
- 访问段表,获取对应页表的起始地址
- 访问页表,获取目标数据所在的物理页号
- 将物理页号与页内位移量相加,得到最终的物理地址
段页式地址转换可通过软硬件结合的方式实现。该方式虽然增加了硬件成本与系统运行开销,但有效提升了内存资源的利用率。
5 Linux 内存管理
Linux 操作系统采用何种内存管理方式?
回答该问题前,需首先了解 Intel 处理器的发展历程。
早期 Intel 处理器从 80286 型号开始引入段式内存管理机制。但随后发现,仅依靠段式内存管理机制无法满足系统性能需求,这将导致 X86 系列处理器失去市场竞争力。因此,在后续推出的 80386 型号处理器中,Intel 在完善段式内存管理机制的同时,实现了页式内存管理机制。
需要注意的是,80386 处理器的页式内存管理机制并非独立于段式内存管理机制,而是建立在段式内存管理机制的基础之上。这意味着,页式内存管理机制的作用对象是段式内存管理机制映射得到的地址,该地址在经过页式内存管理机制的二次映射后,才会转换为物理地址。
由于段式内存管理机制映射得到的地址不再是物理地址,Intel 将其命名为线性地址(也称为虚拟地址)。因此,段式内存管理机制首先将逻辑地址映射为线性地址,随后页式内存管理机制再将线性地址映射为物理地址,具体流程如下图所示:

此处对逻辑地址与线性地址的概念进行明确:
- 程序编写过程中使用的、未经过段式内存管理机制映射的地址称为逻辑地址
- 经过段式内存管理机制映射得到的地址称为线性地址,也可称为虚拟地址
逻辑地址是段式内存管理机制的输入地址,线性地址是页式内存管理机制的输入地址。
结合 Intel 处理器的发展历程,分析 Linux 操作系统采用的内存管理方式。
Linux 操作系统以页式内存管理机制为主要内存管理方式,但同时不可避免地涉及段式内存管理机制。
这一设计的根本原因在于 Intel X86 系列处理器的硬件架构限制:CPU 对程序地址的处理流程为先执行段式映射,再执行页式映射。基于该硬件架构,Linux 内核必须遵循这一地址处理流程。
但 Linux 内核通过技术手段弱化了段式内存管理机制的作用,具体实现方式为:Linux 系统中所有段的起始地址均为 0,且覆盖整个 4 GB 虚拟地址空间(32 位系统环境下)。这意味着,Linux 系统中的程序代码(包括操作系统内核代码与应用程序代码)所面对的地址空间均为线性地址空间(虚拟地址空间)。该设计相当于屏蔽了处理器的逻辑地址概念,段式内存管理机制仅用于访问控制与内存保护功能。
进一步分析 Linux 操作系统的虚拟地址空间分布。
Linux 操作系统的虚拟地址空间分为内核空间与用户空间两部分,不同位数的系统对应不同的地址空间范围,常见的 32 位系统与 64 位系统的地址空间分布如下图所示:

通过上图可得出以下结论:
- 32 位系统中,内核空间占用
1 GB,位于虚拟地址空间的最高地址区域,剩余3 GB为用户空间 - 64 位系统中,内核空间与用户空间的容量均为
128 TB,分别位于虚拟地址空间的最高地址区域与最低地址区域,中间部分为未定义地址空间
内核空间与用户空间的核心区别如下:
- 进程处于用户态时,仅能访问用户空间的内存区域
- 进程进入内核态后,才可访问内核空间的内存区域
尽管每个进程均拥有独立的虚拟地址空间,但所有进程虚拟地址空间中的内核地址均映射至相同的物理内存区域。这一设计使得进程切换至内核态后,可快速访问内核空间的内存数据。

下文进一步分析虚拟地址空间的详细划分。内核空间与用户空间的划分方式存在差异,此处重点分析用户空间的分布情况。以 32 位系统为例,用户空间的内存分布如下图所示:

从图中可知,用户空间内存从低地址到高地址依次划分为以下 7 个内存段:
- 程序文件段:存储二进制可执行代码
- 已初始化数据段:存储静态常量等已初始化数据
- 未初始化数据段:存储未初始化的静态变量(BSS 段)
- 堆段:存储动态分配的内存数据,地址从低到高向上增长
- 文件映射段:存储动态库、共享内存等数据,地址从低到高向上增长(该区域的地址分布与硬件架构及内核版本相关_)
- 栈段:存储局部变量与函数调用上下文等数据,栈空间大小固定,通常为
