




注:本文为“通信协议之序列化 | TLV 编码应用” 相关文章合辑。
通信协议之序列化
2012-07-07 15:15:34 stevenrao 于深圳
通信协议可以理解两个节点之间为了协同工作实现信息交换,协商一定的规则和约定,例如规定字节序,各个字段类型,使用什么压缩算法或加密算法等。常见的有 tcp,udo,http,sip 等常见协议。协议有流程规范和编码规范。流程如呼叫流程等信令流程,编码规范规定所有信令和数据如何打包 / 解包。
编码规范就是我们通常所说的编解码,序列化。不光是用在通信工作上,在存储工作上我们也经常用到。如我们经常想把内存中对象存放到磁盘上,就需要对对象进行数据序列化工作。
本文采用先循序渐进,先举一个例子,然后不断提出问题 - 解决完善,这样一个迭代进化的方式,介绍一个协议逐步进化和完善,最后总结。看完之后,大家以后在工作就很容易制定和选择自己的编码协议。
一、紧凑模式
本文例子是 A 和 B 通信,获取或设置基本资料,一般开发人员第一步就是定义一个协议结构:
struct userbase
{
unsigned short cmd;//1-get, 2-set, 定义一个 short,为了扩展更多命令 (理想那么丰满)
unsigned char gender; //1 – man , 2-woman, 3 - ??
char name [8]; // 当然这里可以定义为 string name;或 len + value 组合,为了叙述方便,就使用简单定长数据
}
在这种方式下,A 基本不用编码,直接从内存 copy 出来,再把 cmd 做一下网络字节序变换,发送给 B。B 也能解析,一切都很和谐愉快。
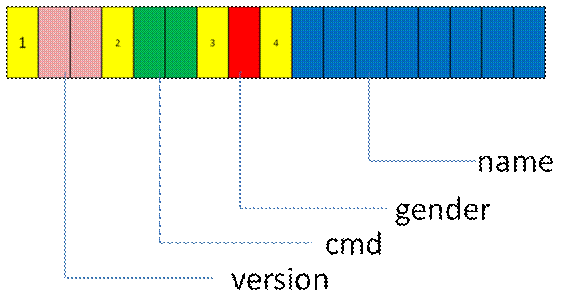
这时候编码结果可以用图表示为 (1 格一个字节)

这种编码方式,我称之为紧凑模式,意思是除了数据本身外,没有一点额外冗余信息,可以看成是 Raw Data。在 dos 年代,这种使用方式非常普遍,那时候可是内存和网络都是按 K 计算,cpu 还没有到 1G。如果添加额外信息,不光耗费捉襟见肘的 cpu,连内存和带宽都伤不起。
二、可扩展性
有一天,A 在基本资料里面加一个生日字段,然后告诉 B
struct userbase
{
unsigned short cmd;
unsigned char gender;
unsigned int birthday;
char name [8];
}
这是 B 就犯愁了,收到 A 的数据包,不知道第 3 个字段到底是旧协议中的 name 字段,还是新协议中 birthday。这是后 A,和 B 终于从教训中认识到一个协议重要特性 —— 兼容性和可扩展性。
于是乎,A 和 B 决定废掉旧的协议,从新开始,制定一个以后每个版本兼容的协议。方法很简单,就是加一个 version 字段。
struct userbase
{
unsigned short version;
unsigned short cmd;
unsigned char gender;
unsigned int birthday;
char name [8];
}
这样,A 和 B 就松一口气,以后就可以很方便的扩展。增加字段也很方便。这种方法即使在现在,应该还有不少人使用。
二、更好的可扩展性
过了一段较长时间,A 和 B 发现又有新的问题,就是没增加一个字段就改变一下版本号,这还不是重点,重点是这样代码维护起来相当麻烦,每个版本一个 case 分支,到了最好,代码里面 case 几十个分支,看起来丑陋而且维护起来成本高。
A 和 B 仔细思考了一下,觉得光靠一个 version 维护整个协议,不够细,于是觉得为每个字段 增加一个额外信息 ——tag, 虽然增加内存和带宽,但是现在已经不像当年那样,可以容许这些冗余,换取易用性。
struct userbase
{
unsigned short version;
unsigned short cmd;
unsigned char gender;
unsigned int birthday;
char name [8];
}
制定完这些协议后,A 和 B 很得意,觉得这个协议不错,可以自由的增加和减少字段。随便扩展。
现实总是很残酷的,不久就有新的需求,name 使用 8 个字节不够,最大长度可能会达到 100 个字节,A 和 B 就愁怀了,总不能即使叫 “steven” 的人,每次都按照 100 个字节打包,虽然不差钱,也不能这样浪费。
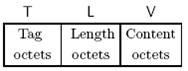
于是 A 和 B 寻找各方资料,找到了 ANS.1 编码规范,好东西啊… ASN.1 是一种 ISO/ITU-T 标准。其中一种编码 BER(Basic Encoding Rules)简单好用,它使用三元组编码,简称 TLV 编码。
每个字段编码后内存组织如下
字段可以是结构,即可以嵌套

