




注:本文为两篇关于当前大模型方向讨论的文章。
OpenAI 大改下代大模型方向,scaling law 撞墙?AI 社区炸锅了
机器之心 2024 年 11 月 11 日 11:57 北京
机器之心报道
编辑:Panda、泽南
大模型的 scaling law 到头了?行业龙头 OpenAI 在转换策略。
有研究预计,如果 LLM 保持现在的发展势头,预计在 2028 年左右,已有的数据储量将被全部利用完。届时,基于大数据的大模型的发展将可能放缓甚至陷入停滞。
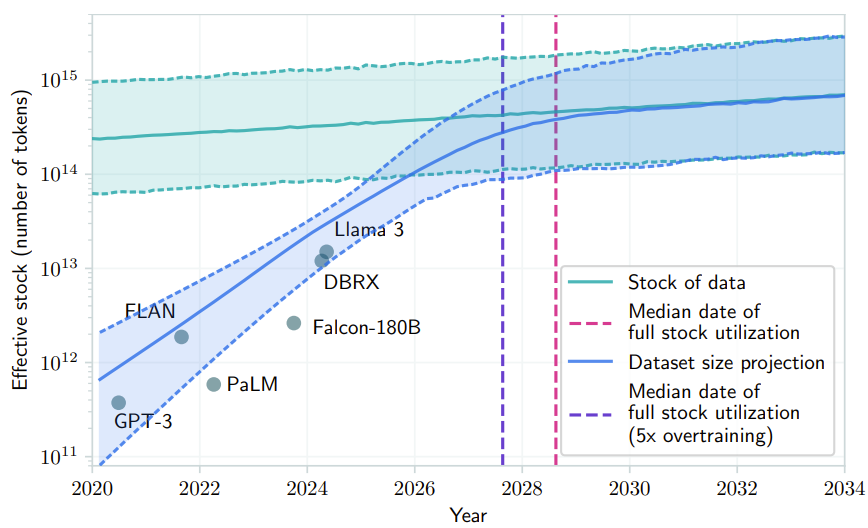
- 来自论文《Will we run out of data? Limits of LLM scaling based on human-generated data》*
但似乎我们不必等到 2028 年了。昨天,The Information 发布了一篇独家报道《随着 GPT 提升减速,OpenAI 改变策略》,其中给出了一些颇具争议的观点:
-
OpenAI 的下一代旗舰模型的质量提升幅度不及前两款旗舰模型之间的质量提升;
-
AI 产业界正将重心转向在初始训练后再对模型进行提升;
-
OpenAI 已成立一个基础团队来研究如何应对训练数据的匮乏。
文章发布后,热议不断。OpenAI 著名研究科学家 Noam Brown 直接表示了反对(虽然那篇文章中也引用了他的观点)。他表示 AI 的发展短期内并不会放缓。并且他前些天还在另一篇 X 推文中表示,对于 OpenAI CEO 山姆・奥特曼的 AGI 发展路径已经清晰的言论(「事情的发展速度将比人们现在预想的要快得多」),OpenAI 的大多数研究者都表示比较认同。
著名 X 博主 @apples_jimmy 甚至直斥之为 Fake News,毕竟奥特曼说过 AGI 很快就要实现了。
OpenAI 的 Adam GPT 则给出了更详细的反对意见。他表示大模型的 scaling laws 和推理时间的优化是两个可以互相增益的维度。也就是说就算其中一个维度放缓,也不能得出 AI 整体发展放缓的结论。
OpenAI 产品副总裁 Peter Welinder 也认同上述看法。
当然,也有人认同 The Information 这篇文章的观点,比如一直有类似观点的 Gary Marcus 表示这篇文章宣告了自己的胜利。