8 MB,用户可通过系统参数自定义栈空间大小
在上述 7 个内存段中,堆段与文件映射段的内存空间支持动态分配。例如,使用 C 标准库中的 malloc() 函数可在堆段动态分配内存,使用 mmap() 函数可在文件映射段动态分配内存。
6 总结
为实现多进程环境下进程间的内存地址隔离,操作系统为每个进程分配独立的虚拟地址空间。各程序仅需关注自身虚拟地址空间的操作,不同进程的虚拟地址可重复,但对应的物理地址各不相同,进程无需关注物理地址的具体分配。
每个进程均拥有独立的虚拟地址空间,而物理内存资源是有限的。当系统中运行大量进程时,物理内存资源将趋于紧张。为此,操作系统引入内存交换技术,将暂时未被使用的内存数据写入硬盘(换出),当进程需要访问这些数据时,再将数据从硬盘加载至物理内存(换入)。
虚拟地址至物理地址的映射关系由操作系统维护,主流的映射方式包括分段与分页,二者也可结合使用。
内存分段机制根据程序的逻辑结构,将虚拟地址空间划分为栈段、堆段、数据段、代码段等不同区域,各区域为连续的内存空间。但由于各段的大小不固定,该机制易产生内存碎片问题,且内存交换时的数据传输量较大,导致交换效率低下。
为解决上述问题,内存分页机制被引入。该机制将虚拟地址空间与物理地址空间划分为尺寸固定的页,在 Linux 系统中,每页大小为 4 KB。分页机制有效减少了内存碎片的产生,同时内存交换操作仅需传输少量内存页的数据,大幅提升了内存交换效率。
针对简单分页机制存在的页表内存占用过大问题,多级页表技术被提出。该技术有效降低了页表的内存开销,但同时增加了地址转换的步骤,导致地址转换速度下降。基于程序的局部性原理,CPU 芯片中集成了 TLB 缓存,用于存储高频访问的页表项,从而显著提升了地址转换速度。
Linux 操作系统以分页管理机制为主要内存管理方式,但受 Intel 处理器架构限制,无法完全规避分段管理机制。为此,Linux 系统将所有段的基地址设为 0,使得程序地址空间均为线性地址空间(虚拟地址空间),相当于屏蔽了逻辑地址的概念,段式管理机制仅用于访问控制与内存保护。
此外,Linux 系统的虚拟地址空间分为用户态与内核态两部分,其中用户态地址空间从低到高依次分布着代码段、全局变量段、BSS 段、堆段、内存映射段与栈段。
Linux 内存管理深度解析
C语言与CPP编程 2022-01-05 09:45
本文将聚焦 Linux 内存管理 展开深入讲解。
对于专注业务开发的工程师而言,内存管理相关知识看似与日常工作关联度较低,但该知识属于计算机底层技术的重要内容。
前提约定:本文所有技术内容的讨论,均基于 x86 架构的 32 位 Linux 操作系统环境。
虚拟地址
在现代操作系统中,内存依旧属于计算机系统的稀缺资源。对比计算机的固态硬盘容量与内存容量,即可直观感受到内存资源的宝贵性。
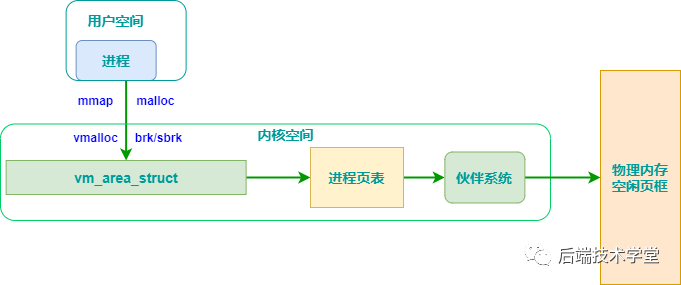
为实现内存资源的高效利用与精细化管理,Linux 操作系统采用虚拟内存管理技术。该技术为每个进程分配 4 GB 大小的独立虚拟地址空间,进程之间的地址空间完全隔离。
进程初始化阶段与运行过程中,所分配和操作的地址均为虚拟地址。仅当进程需要实际访问内存资源时,操作系统才会建立虚拟地址与物理地址的映射关系,并将对应的物理内存页调入内存。
此处可通过一个生活化的比喻理解该机制:该原理类似于网络云盘的空间分配逻辑。云盘界面显示用户拥有 1 TB 存储空间,但云服务提供商并不会一次性为用户分配 1 TB 实际存储资源,而是在用户上传数据时,根据数据大小动态分配对应容量的实际存储空间。从用户视角来看,所有用户均拥有 1 TB 的虚拟存储空间。
虚拟地址的优势
- 内存保护:避免用户进程直接访问物理内存地址,防止恶意操作或误操作对操作系统内核造成破坏,保障系统稳定性与安全性。
- 地址空间扩展:为每个进程分配
4 GB虚拟地址空间,使得用户程序可使用的地址空间大小突破物理内存容量的限制。
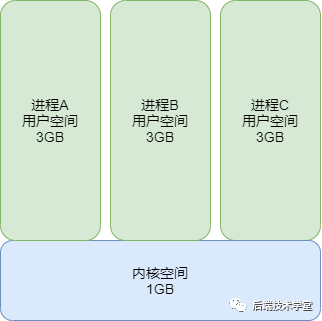
4 GB 的进程虚拟地址空间在逻辑上划分为两个部分,分别为用户空间与内核空间。