A 和 B 使用 TLV 打包协议后,数据内存组织大概如下:
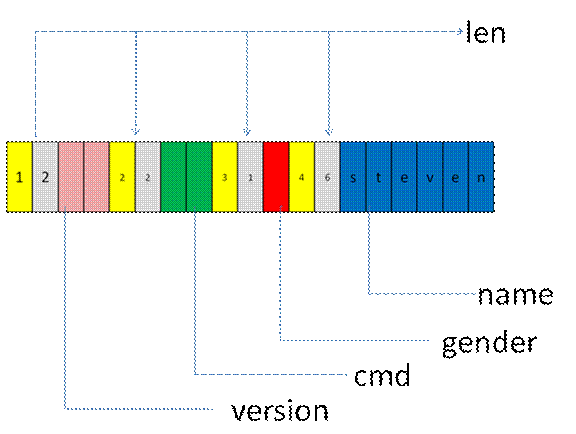
TLV 具备了很好可扩展性,很简单易学。同时也具备了缺点,因为其增加了 2 个额外的冗余信息,tag 和 len,特别是如果协议大部分是基本数据类型 int ,short, byte. 会浪费几倍存储空间。另外 Value 具体是什么含义,需要通信双方事先得到描述文档,即 TLV 不具备结构化和自解释特性。
三、自解释性
当 A 和 B 采用 TLV 协议后,似乎问题都解决了。但是还是觉得不是很完美,决定增加自解释特性,这样抓包就能知道各个字段类型,不用看协议描述文档。这种改进的类型就是 TT [L] V(tag,type,length,value),其中 L 在 type 是定长的基本数据类型如 int, short, long, byte 时候,因为其长度是已知的,所以 L 不需要。
于是定义了一些 type 值如下
| 类型 | Type 值 | 类型描述 |
|---|---|---|
| bool | 1 | 布尔值 |
| int8 | 2 | 带符号的一个字符 |
| uint8 | 3 | 带符号的一个字符 |
| int16 | 4 | 16 位有符号整型 |
| uint16 | 5 | 16 位无符号整型 |
| int32 | 6 | 32 位有符号整型 |
| uint32 | 7 | 32 位无符号整型 |
| … | ||
| string | 12 | 字符串或二进制序列 |
| struct | 13 | 自定义的结构,嵌套使用 |
| list | 14 | 有序列表 |
| map | 15 | 无序列表 |
按照 TTLV 序列化后,内存组织如下
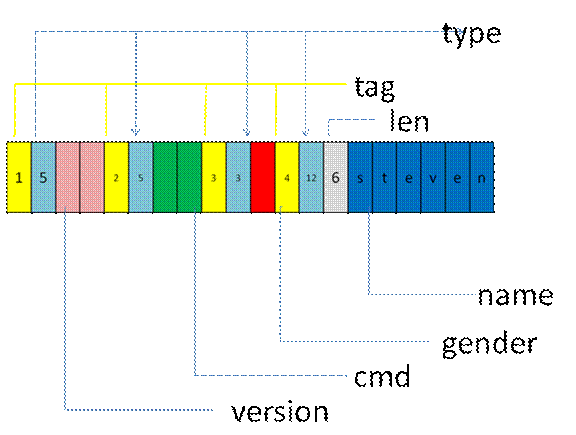
改完后,A 和 B 发现,的确带来很多好处,不光可以随心所以的增删字段,还可以修改数据类型,例如把 cmd 改成 int cmd;可以无缝兼容。真是太给力了。
三、跨语言特性
有一天来了一个新的同事 C,他写一个新的服务,需要和 A 通信,但是 C 是用 java 或 PHP 的语言,没有无符号类型,导致负数解析失败。为了解决这个问题,A 重新规划一下协议类型,做了有些剥离语言特性,定义一些共性。对使用类型做了强制性约束。虽然带来了约束,但是带来通用型和简洁性,和跨语言性,大家表示都很赞同,于是有了一个类型 (type) 规范。
| 类型 | Type 值 | 类型描述 |
|---|---|---|
| bool | 1 | 布尔值 |
| int8 | 2 | 带符号的一个字符 |
| int16 | 3 | 16 位有符号整型 |
| int32 | 4 | 32 位有符号整型 |
| … | ||
| string | 12 | 字符串或二进制序列 |
| struct | 13 | 自定义的结构,嵌套使用 |
| list | 14 | 有序列表 |
| map | 15 | 无序列表 |
四、代码自动化 —— IDL 语言的产生
但是 A 和 B 发现了新的烦恼,就是每搞一套新的协议,都要从头编解码,调试,虽然 TLV 很简单,但是写编解码是一个毫无技术含量的枯燥体力活,一个非常明显的问题是,由于大量 copy/past, 不管是对新手还是老手,非常容易犯错,一犯错,定位排错非常耗时。于是 A 想到使用工具自动生成代码。
IDL(Interface Description Language),它是一种描述语言,也是一个中间语言,IDL 一个使命就是规范和约束,就像前面提到,规范使用类型,提供跨语言特性。通过工具分析 idl 文件,生成各种语言代码
Gencpp.exe sample.idl 输出 sample.cpp sample.h
Genphp.exe sample.idl 输出 sample.php
Genjava.exe sample.idl 输出 sample.java
是不是简单高效 J
四、总结
大家看到这里,是不是觉得很面熟。是的,协议讲到最后,其实就是和 facebook 的 thrift 和 google protocol buffer 协议大同小异了。包括公司无线使用的 JCE 协议。咋一看这些协议的 idl 文件,发现几乎是一样的。只是有些细小差异化。
这些协议在一些细节上增加了一些特性:
1、压缩,这里压缩不是指 gzip 之类通用压缩,是指针对整数压缩,如 int 类型,很多情况下值是小于 127(值为 0 的情况特别多),就不需要占用 4 个字节,所以这些协议做了一些细化处理,把 int 类型按照情况,只使用 1/2/3/4 字节,实际上还是一种 ttlv 协议。
2、reuire/option 特性:这个特性有两个作用,1、还是压缩,有时候一个协议很多字段,有些字段可以带上也可以不带上,不赋值的时候不是也要带一个缺省值打包,这样很浪费,如果字段是 option 特性,没有赋值的话,就不用打包。2、有点逻辑上约束功能,规定哪些字段必须有,加强校验。
序列化是通信协议的基础,不管是信令通道还是数据通道,还是 rpc,都需要使用到。在设计协议早期就考虑到扩展性和跨语言特性。会为以后省去不少麻烦。
Ps
本篇主要介绍二进制通信协议序列化,没有讲文本协议。从某种意义来讲,文本协议天生具有兼容和可扩展性。不像二进制需要考虑那么多问题。文本协议易于调试(如抓包就是可见字符,telnet 即可调试,数据包可以手工生成不借助特殊工具),简单易学是其最强大的优势。
二进制协议优势就是性能和安全性。但是调试麻烦。
两者各有千秋,按需选择。(stevenrao)
看懂通信协议:自定义通信协议设计之 TLV 编码应用
原创 maxid 2014/03/09 11:45
因为之前从事过电信信令类工作,接触较多的则是 ASN.1 中的 BER、PER 编码,其中 BER 是基于 TLV 方式进行编码,本文主要介绍一下 TLV 在自定义协议中的应用。
通过该文章,你可以肉眼看懂一些类似二进制通信协议,并可以尝试封装自己的通信协议
1. 通信协议
协议可以使双方不需要了解对方的实现细节的情况下进行通信,因此双方可以是异构的,server 可以是 c++,client 可以是 java,基于相同的协议,我们可以用自己熟识的语言工具来实现。
协议一般由一个或多个消息组成,简单的来说,消息就像是一个 Table,由表头 (消息的字段定义,包括名称与数据类型) 与行 (字段值) 组成。
2. 自定义通信协议
约定好双方交换数据的编解码方式,包括一致的基本数据类型,业务类型,字节序、消息内容等。
3. 编码方式
可以跟据业务需要进行定制,如对编解码速度、网络带宽、用户量等进行考量
3.1. 基于字符串编码
报头 (4 字节描述数据体长度)+ 数据 (字符串 + 分隔符或直接使用 JSON),该方式实现简单,在编解码阶段成本低、但在数据类型转时成本较高,同时可能会较占用带宽。
3.2. 基于二进制编码
将协议以特定格式编码为字节数组,该种方式相较字符串编码方式实现要求要高一些,但带宽占用相对小一些,本文主要介绍其中一种较常用的编码方式 TLV,即 Tag\Length\Value。
4. TLV 编码介绍 (其中一种实现介绍)
TLV:TLV 是指由数据的类型 Tag,数据的长度 Length,数据的值 Value 组成的结构体,几乎可以描任意数据类型,TLV 的 Value 也可以是一个 TLV 结构,正因为这种嵌套的特性,可以让我们用来包装协议的实现。
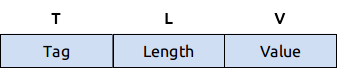
以下将分别针对 Tag、Length、Value 进行解说:
4.1. Tag 描述 Value 的数据类型,TLV 嵌套时可以用于描述消息的类型
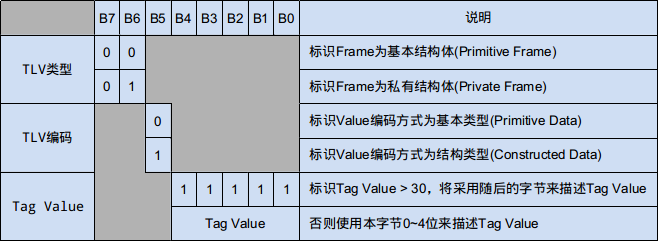
Tag 由一个或多个字节组成,上图描述首字节 0~7 位的具体含义
1) Tag 首节字说明
- 第 6~7 位:表示 TLV 的类型,00 表示 TLV 描述的是基本数据类型 (Primitive Frame, int,string,long…),01 表示用户自定义类型 (Private Frame,常用于描述协议中的消息)。
- 第 5 位:表示 Value 的编码方式,分别支持 Primitive 及 Constructed 两种编码方式,Primitive 指以原始数据类型进行编码,Constructed 指以 TLV 方式进行编码,0 表示以 Primitive 方式编码,1 表示以 Constructed 方式编码。
- 第 0~4 位:当 Tag Value 小于 0x1F (31) 时,首字节 0~4 位用来描述 Tag Value,否则 0~4 位全部置 1,作为存在后续字节的标志,Tag Value 将采用后续字节进行描述。