数据科学家 Yam Peleg 也表示某前沿实验室的 scaling laws 出现了巨大的(HUGE)受益递减问题。

大多数吃瓜群众基本认同 OpenAI 相关人士公开发布的意见,毕竟该公司虽然存在无数的争议和八卦,但目前仍旧是当之无愧的行业领导者。也就是说,相比于媒体揣测,OpenAI 的话会更可信一些。
不过有意思的是,The Information 这篇报道也宣称很多信息来自 OpenAI 内部员工和研究者。当然,该媒体没有给出具体的信息源。下面我们就来看看这篇引发广泛的争议的报道究竟说了什么。
使用 ChatGPT 和其他人工智能产品的人数正在飙升。不过,支撑这些产品的基本构建模块的改进速度似乎正在放缓。
为了弥补这种减速,OpenAI 正在开发新技术来增强这些构建模型,即大型语言模型。
据一位知情人士透露,尽管 OpenAI 只完成了 Orion 训练过程的 20%,但奥特曼表示,在智能和完成任务和回答问题的能力方面,它已经与 GPT-4 不相上下。
据一些使用或测试过 Orion 的 OpenAI 员工称,虽然 Orion 的性能最终会超过之前的型号,但相比于该公司发布的最新两款旗舰模型 GPT-3 和 GPT-4 之间的飞跃,质量的提升要小得多。
据这些员工称,该公司的一些研究者认为,在处理某些任务方面,Orion 并不比其前代模型更好。据 OpenAI 的一名员工称,Orion 在语言任务上表现更好,但在编程等任务上可能不会胜过之前的模型。其中一位员工表示,这可能是一个问题,因为与 OpenAI 之前发布的其他模型相比,Orion 在 OpenAI 数据中心运行的成本可能更高。
Orion 的情况可以检验人工智能领域的一个核心假设,即 scaling laws:只要有更多数据可供学习,并有更多的计算能力来促进训练过程,LLM 就能继续以相同的速度提升性能。
为了应对近期 GPT 提升放缓对基于训练的 scaling laws 带来的挑战,AI 行业似乎正在将精力转向训练后对模型进行改进,这可能会产生不同类型的 scaling laws。
包括 Meta 的马克・扎克伯格在内的一些 CEO 表示,在最坏的情况下,即使当前技术没有进步,仍有很大空间在现有技术的基础上构建消费者和企业产品。
例如,OpenAI 正忙于将更多的编程功能融入其模型中,以抵御来自竞争对手 Anthropic 的重大威胁。后者正在开发一种软件,其可以接管用户电脑,通过像人类一样执行点击、光标移动、文本输入来使用不同的应用程序,从而完成涉及网络浏览器活动或应用程序的白领工作。
这些产品是向处理多步骤任务的 AI 智能体迈进的一部分,可能与 ChatGPT 最初发布时一样具有革命性。
此外,扎克伯格、奥特曼和其他 AI 开发商的首席执行官也公开表示,他们尚未达到传统 scaling laws 的极限。因此,OpenAI 等公司仍在开发昂贵的、价值数十亿美元的数据中心,以尽可能多地提升预训练模型的性能。
然而,OpenAI 研究者 Noam Brown 上个月在 TEDAI 大会上表示,更先进的模型可能在经济上不可行。
「毕竟,我们真的要花费数千亿美元或数万亿美元训练模型吗?」 Brown 说。「在某个时候,scaling 范式会崩溃。」
OpenAI 尚未完成对 Orion 的安全性的漫长测试过程。其员工们表示,OpenAI 明年初发布 Orion 时,可能不再采用其旗舰模型的传统「GPT」命名惯例,进一步凸显 LLM 改进方式的变化。(OpenAI 发言人没有对此发表评论。)
撞上数据南墙
OpenAI 员工和研究者表示,GPT 速度放缓的原因之一是高质量文本和其他数据的供应量正在减少,而这些数据是 LLM 预训练所必需的。
他们表示,在过去几年中,LLM 使用来自网站、书籍和其他来源的公开文本和其他数据进行预训练,但模型开发者基本上已经从这类数据中榨干了尽可能多的资源。
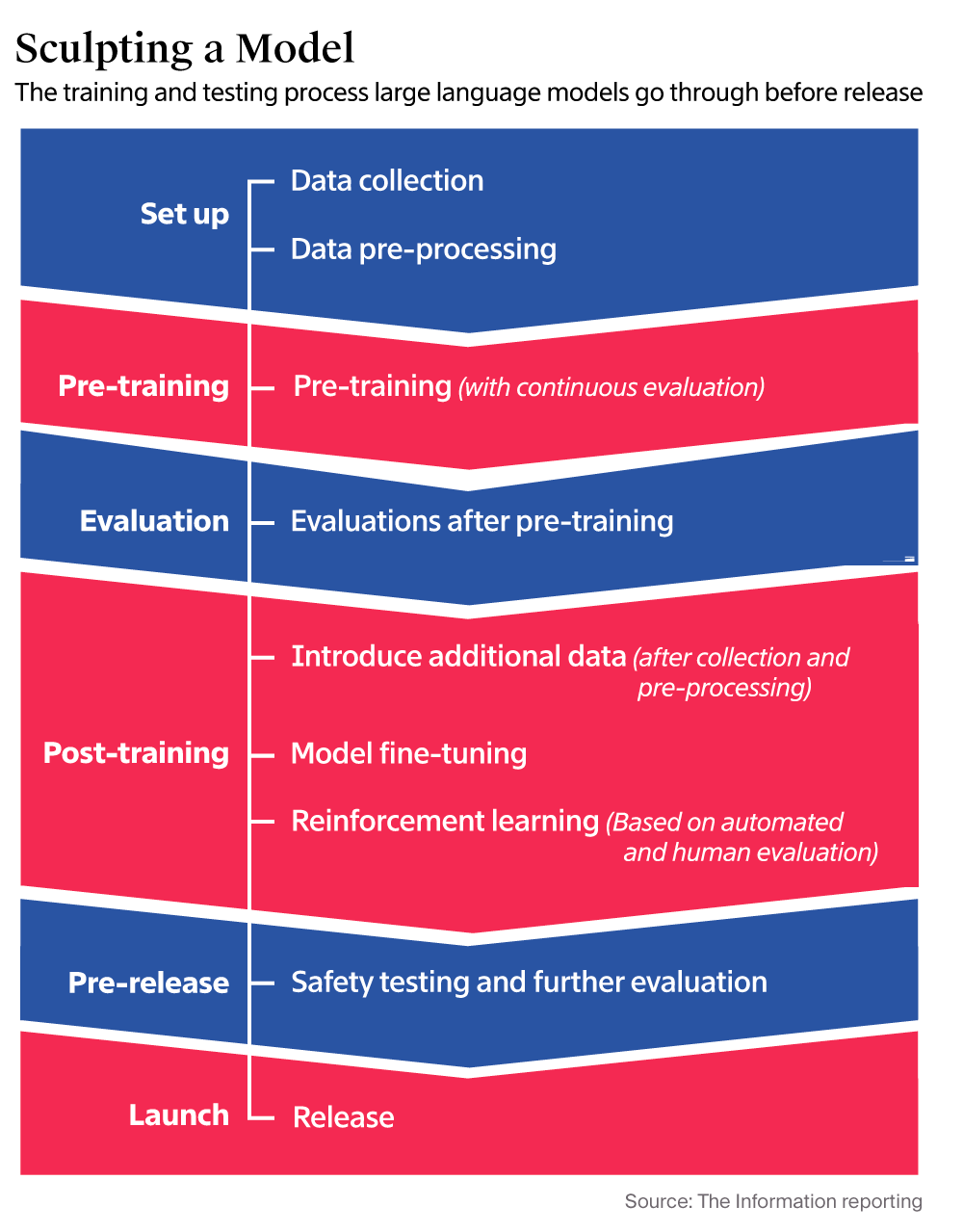
作为回应,OpenAI 成立了一个基础团队,由之前负责预训练的 Nick Ryder 领导。他们表示,该团队将研究应对训练数据的匮乏,以及大模型的扩展定律将持续到什么时候。
据 OpenAI 的一名员工称,Orion 部分接受了 AI 生成的数据的训练,这些数据由其他 OpenAI 模型生成,包括 GPT-4 和最近发布的推理模型。然而,这位员工表示,这种合成数据导致了一个新问题,即 Orion 最终可能会在某些方面与那些旧模型相似。
风险投资人 Ben Horowitz 表示:「我们正在以同样的速度增加『用于训练 AI 的 GPU 数量』,但我们并没有从中获得任何智能改进。」