用户空间与内核空间划分示意图
物理地址
通过前文内容可知,无论是用户空间还是内核空间,进程所直接操作的地址均为虚拟地址。当进程需要访问实际内存数据时,内核的请求分页机制会触发缺页异常,随后操作系统将对应的物理内存页调入内存。
虚拟地址到物理地址的转换过程,需要借助 CPU 内置的 MMU(Memory Management Unit,内存管理单元),通过段页式地址转换机制完成。关于分段与分页的具体实现流程,可参考任意一本《计算机组成原理》教材中的相关章节,本文不再赘述。

段页式内存管理地址转换流程示意图
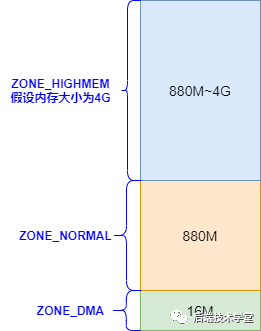
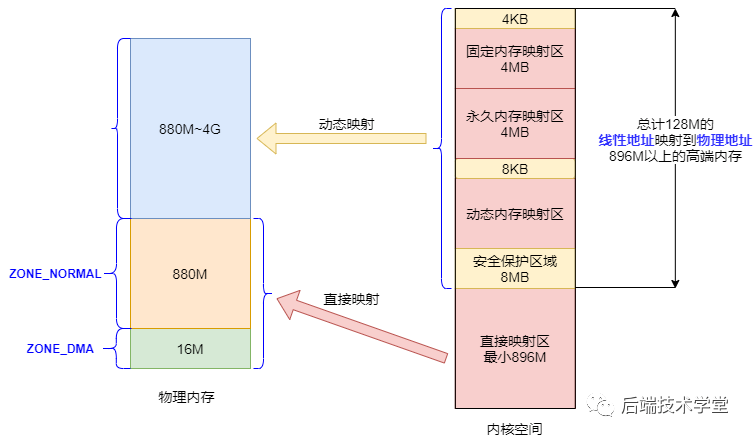
Linux 内核将物理内存划分为 3 个管理区域,各区域的定义与功能如下:
ZONE_DMA
DMA 内存区域。该区域包含的物理内存页框地址范围为 0 MB ~ 16 MB,适用于老式基于 ISA 总线的设备通过 DMA(直接内存访问)方式进行数据传输。该区域的物理地址直接映射到内核的线性地址空间。
ZONE_NORMAL
普通内存区域。该区域包含的物理内存页框地址范围为 16 MB ~ 896 MB,属于系统的常规内存页框。该区域的物理地址同样直接映射到内核的线性地址空间。
ZONE_HIGHMEM
高端内存区域。该区域包含的物理内存页框地址范围为 896 MB 以上,这部分物理地址不与内核线性地址空间进行直接映射。如需访问该区域的内存页框,需通过永久映射或临时映射两种方式实现。
物理内存管理区域划分示意图
用户空间
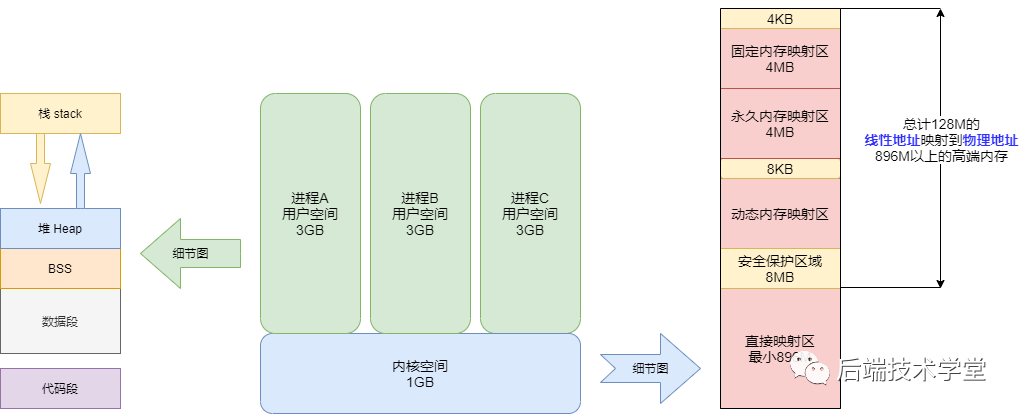
用户进程能够直接访问的地址空间为用户空间。在 32 位 Linux 系统中,每个进程的用户空间虚拟地址范围为 0x00000000 ~ 0xBFFFFFFF,总容量为 3 GB。
用户进程在默认状态下仅能访问用户空间的虚拟地址,只有在执行中断操作或系统调用时,进程才会切换至内核态,从而获得访问内核空间的权限。
进程与内存
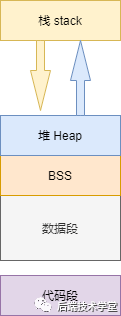
进程作为程序的执行实例,其占用的用户空间按照访问属性一致的地址空间集中存放的原则,划分为 5 个不同的内存区域。此处的访问属性包含可读、可写、可执行等权限。
-
代码段
代码段用于存放可执行文件的指令序列,是可执行程序在内存中的镜像。为防止程序运行过程中指令被非法修改,代码段通常被设置为只读属性。 -
数据段
数据段用于存放可执行文件中已初始化的全局变量与静态变量,即程序运行前已确定初始值的变量。 -
BSS 段
BSS 段(Block Started by Symbol)包含程序中未初始化的全局变量与静态变量。程序加载时,操作系统会将 BSS 段对应的内存区域全部初始化为 0。 -
堆(heap)
堆是用于存放进程运行过程中动态分配内存的区域,其大小不固定,可根据程序需求动态扩张或缩减。当进程调用malloc()等内存分配函数时,新分配的内存会被添加到堆中,使堆空间扩张;当调用free()等内存释放函数时,被释放的内存会从堆中移除,使堆空间缩减。 -
栈(stack)
栈是用于存放程序临时创建的局部变量的区域,这些变量包括函数的参数、函数内定义的非静态局部变量等。函数被调用时,其参数与返回地址会被压入调用进程的栈中;函数调用结束时,栈中存放的相关数据会被弹出,栈空间自动收缩。栈的操作遵循先进后出的原则,这一特性使其非常适合用于保存和恢复函数调用的现场。
在上述 5 个内存区域中,数据段、BSS 段与堆通常在内存中连续存储;代码段与栈则为独立的内存区域,与其他区域不连续。在 x86 体系结构中,栈的地址空间从高地址向低地址扩展,堆的地址空间从低地址向高地址扩展,二者在地址空间中呈现相对而生的布局。
进程用户空间内存区域分布示意图
在 Linux 系统中,可通过 size 命令查看编译后可执行程序的各个内存区域大小,示例如下:
[lemon ~]# size /usr/local/sbin/sshd
text data bss dec hex filename