2) Tag 后续字节说明
后续字节采用每个字节的 0~6 位(即 7bit)来存储 Tag Value, 第 7 位用来标识是否还有后续字节。
- 第 7 位:描述是否还有后续字节,1 表示有后续字节,0 表示没有后续字节,即结束字节。
- 第 0~6 位:填充 Tag Value 的对应 bit (从低位到高位开始填充),如:Tag Value 为:0000001 11111111 11111111 (10 进制:131071), 填充后实际字节内容为:10000111 11111111 01111111。

以下提供 Tag 编码的 JAVA 实现
/**
* 生成 Tag ByteArray
*
* @param tagValue Tag 值,即协议中定义的交易类型 或 基本数据类型
* @param frameType TLV 类型,Tag 首字节最左两bit为00:基本类型,01:私有类型(自定义类型)
* @param dataType 数据类型,Tag 首字节第5位为0:基本数据类型,1:结构类型( TLV 类型,即 TLV 的 V 为一个 TLV 结构)
* @return Tag ByteArray
*/
public byte[] parseTag(int tagValue, int frameType, int dataType) {
int size = 1;
rawTag = frameType | dataType | tagValue;
if (tagValue < 0x1F) {
// 1 byte tag
rawTag = frameType | dataType | tagValue;
} else {
// mutli byte tag
rawTag = frameType | dataType | 0x1F;
if (tagValue < 0x80) {
rawTag <<= 8;
rawTag |= tagValue & 0x7F;
} else if (tagValue < 0x3FFF) {
rawTag <<= 16;
rawTag |= (((tagValue & 0x3FFF) >> 7 & 0x7F) | 0x80) << 8;
rawTag |= ((tagValue & 0x3FFF) & 0x7F);
} else if (tagValue < 0x3FFFF) {
rawTag <<= 24;
rawTag |= (((tagValue & 0x3FFFF) >> 14 & 0x7F) | 0x80) << 16;
rawTag |= (((tagValue & 0x3FFFF) >> 7 & 0x7F) | 0x80) << 8;
rawTag |= ((tagValue & 0x3FFFF) & 0x7F);
}
}
return intToByteArray(rawTag);
}
4.2. Length 描述 Value 的长度
描述 Value 部分所占字节的个数,编码格式分两类:定长方式(DefiniteForm)和不定长方式(IndefiniteForm),其中定长方式又包括短形式与长形式。
1) 定长方式
定长方式中,按长度是否超过一个八位,又分为短、长两种形式,编码方式如下:
- 短形式: 字节第 7 位为 0,表示 Length 使用 1 个字节即可满足 Value 类型长度的描述,范围在 0~127 之间的。
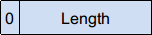
- 长形式:
即 Value 类型的长度大于 127 时,Length 需要多个字节来描述,这时第一个字节的第 7 位置为 1,0~6 位用来描述 Length 值占用的字节数,然后直将 Length 值转为 byte 后附在其后,如: Value 大小占 234 个字节(11101010), 由于大于 127,这时 Length 需要使用两个字节来描述,10000001 11101010