OpenAI 研究人员正在利用其他工具在训练后过程中改进 LLM,通过改进它们处理特定任务的方式。研究人员通过让模型从大量已被正确解决的问题(如数学或代码问题)中学习来实现这一目标,这一过程称为强化学习。
他们还要求人类评估人员在特定的代码或复杂问题任务上测试预训练模型,并对答案进行评分,这有助于研究人员调整模型以改进其对某些类型请求(例如写作或代码)的回答水平。这个过程称为带有人类反馈的强化学习(RLHF),也为较旧的人工智能模型提供了帮助。
为了处理这些评估,OpenAI 和其他人工智能开发人员通常依靠 Scale AI 和 Turing 等初创公司来管理数千名承包商。
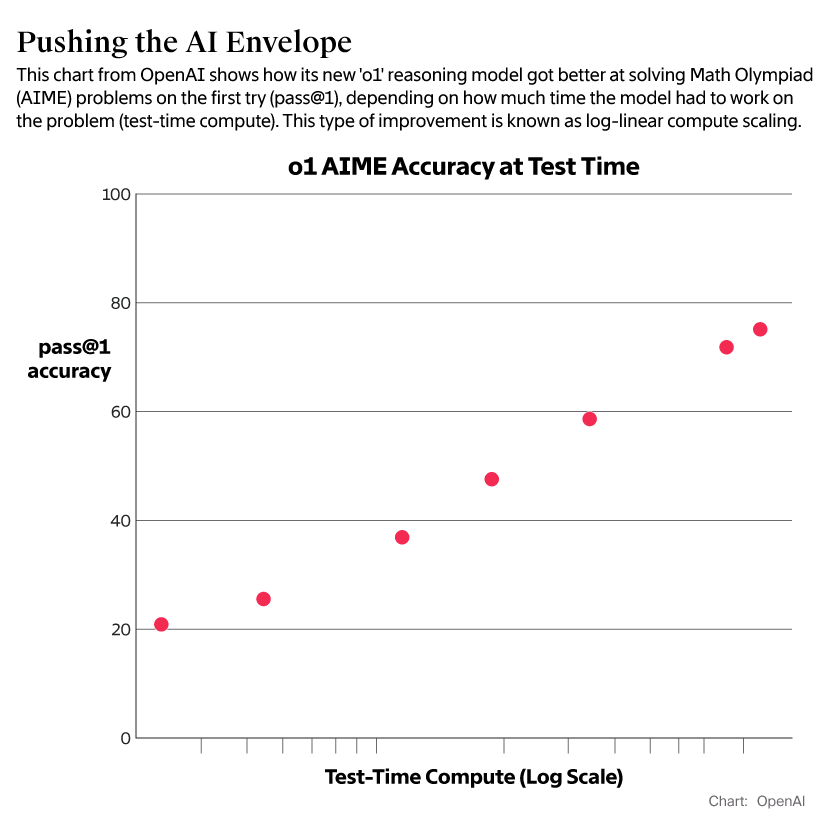
随着 OpenAI 技术的演进,研究人员继续开发出了名为 o1 的推理模型,该模型需要更多时间「思考」LLM 训练的数据,然后才能给出答案,这一概念称为测试时间计算。
这意味着,如果在模型回答用户问题时为其提供额外的计算资源,即使不更改底层模型,o1 的响应质量也可以继续提高。一位了解这一过程的人士表示,如果 OpenAI 能够不断提高底层模型的质量,即使速度较慢,也能产生更好的推理结果。
「这为大模型的扩展开辟了一个全新的维度,」Brown 在 TEDAI 会议上表示。研究人员可以通过将「每个查询花费一分钱提到每个查询花费一毛钱」来改善模型响应。
奥特曼也强调了 OpenAI 推理模型的重要性,它可以与 LLM 相结合。
「我希望推理能解锁很多我们等待多年的事情 —— 例如,像这样的模型能够为科学研究做出贡献,帮助编写更多非常困难的代码,」奥特曼在 10 月的一次应用开发者活动中说道。
在最近接受 Y Combinator 首席执行官 Garry Tan 采访时,奥特曼表示,「我们基本上知道该怎么做」才能实现通用人工智能,即与人类智力相当的技术 —— 其中的一部分涉及「以创造性的方式使用现有模型」。
数学家和其他科学家表示,o1 对他们的工作很有帮助,因为它可以充当可以提供反馈或想法的伙伴。但两位了解情况的员工表示,该模型目前的价格比非推理模型高出六倍,因此它还没有广泛的客户群。
「突破渐近线」
一些向人工智能开发者投入了数千万美元的投资者怀疑,大语言模型的进步速度是否开始趋于平稳。
Ben Horowitz 的风险投资公司已经投资了 OpenAI、Mistral 和 Safe Superintelligence 等公司,他在 YouTube 频道里表示:「我们正在以同样的速度增加『用于训练人工智能的 GPU』的数量,但我们根本没有从中获得智能改进。」
Horowitz 的同事 Marc Andreessen 在同一视频中则表示,「有很多聪明人正在努力突破渐近线,想办法达到更高水平的推理能力。」
企业软件公司 Databricks 的联合创始人兼主席联合开发者 Ion Stoica 表示,大模型的表现可能在某些方面已经停滞,但在其他方面仍在进步。
Stoica 表示,尽管大模型在代码和解决复杂、多步骤问题等任务方面不断改进,但其在执行通用任务(如分析一段文本的情感或描述医疗问题的症状)方面似乎进展缓慢。
「对于常识性问题,你可以说,目前我们看到 LLM 的表现停滞不前。我们需要 [更多] 事实数据,而合成数据没有太大帮助,」他说道。
你觉得 AI 发展的 scaling laws 速度放缓了吗?推理时间计算能否成为新的性能提升来源?请与我们分享你的观点。
参考链接:
https://www.theinformation.com/articles/openai-shifts-strategy-as-rate-of-gpt-ai-improvements-slows
https://www.youtube.com/watch?v=xXCBz_8hM9w
https://arxiv.org/abs/2211.04325
https://www.youtube.com/watch?v=hookUj3vkE4
© THE END
GPT-5 被曝不及预期,OpenAI 员工:没什么科学突破了,接下来只需要工程
量子位 2024 年 11 月 11 日 13:04 北京 梦晨 发自 凹非寺 量子位 | 公众号 QbitAI
猛料来了,OpenAI 下一代旗舰模型被曝提升不如预期。
消息来自 The Information,具体指代号**“猎户座”**(Orion)的模型相对 GPT-4 的提升幅度,小于 GPT-4 相对 GPT-3,已进入收益递减阶段。
或许这也是奥特曼曾说,可能不会把新模型命名为 GPT-5 的原因之一。