1924532 12412 426896 2363840 2411c0 /usr/local/sbin/sshd
内核空间
在 x86 32 位 Linux 系统中,内核空间的虚拟地址范围为 0xC0000000 ~ 0xFFFFFFFF,总容量为 1 GB。该空间存放的内容包括内核镜像、物理页面表、设备驱动程序等系统组件,这些组件均运行于内核态。
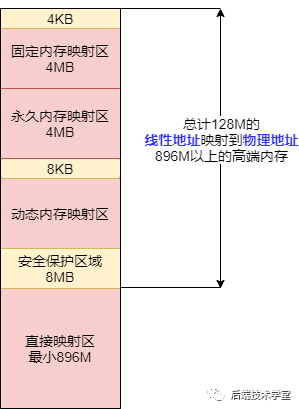
内核空间细分区域示意图
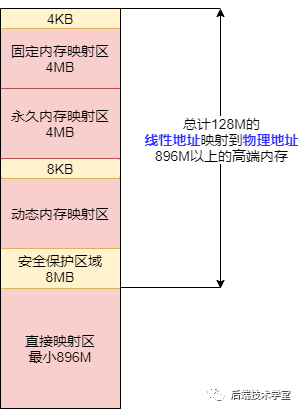
直接映射区
直接映射区(Direct Memory Region)的地址范围为内核空间起始地址至 896 MB 处,是内核空间中最大的一个区域。
该区域的 896 MB 线性地址与物理内存的前 896 MB 地址进行直接映射,即线性地址与对应的物理地址是连续的。线性地址与物理地址之间存在固定的偏移量 PAGE_OFFSET = 0xC0000000,因此线性地址 0xC0000001 对应的物理地址为 0x00000001。
该区域的线性地址与物理地址可通过公式直接转换:线性地址 = PAGE_OFFSET + 物理地址。内核也提供了 virt_to_phys() 函数,用于将该区域的线性地址转换为对应的物理地址。
高端内存线性地址空间
高端内存线性地址空间的地址范围为 896 MB ~ 1 GB,总容量为 128 MB。该区域的设置是为了解决内核空间线性地址不足的问题。
前文提到,内核空间的总容量为 1 GB,若直接映射区的 896 MB 线性地址仅能映射 896 MB 的物理内存,那么当系统的物理内存容量超过 896 MB 时,超出部分的物理内存将无法被内核直接访问。而在现代计算机系统中,物理内存容量通常远大于 1 GB,因此需要通过高端内存线性地址空间实现对全部物理内存的寻址。
需要注意的是,在 64 位 Linux 系统中,由于可用的线性地址空间极大,远超过当前主流的物理内存容量,因此不存在高端内存的寻址问题。
高端内存线性地址空间进一步划分为以下 3 个区域:
动态内存映射区
动态内存映射区(vmalloc Region)的内存分配由内核函数 vmalloc() 完成。该区域的特点是:分配的线性地址空间是连续的,但对应的物理地址空间不一定连续。vmalloc() 函数分配的线性地址所对应的物理页,既可能来自低端内存区域,也可能来自高端内存区域。
永久内存映射区
永久内存映射区(Persistent Kernel Mapping Region)用于访问高端内存区域的物理页。访问该区域的方式为:通过 alloc_page(_GFP_HIGHMEM) 函数分配高端内存页,或使用 kmap() 函数将分配到的高端内存页映射到该区域。
固定映射区
固定映射区(Fixing Kernel Mapping Region)位于内核空间的最高地址区域,与 4 GB 虚拟地址顶端仅相隔 4 KB 的隔离带。该区域的每个地址项都有特定的用途,例如 ACPI_BASE 等硬件相关的地址映射。
内核空间物理内存映射示意图
回顾总结
为帮助读者梳理前文内容,建立 Linux 内存管理的全局认知,作者绘制了一张整合用户空间与内核空间的内存布局图。通过前文的学习,读者应能够理解该图所展示的内存管理体系结构。
用户空间与内核空间内存布局全景图
内存管理数据结构
为实现对系统虚拟内存的有效管理,Linux 内核从内存区域中抽象出相应的内存管理数据结构。内存的分配、释放等操作,均基于这些数据结构完成。本节将介绍两种用于管理虚拟内存区域的数据结构。
用户空间内存数据结构
在「进程与内存」章节中提到,Linux 进程的用户空间划分为代码段、数据段、BSS 段、堆、栈 5 个内存区域。内核对这些区域的管理方式为:将每个内存区域抽象为一个 vm_area_struct 结构体对象。
vm_area_struct 是描述进程地址空间的基本管理单元。一个进程通常需要多个 vm_area_struct 对象来描述其完整的用户空间虚拟地址,内核通过链表和红黑树两种数据结构来组织这些对象。
- 链表适用于需要遍历全部
vm_area_struct对象的场景,例如进程退出时释放所有内存区域。 - 红黑树适用于在进程地址空间中快速定位特定的内存区域,例如缺页异常处理时查找虚拟地址对应的内存区域。
内核同时使用这两种数据结构,以保证内存区域相关操作的高性能。
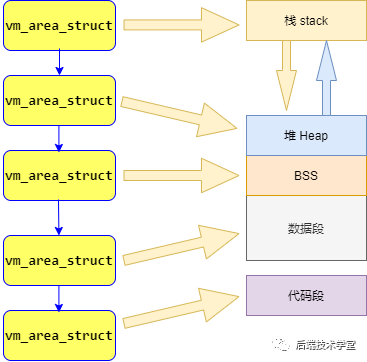
进程用户空间地址管理模型示意图
内核空间动态分配内存数据结构
在内核空间章节中提到,动态内存映射区的内存分配由 vmalloc() 函数完成。该函数分配的线性地址范围限于 vmalloc_start 与 vmalloc_end 之间。
每一块由 vmalloc() 函数分配的内核虚拟内存,都对应一个 vm_struct 结构体对象。为防止内存越界访问,不同的内核虚拟内存区域之间设置有 4 KB 大小的空闲隔离区。
与用户空间的虚拟地址类似,vmalloc() 函数分配的虚拟地址与物理内存之间没有简单的映射关系,必须通过内核页表才能转换为物理地址或物理页。这些虚拟地址对应的物理页可能尚未被分配,当进程访问这些地址时,会触发缺页异常,内核此时才会真正分配对应的物理页面。
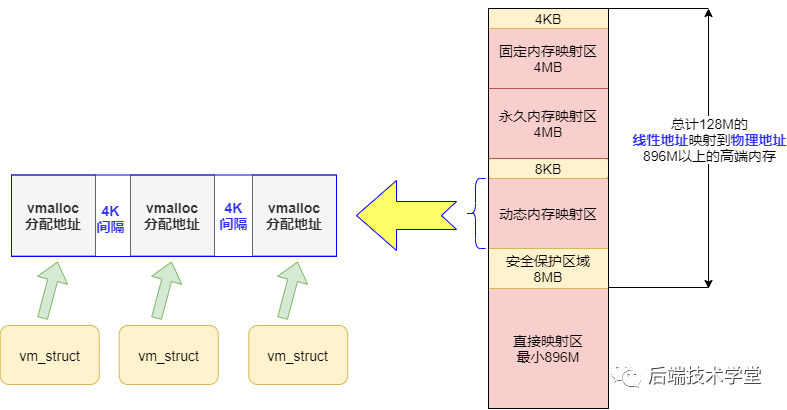
内核动态内存映射示意图
前文分析了 Linux 内存管理的整体机制,下文将深入探讨 物理内存管理 与 虚拟内存分配 的具体实现。
通过前文的学习可知,虚拟内存管理机制最终需要依托物理内存才能完成程序的运行。若无法为程序提供实际的物理内存资源,程序将无法正常执行。因此,物理内存作为硬件资源,必须通过高效的管理机制进行分配与使用(物理内存即计算机中安装的内存条)。
物理内存管理
在 Linux 系统中,通过分段与分页机制,物理内存被划分为大小为 4 KB 的内存页(也称为页框,Page Frame)。物理内存的分配与回收操作均以内存页为基本单位。物理内存分页管理的优势主要体现在以下两个方面:
- 当程序需要小块内存时,内核可预先分配一个内存页供其使用,避免了频繁申请和释放小块内存带来的系统开销。
- 当程序需要大块内存时,内核可通过多个内存页的拼接来满足需求,无需寻找连续的大块物理内存区域。
尽管分页管理机制具备上述优势,但直接采用分页方式管理物理内存,在实际运行过程中仍会面临一些问题。下文将分析系统在多次分配与释放物理页时遇到的问题。
物理页管理面临的问题
物理内存页的分配与释放过程中,会产生外部碎片与内部碎片两类问题。此处的「内部」与「外部」是相对于页框而言的:页框内部未被使用的内存空间称为内部碎片;页框之间分散的、无法被有效利用的小内存块称为外部碎片。
外部碎片
当程序需要分配大块内存时,内核需要为其分配多个连续的物理内存页。频繁的内存分配与回收操作,会导致大量的小容量空闲内存块夹杂在已分配的内存页之间。这些小内存块由于地址不连续,无法满足程序对大块连续内存的需求,从而形成外部碎片。

物理内存外部碎片示意图
内部碎片
物理内存的分配以页框为基本单位,当程序实际需要的内存容量小于一个页框的大小时,内核仍会为其分配一个完整的页框。页框中未被程序使用的内存空间,即为内部碎片。在内核中,存在大量需要以字节为单位分配内存的场景,此时内部碎片的问题会尤为突出。
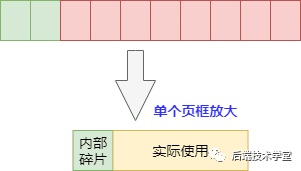
物理内存内部碎片示意图
页面管理算法
为解决物理内存管理中的碎片问题,Linux 内核引入了两种经典的页面管理算法,分别为伙伴分配算法与 slab 分配器。
Buddy(伙伴)分配算法
Linux 内核引入伙伴系统算法(Buddy System)来解决物理内存的外部碎片问题。该算法的设计思路是:将相同大小的空闲页框块组织为链表,这些页框块如同手拉手的伙伴,该算法也因此得名。
具体实现上,伙伴系统将所有空闲页框划分为 11 个块链表,每个块链表中的页框块大小分别为
2
0
2^0
20、
2
1
2^1
21、
2
2
2^2
22、…… 、
2
10
2^{10}
210 个连续页框,对应的内存容量分别为 4 KB、8 KB、16 KB、…… 、4 MB。最大可分配的连续内存容量为
2
10