消息一出,著名悲观派学者 Gary Marcus 直接半场开香槟,宣布自己胜利。

在更详细的一篇文章中,他认为整个 AI 行业公司的高估值建立在模型能力不断增强、迅速达到 AGI 的预期之上。
如果改进放慢了,多数 AI 公司都能赶上最前沿模型的水平。从此行业进入价格战,收入保持在低位。同时因芯片成本高昂,利润也将难以获得。
当每个人都意识到这一点时,金融泡沫可能会迅速破灭,即使是英伟达也可能受到打击。

并且遇到瓶颈的或许不只是 OpenAI,此前 Anthropic 没有如期发布 Claude 3.5 Opus,并且从官网删除了相关描述。
以及谷歌 Gemini 2 虽然计划很快发布,但也被曝性能提升也不及 DeepMind 创始人的预期。

大模型 Scaling Law 真的撞墙了吗?
“猎户座” 被曝不及预期,奥特曼:AGI 2025
根据目前消息,长期跟踪 ChatGPT 进展和网页源码的 “光头哥” Tibor Blaho 总结如下:
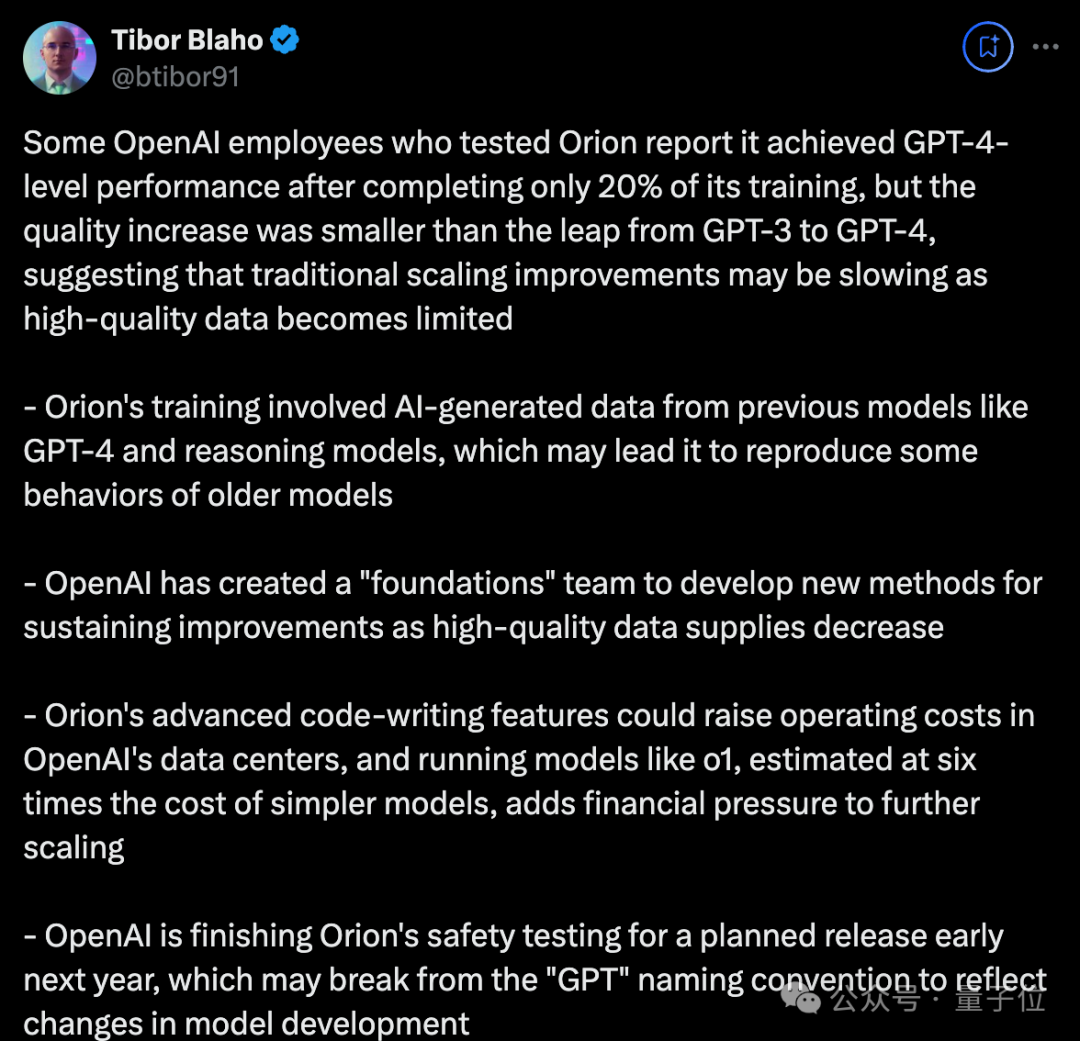
-
参与测试新模型的 OpenAI 员工称, “猎户座” 仅完成 20% 训练时就达到了 GPT-4 级别的性能。
-
但最终质量提升小于从 GPT-3 到 GPT-4 的飞跃,这表明传统的 Scaling 可能由于高质量数据变得有限而放缓。
-
训练 “猎户座” 使用了先前模型(GPT-4 和 o1)生成的数据,可能导致它重现旧模型的一些行为。
-
OpenAI 创建了一个 “基础团队”,在高质量数据供应减少的情况下寻找新方法。
-
o1 类模型成本是传统模型的 6 倍,“猎户座” 可能提高 OpenAI 数据中心的运营成本,进一步增加财务压力。
-
OpenAI 正在做 “猎户座” 的安全测试,计划于明年初发布,可能不会再命名为 GPT 系列
与此同时,从 OpenAI CEO 和许多资深员工那里,传来的却是不同的故事。
首先是奥特曼接受 YC 总裁 Garry Tan 采访,在回答最后一个问题**“2025 年什么会让你兴奋”时,脱口而出“AGI”**,没有半秒犹豫。