2^{10}
210 个页框,即 4 MB。
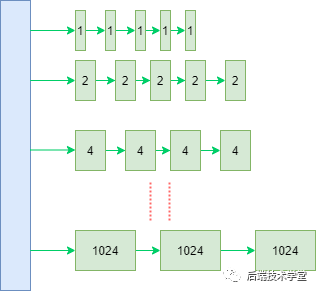
伙伴系统内存块组织示意图
由于任意正整数都可以表示为若干个 2 n 2^n 2n 数的和,因此伙伴系统总能找到合适大小的内存块为程序分配,从而有效减少外部碎片的产生。
分配实例
假设程序需要申请 4 个连续的页框(16 KB 内存),伙伴系统的分配流程如下:
- 首先检查大小为 4 个页框的空闲块链表,若存在空闲块,则直接分配。
- 若该链表中无空闲块,则检查更大一级的空闲块链表(8 个页框大小)。
- 从 8 个页框大小的空闲块链表中取出一个块,将其拆分为两个 4 个页框大小的块。
- 将其中一个块分配给程序,另一个块加入 4 个页框大小的空闲块链表中。
内存释放时,伙伴系统会检查释放的页框块的前后相邻页框块是否为空闲状态。若相邻页框块空闲且大小相同,则将它们合并为一个更大的页框块,并加入对应大小的空闲块链表中。
命令查看
在 Linux 系统中,可通过查看 /proc/buddyinfo 文件来获取伙伴系统的空闲内存块信息,示例如下:
[lemon ~]# cat /proc/buddyinfo
Node 0, zone DMA 1 0 0 0 2 1 1 0 1 1 3
Node 0, zone DMA32 3198 4108 4940 4773 4030 2184 891 180 67 32 330
Node 0, zone Normal 42438 37404 16035 4386 610 121 22 3 0 0 1
slab 分配器
伙伴系统有效解决了物理内存的外部碎片问题,但无法解决内部碎片问题,同时在处理小内存分配场景时效率较低。为弥补伙伴系统的不足,Linux 内核引入了 slab 分配器。
slab 分配器的设计目标是:针对内核中的小对象进行高效的内存分配与管理,通过缓存机制减少内存碎片,提升内存分配性能。
内核中存在大量需要频繁创建和释放的小对象,例如文件描述符结构体 file_struct、进程控制块结构体 task_struct 等。若采用伙伴系统为这些小对象分配内存,会产生大量的内部碎片,同时频繁的内存分配与释放操作会带来较大的系统开销。
slab 分配器通过按对象类型划分内存空间的方式,为内核对象提供专用的内存缓存。伙伴系统与 slab 分配器并非替代关系,而是互补关系:slab 分配器基于伙伴系统分配的内存页,进一步划分出更细粒度的内存空间,用于存放内核小对象。
设计原理
对于内核中每种类型的小对象,slab 分配器都会创建一个对应的 slab 缓存池。缓存池中存放着大量已初始化的空闲对象。当程序需要申请该类型的对象时,直接从缓存池中分配一个对象;当程序释放该对象时,将其重新放回缓存池,而非直接归还给伙伴系统。通过这种缓存机制,不仅避免了内部碎片的产生,还大幅提升了内存分配与释放的效率。
主要优势
- 减少内部碎片:slab 分配器基于内核小对象的大小划分内存空间,避免了伙伴系统按页分配带来的内部碎片问题,提高了内存利用率。
- 提升分配效率:通过缓存已初始化的内核对象,减少了内存分配与释放的次数,避免了频繁调用伙伴系统的开销,提升了系统性能。
数据结构
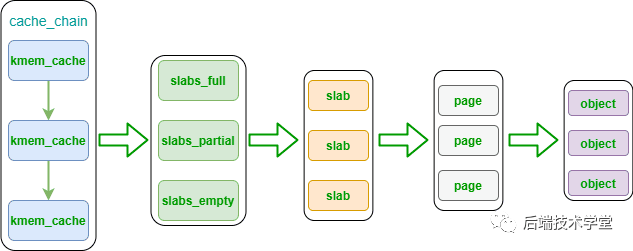
slab 分配器数据结构示意图
kmem_cache 是 slab 分配器的核心数据结构,它是 cache_chain 链表的节点,代表一种特定类型内核对象的高速缓存池。每个 kmem_cache 对应一段连续的内存块,该内存块被划分为多个大小相同的 slab,这些 slab 又被组织为以下 3 种链表:
slabs_full:完全分配的 slab 链表,链表中的 slab 已无空闲对象。slabs_partial:部分分配的 slab 链表,链表中的 slab 仍有空闲对象。slabs_empty:空闲 slab 链表,链表中的 slab 无已分配对象。
kmem_cache 结构体中包含一个 kmem_list3 结构体成员,该成员用于管理上述 3 个 slab 链表。

kmem_list3 结构体内核源码示意图