这段采访引起争议后,强化学习大牛 Noam Brown 发声:
我听人们说奥特曼只是在炒作,但从我的观察来看,他说的一切都符合 OpenAI 一线研究员的中位数观点。
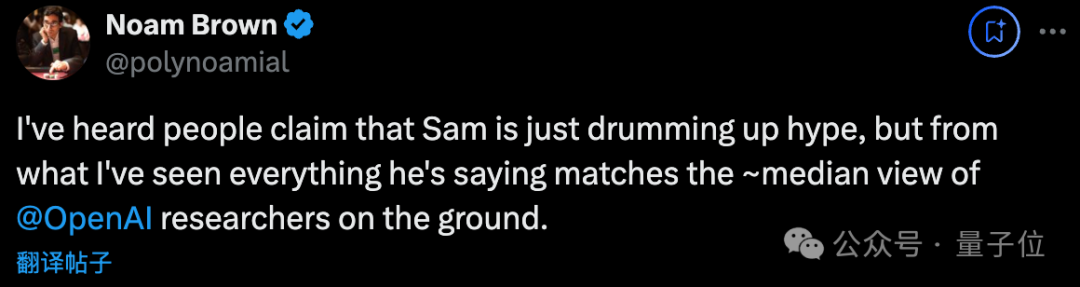
今年 1 月才入职 OpenAI 的特斯拉前工程师也表达了认同:
自从我加入以来,我的观点已经从 “这是毫无成效的炒作” 转变成 “AGI 基本就在这里”
恕我直言,接下来的科学创新会相对很少,将由多年的艰苦工程代替。

那么,究竟发生了什么?
在 Garry Tan 与奥特曼的对话中,两人从奥特曼早期在 YC 的经历,谈到 OpenAI 的创立、发展过程,以及给如今创业公司的建议等等。
在接近结束的时候,Garry Tan 抛出了这样的问题:你从去年秋天的动荡中学到了什么?你对一些人员离职有什么感受?
奥特曼回答:很累,但感觉很好。
ChatGPT 还不到两岁,我们有点像在两年内速通了中型甚至大型科技公司的发展历程,通常需要十年时间。
这带来了很多痛苦的事情。任何公司在扩张时,都会以某种速度经历管理团队的更替。擅长从 0 到 1 的人不一定适合从 1 到 10 或从 10 到 100 的阶段。
…… 我希望我们现在正走向一个更平稳的时期,但我确信将来还会有其他时期,事情会再次变化剧烈。
Garry Tan 接着提问:我想知道 OpenAI 现在运作的如何?目前的质量和推进速度如何?
奥特曼接下来的回答虽然一如既往的打太极,但引起很多关注:
这是我们第一次真正知道该做什么。构建 AGI 仍然需要大量的工作,有一些已知和未知,还需要一段时间,而且会很困难,但这非常令人兴奋。
…… 我们的研究路径相当清晰,我们的基础设施路径相当清晰,产品路径也越来越清晰…… 很长一段时间,我们都不是这样。

评论区网友显然不买账,有人怀疑这只是奥特曼在试图修改 AGI 的定义,按照合同,一旦董事会宣布 AGI 达成,就可以停止与微软分享技术了。
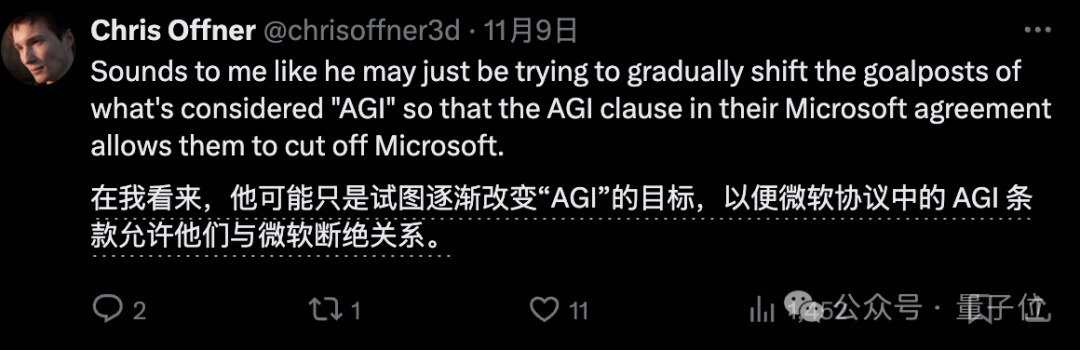
也有人指出,这无法解释最近 OpenAI 人才频繁出走。