slab 是 slab 分配器的最小管理单位,一个 slab 通常由一个或多个连续的物理内存页组成(多数情况下为一个页)。slab 可以在不同的链表之间移动,例如当一个 slabs_partial 链表中的 slab 被分配完所有对象后,该 slab 会被从 slabs_partial 链表中移除,并加入 slabs_full 链表。
内核从 slab 缓存池中分配对象的流程如下:
- 检查
slabs_partial链表,若存在空闲对象,则直接分配。若分配后该 slab 无空闲对象,则将其移动至slabs_full链表。 - 若
slabs_partial链表无空闲对象,则检查slabs_empty链表。 - 若
slabs_empty链表存在空闲 slab,则从该 slab 中分配对象,并将该 slab 移动至slabs_partial链表。 - 若
slabs_empty链表为空,则调用伙伴系统分配新的物理内存页,创建一个新的 slab,并将其加入slabs_empty链表,随后执行步骤 3。
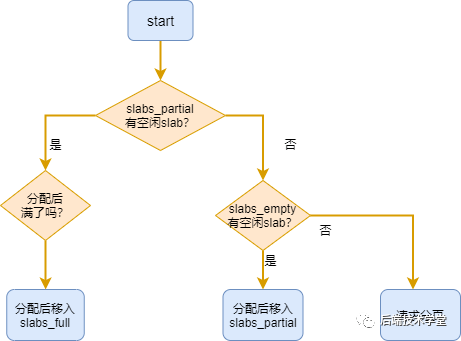
slab 分配器对象分配流程示意图
命令查看
在 Linux 系统中,可通过以下命令查看 slab 分配器的运行状态:
-
cat /proc/slabinfo:查看系统中所有 slab 缓存池的详细信息,包括缓存池名称、对象数量、内存占用等。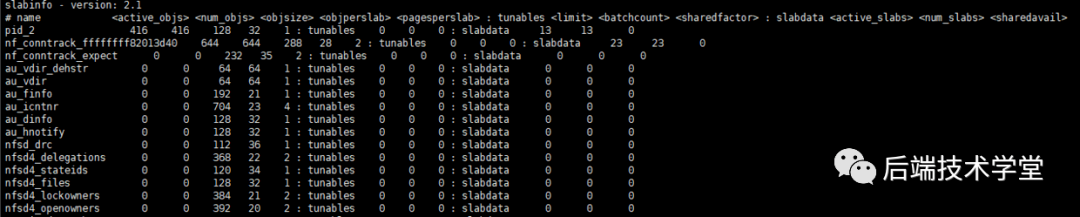
slabinfo 文件内容示意图
-
slabtop:实时显示内核 slab 内存缓存的使用情况,按内存占用大小排序。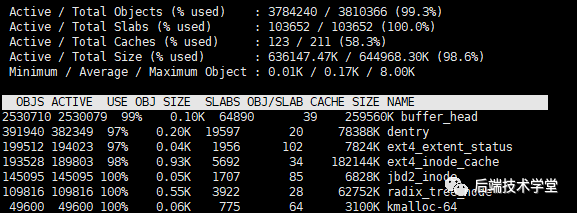
slabtop 命令输出示意图
slab 高速缓存的分类
slab 高速缓存分为通用高速缓存与专用高速缓存两大类。
通用高速缓存
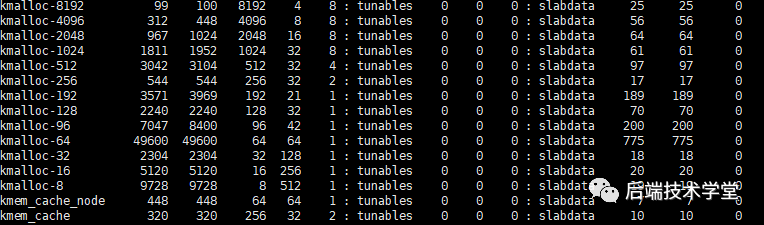
通用高速缓存用于存放内核中通用的小内存块,其管理的对象大小呈几何分布,范围为 32 字节 ~ 131072 字节。kmem_cache 结构体本身的内存分配也由通用高速缓存完成,cache_cache 是用于存放 kmem_cache 对象的通用高速缓存,位于 cache_chain 链表的头部。
内核提供 kmalloc() 与 kfree() 两个接口,用于从通用高速缓存中申请和释放内存。
专用高速缓存
专用高速缓存用于存放特定类型的内核对象,例如 task_struct、file_struct 等。内核为专用高速缓存的创建与销毁提供了一套完整的接口:
kmem_cache_create():创建一个专用高速缓存,该函数从cache_cache通用高速缓存中分配kmem_cache结构体,并将其加入cache_chain链表。kmem_cache_destroy():销毁一个专用高速缓存,并将其从cache_chain链表中移除。
内核从专用高速缓存中分配和释放对象的接口为:
kmem_cache_alloc():从指定的专用高速缓存中分配一个对象。kmem_cache_free():将一个对象释放回指定的专用高速缓存。
slab 结构体在内核中的定义如下:

slab 结构体内核代码示意图
虚拟内存分配
前文讨论的是物理内存的管理机制,而 Linux 虚拟内存管理的设计思路在于为进程提供独立的虚拟地址空间。本节将探讨虚拟内存的分配方式,包括用户空间虚拟内存与内核空间虚拟内存的分配。
注意:虚拟内存的分配仅为进程分配虚拟地址空间,此时并未建立与物理内存的映射关系。只有当进程访问已分配的虚拟地址时,才会触发缺页异常,内核随后通过伙伴系统与 slab 分配器为其分配对应的物理内存。
用户空间内存分配
用户空间虚拟内存的分配主要通过 malloc() 函数实现,该函数是 C 标准库提供的内存分配接口。
malloc 分配机制
malloc() 函数的内存分配策略与申请的内存大小相关:
- 当申请的内存大小小于
128 KB时,malloc()使用brk()或sbrk()系统调用分配内存。这两个函数通过调整进程堆的顶指针,实现堆空间的扩张与收缩。 - 当申请的内存大小大于等于
128 KB时,malloc()使用mmap()系统调用分配内存。该函数通过在进程的文件映射区创建匿名映射,为进程分配虚拟内存空间。
存在问题
- 系统调用开销:
brk()、sbrk()与mmap()均为系统调用,每次调用都需要进行用户态与内核态的切换。若进程频繁申请和释放小内存,会产生大量的系统调用开销,降低程序运行效率。 - 内存碎片问题:堆空间的扩展方向是从低地址到高地址,若低地址的内存未被释放,高地址的内存即使被释放也无法被回收,从而导致堆空间产生内存碎片。
解决方案
为解决上述问题,malloc() 采用内存池机制进行优化。其设计思路是:预先向内核申请一大块内存作为内存池,将内存池划分为不同大小的内存块。当进程申请内存时,直接从内存池中选择一块大小相近的内存块分配给进程;当进程释放内存时,将内存块归还给内存池,而非直接归还给内核。通过这种方式,减少了系统调用的次数,降低了内存碎片的产生。
malloc 内存池机制示意图
内核空间内存分配
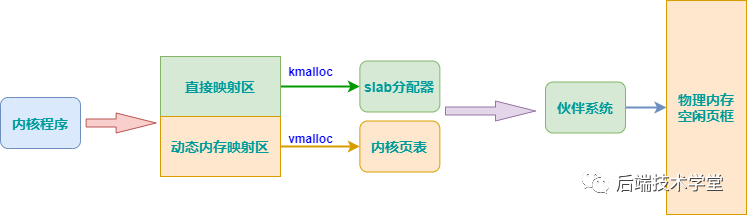
在讨论内核空间内存分配之前,首先回顾内核地址空间的布局。内核空间的虚拟内存分配主要通过 kmalloc() 与 vmalloc() 两个函数实现,这两个函数分别对应内核空间的不同映射区域。
内核空间细分区域示意图
kmalloc
kmalloc() 函数用于在内核空间的直接内存映射区分配虚拟内存。其特点如下:
- 分配粒度:以字节为单位分配虚拟内存,适用于分配小块内存。
- 物理连续性:分配的虚拟内存对应的物理内存是连续的。
- 释放接口:对应的内存释放函数为
kfree()。 - 实现基础:
kmalloc()基于 slab 分配器实现,其分配的内存来自 slab 通用高速缓存。 - 适用场景:主要用于设备驱动程序等内核模块中,为数据结构分配内存。
在 Linux 系统中,可通过 cat /proc/slabinfo 命令查看 kmalloc 相关的 slab 缓存信息,例如 kmalloc-8、kmalloc-16 等,这些缓存分别对应不同大小的内存块。
kmalloc 相关 slab 缓存信息示意图
vmalloc
vmalloc() 函数用于在内核空间的动态内存映射区分配虚拟内存。其特点如下:
- 分配粒度:适用于分配大块内存。
- 物理连续性:分配的虚拟内存地址是连续的,但对应的物理内存地址不一定连续。
- 释放接口:对应的内存释放函数为
vfree()。 - 适用场景:主要用于为活动的交换区分配数据结构、为 I/O 驱动程序分配缓冲区,或为内核模块分配内存空间。
下图总结了 kmalloc() 与 vmalloc() 两种内核空间虚拟内存分配方式的差异:
kmalloc 与 vmalloc 分配方式对比示意图
总结
Linux 内存管理是一个极其复杂的系统,本文所介绍的内容仅为该系统的冰山一角。本文从宏观角度为读者展现了 Linux 内存管理的整体框架,这些知识足以满足技术面试与日常开发的基本需求。若读者希望深入学习,可参考内核源码与专业书籍,进一步研究内存管理的底层实现细节。
via:
- Memory Management Techniques In Operating System
https://er.yuvayana.org/memory-management-techniques-in-operating-system/ - 20 张图揭开「内存管理」的迷雾,瞬间豁然开朗_内存管理图解-优快云博客
https://blog.youkuaiyun.com/qq_34827674/article/details/107042163 - 万字长文,别再说你不懂Linux内存管理了(合辑),30张图给你安排的明明白白
https://www.eet-china.com/mp/a102208.html

















 4824
4824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