对于人才流动,OpenAI 模型架构研究员 Rohan Pandey 表示并没有人们以为的那么严重。
今年早些时候 OpenAI 员工总数被曝已超过 1700,比去年董事会叛变时期增加了上千人。

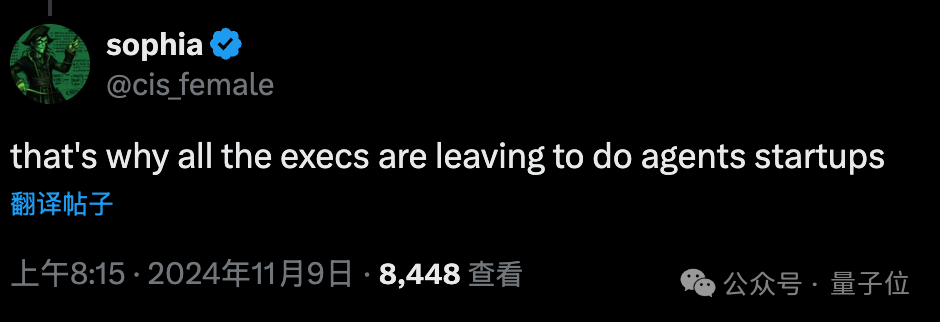
也有网友认为,反过来也说得通:
OpenAI 高管看到技术进展很快,所以提前离开去创办 AI 智能体公司。
参考链接:
[1] https://www.theinformation.com/articles/openai-shifts-strategy-as-rate-of-gpt-ai-improvements-slows
[2] https://www.youtube.com/watch?v=xXCBz_8hM9w
[3] https://garymarcus.substack.com/p/confirmed-llms-have-indeed-reached
[4] https://www.theverge.com/2024/10/25/24279600/google-next-gemini-ai-model-openai-december
[5] https://x.com/btibor91/status/1855381376054251654
—完—
OpenAI 怒斥 Scaling 撞墙论!o1 已产生推理直觉潜力巨大
机器学习研究组订阅 2024 年 11 月 25 日 19:24 山西
最近,OpenAI 高级研究副总裁 Mark Chen 在炉边谈话中,正式否认「Scaling Law 撞墙论」。
他表示,并没有看到 Scaling Law 撞墙,甚至 OpenAI 还有两个范例 ——o 系列和 GPT 系列,来保持这种 Scaling。
用他的话说,「我们准确地掌握了需要解决的技术挑战」。

o1 不仅是能力提升,也是安全改进
从经济角度看,OpenAI 已经是最有价值的科技公司之一,因为他们为真实用户提供了数十亿美元的价值。
两年前,AI 最前沿的任务还是小学数学题;而今天,它们已经可以做最难的博士生题目。
因此,我们正处于这样一个阶段:AI 模型能够解决人类有史以来最困难的考试。
一旦这些模型解决了博士级别的问题,下一步,即使为世界提供实用性和价值。
当所有基准测试饱和之后,需要考虑的就是是否为最终用户提供了价值。
虽然今天 AI 通过了基准测试,但它并没有完全捕捉到 AGI 应该做的事。
好在,在过去一年里,OpenAI 内部发生了最令人兴奋的进展 ——o1 诞生了。
这不仅是一种能力上的提升,从根本上来说也是一种安全改进。
为什么这么说?
想象我们试图对一个模型进行越狱,旧的 GPT 系统必须立即做出回应,所以可能更容易被触发。
但当我们有一个推理器时,模型却会反思:这个问题是不是试图让我做一些与我要做的不一致的事?
此时,它获得的额外思考和反思的时间,会让它在很多安全问题上更稳健。
这也符合 OpenAI 研究者最初的预期。
当我们谈到推理时,这是一个广泛的概念,不仅仅用于数学或编程。
在编程中使用的推理方法,可能也适用于谈判,或者玩一个很难的游戏。
而说到基准测试,在安全性上也有同样的挑战。
安全性有点类似于这种对抗性攻击框架。在这种情况下,攻击是非常强烈的,因此我们在这方面还有很长的路要走。
如何到达五级 AGI
AGI 从一级到五级,关键推动因素是什么呢?
OpenAI 提出的框架中,定义了 AGI 的不同级别,具体来说,就是从基本推理者发展到更智能的系统,再到能在现实世界里采取行动的模型,最终到达更自主、完全自主的系统。

在这个过程中,稳健性和推理能力是关键。
今天我们还不能依赖很多智能体系统,原因是它们还不够可靠。这就是 OpenAI 押注推理能力的原因。
OpenAI 之所以大量投资,就是对此极有信心:推理能力将推动可靠性和稳健性。
所以,我们目前正处于哪一阶段呢?
OpenAI 研究者认为,目前我们正从第一阶段向第二阶段过渡,朝着更智能系统的方向发展。
虽然目前,许多智能体系统仍然需要人类监督,但它们已经变得越来越自主。模型可以自行原作,我们对于 AI 系统的信任也在逐渐增加。
合成数据的力量
合成数据,就是不由人类直接产生的数据,而是模型生成的数据。
有没有什么好的方法,来生成用于训练模型的合成数据呢?
我们在数据稀缺或数据质量较低的数据集中,可以看到合成数据的力量。
比如,在训练像 DALL-E 这样的模型时,就利用了合成数据。

训练图像生成模型的一个核心问题是,当我们去看互联网上带标题的图片时,标题和它所描述的图片之间通常关联性很低。
你可能会看到一张热气球的照片,而标题并不是描述气球本身,而是「我度过最好的假期」之类的。
在 OpenAI 研究者看来,在这种情况下,就可以真正利用合成数据,训练一个能为图片生成高保真标题的模型。
然后,就可以为整个数据集重新生成捕获了,OpenAI 已经证明,这种方法非常有效。
数据集中某方面较差的其他领域,也可以采用这个办法。
Scaling Law 没有撞墙
最近很火热的一个观点是,Scaling Law 已经撞墙了,许多大型基础实验室都遇到了预训练的瓶颈。
果真如此吗?
Mark Chen 的观点是,虽然的确在预训练方面遇到一些瓶颈,但 OpenAI 内部的观点是,已经有了两种非常活跃的范式,让人生成无限希望。
他们探索了一系列模型的测试时 Scaling 范式,发现它们真的在迅速发展!
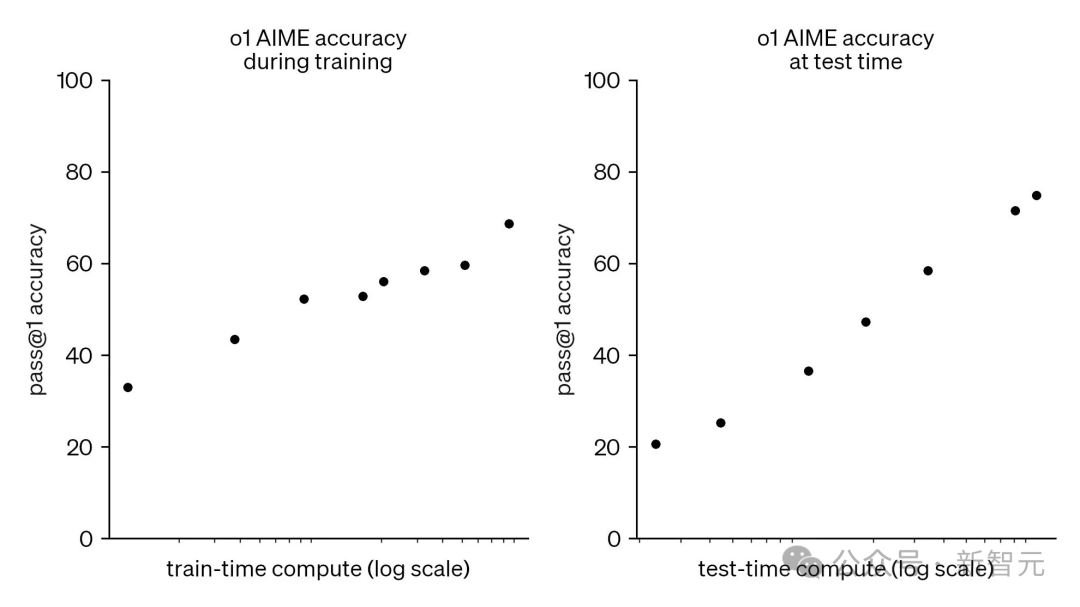
在推理模型的 Scaling 上,也没有同样的障碍。
其实,从早期入职 OpenAI 后,研究者就一直遇到多个技术挑战。现在这些挑战已经非常具体,在 Mark Chen 看来,没有什么是完全无法应对的。
在 OpenAI 内部,大家经常说推理范式已经达到了一定的成熟度。有些产品已经有了与市场的契合点,虽然进展仍然非常缓慢。
过去几周内,最令人惊讶的使用场景,莫过于和 o1 进行头脑风暴了。
o1 和 GPT-4 的对比,让人感受到了全新的深度:人类仿佛终于有了一个真正能互动的陪练伙伴,而非仅仅对自己的想法进行评论。
它仿佛一个真正的实体,非常有参与感。
**o1 的推理直觉,是如何产生的 **
OpenAI 的研究者,是如何想到 o1 中的推理直觉的呢?
这是一个集体努力的结果,不过他们也进行了很长时间的工作,进行了一些探索性的重点尝试。
在两年前,他们就觉得,AI 虽然非常聪明,但在某些方面是不足的。不知为什么,总是感觉不太像 AGI。
当时他们假设,原因在于,这是因为 AI 被要求立即做出回应。
就算我们要求一个人类立即做出回应,ta 也未必能给出最好的答案。
一个人可能会说,我需要思考一会,或者我需要做一些研究,明天再答复你。
就在这里,OpenAI 研究者发现了亮点!
其实这里缺少的,是连接系统一和系统二之间的鸿沟。
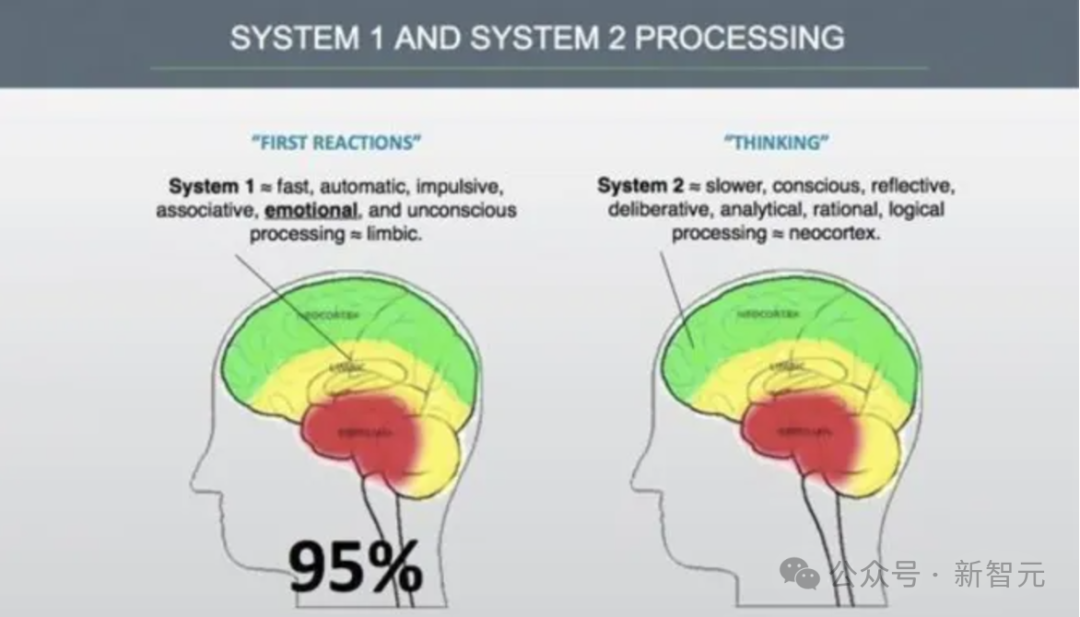
快速思考有,知识也有,但却没有慢速思考,核心假设就在这里。
研究者做了许多不同尝试,来解决这个挑战。
一群非常具有探索精神的研究者,获得了一些生命迹象。
围绕这些迹象,他们组建了研究团队,扩大的项目规模,投入了大量的数据生成工作。
从快速进展中获取预测结果,是整个案例中最难的部分。
开始时,就像登月计划一样,会遭遇很多失败。
有三四个月,他们完全没取得多少有意义的进展。
好在最终,总会有人获得重大突破。这也就给了他们足够的动力来投入更多资源,往前推动一点。
从 o1 推出几个月后,OpenAI 和许多外部合作伙伴进行了交流。
最酷的一件事就是,他们发现它比使用微调方法要好得多 —— 它已经不太容易被问题难倒了。
很多应用已经超出了研究者之前关注的数学和科学领域。当看到 AI 的推理能力能泛化到这些领域,真的令人惊喜。
比如在医学领域,模型在医学症状的判断上,涉及形成假设、验证,随后再形成新的假设。
即使在研究者没有特别关注的领域,模型也进展得很快,比如医学、法律推理。
而他们也确信,在未来还会有其他还未测试过的领域,AI 会有重大进展。
OpenAI 仍然注重安全
Mark Chen 肯定地说,目前 OpenAI 仍然像早期那样,致力于研究和安全。
为此,他管理着一个非常庞大的研究项目组合。并且一直在思考着应该分配多少资源和力量来进行探索性研究,而不是短期的即时项目。

不过,在这方面,OpenAI 和很多大型基础实验室不同。
这些大实验室有很多优秀的研究者,可以没有方向地进行研究,自由地去做任何事。
但对 OpenAI 来说,他们比这些实验室的规模都要小,因此需要更有方向性。
他们选择了一些非常有信心的探索性项目,在这些领域内,给了研究者很大的自由度。
也就是说,OpenAI 并不会进行毫无目标的探索,而且充分利用了自己规模小的优势。
现在是 AI 创业的好时机
OpenAI 的研究者也认为,现在是基于 AI 创立初创公司的好时机。
基础模型的玩家专注的是通用性。
但像 OpenAI 这样的公司,不可能涉足每一个垂直领域。
在特定领域定制一个模型,有很多空间和可能性。
现在,我们已经可以看到一个丰富的初创企业生态系统,这些企业在 OpenAI 的基础上构建了各种类型的应用。
通常情况下,初创企业之所以能够成功,是因为他们知道并坚信某个秘密,而市场上的其他人并不知道这个秘密。
在 AI 领域,实际上就是在一个不断变化的技术栈上进行构建,我们无法预测下一个模型会何时出现。
表现最好的初创企业,就是那些有直觉,在刚刚开发发挥作用的边缘技术上进行构建的企业,它们有一种生命力。
当我们拥有 AGI,就是相当强大的形式,真正释放了全部潜力。
想象一个人在一周内,就能创建一个带来巨大价值的大型初创公司。
一个人在几天内产生巨大影响的想法,已经不仅限于商业领域。
这种怀旧的感觉就像 17 世纪,科学家们在探讨物理学一样。
我们能否回到那种氛围,一个人能做出医学、物理学或计算机科学领域的重大发现?
而这些,都是因为 AI。
参考资料:
https://x.com/tsarnick/status/1860458274195386658
via:
-
OpenAI 大改下代大模型方向,scaling law 撞墙?AI 社区炸锅了 机器之心 2024 年 11 月 11 日 11:57 北京
https://mp.weixin.qq.com/s/0SXPOvFPFo4f7rphxbUuwA -
GPT-5 被曝不及预期,OpenAI 员工:没什么科学突破了,接下来只需要工程 量子位 2024 年 11 月 11 日 13:04 北京
https://mp.weixin.qq.com/s/J_VH7R0qkYckcLEGV3eBew -
OpenAI Adjusts Strategy as ‘GPT’ AI Progress Slows! - All About AI
https://www.allaboutai.com/ai-news/openai-adjusts-strategy-as-gpt-ai-progress-slows/ -
OpenAI 怒斥 Scaling 撞墙论!o1 已产生推理直觉潜力巨大 机器学习研究组订阅 2024 年 11 月 25 日 19:24 山西
https://mp.weixin.qq.com/s/zFjeAVhbLS5yvkmP9YrU_w


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