以下提供 Length 定长方式的 JAVA 实现
public byte[] parseLength(int length) {
if (length < 0) {
throw new IllegalArgumentException();
} else
// 短形式
if (length < 128) {
byte[] actual = new byte[1];
actual[0] = (byte) length;
return actual;
} else
// 长形式
if (length < 256) {
byte[] actual = new byte[2];
actual[0] = (byte) 0x81;
actual[1] = (byte) length;
return actual;
} else if (length < 65536) {
byte[] actual = new byte[3];
actual[0] = (byte) 0x82;
actual[1] = (byte) (length >> 8);
actual[2] = (byte) length;
return actual;
} else if (length < 16777126) {
byte[] actual = new byte[4];
actual[0] = (byte) 0x83;
actual[1] = (byte) (length >> 16);
actual[2] = (byte) (length >> 8);
actual[3] = (byte) length;
return actual;
} else {
byte[] actual = new byte[5];
actual[0] = (byte) 0x84;
actual[1] = (byte) (length >> 24);
actual[2] = (byte) (length >> 16);
actual[3] = (byte) (length >> 8);
actual[4] = (byte) length;
return actual;
}
}
2) 不定长方式
Length 所在八位组固定编码为 0x80,但在 Value 编码结束后以两个 0x00 结尾。这种方式使得可以在编码没有完全结束的情况下,可以先发送部分数据给对方。

4.3. Value 描述数据的值
由一个或多个值组成 ,值可以是一个原始数据类型 (Primitive Data),也可以是一个 TLV 结构 (Constructed Data)
1) Primitive Data 编码

2) Constructed Data 编码

5. TLV 编码应用
如果各位看官充分消化了第 4 点 TLV 的描述,自然可以很容易将其应用到自定义协议之中,其实我们只要定制各种 TLV 自定义类型 (Private Frame) 与协议中的消息一一对应更行了
下面将以一个简单的协议来描述 TLV 的应用,假设该协议消息定义如下:
消息名称:设备故障码 (DEVICE_FAULT_1)
公共字段定义
| 名称 | 字段 | Tag 值 | 长度 | 类型 |
|---|---|---|---|---|
| 设备编号 | DeviceNo | 1 | 4 | Integer |
| 设备版本号 | DeviceVersion | 2 | 12 | String |
请求定义
| 名称 | 字段 | Tag 值 | 长度 | 类型 |
|---|---|---|---|---|
| 错误码 | FaultCode | 3 | 4 | Integer |
响应定义
| 名称 | 字段 | Tag 值 | 长度 | 类型 |
|---|---|---|---|---|
| 响应码 | ResponseCode | 3 | 4 | Integer |
| 响应信息 | ResponseMsg | 4 | -1 | String |
5.1 基本数据类型约定
这时需要对基本数据类型 (Primitive Data) 进行约定,以便通信双方以一致的方式进行数据转换,这也作为协议制定的一部分
基本数据类型约定
| 名称 | 类型 | 标记:Tag | 长度:Length | 值范围:Value |
|---|---|---|---|---|
| 布尔 | Boolean | 10 进制:1, 2 进制:00000001 | 1 | 1:true … 0:false |
| 小整型 | Tiny | 10 进制:2, 2 进制:00000010 | 1 | -127 … 127 |
| 无符号小整型 | UTiny | 10 进制:3, 2 进制:00000011 | 1 | 0 … 255 |
| 短整型 | Short | 10 进制:4, 2 进制:00000100 | 2 | -32768 … 32767 |
| 无符号短整型 | UShort | 10 进制:5, 2 进制:00000101 | 2 | 0 … 65535 |
| 整型 | Integer | 10 进制:6, 2 进制:00000110 | 4 | -2147483648 … 2147483648 |
| 无符号整型 | UInteger | 10 进制:7, 2 进制:00000111 | 4 | 0 … 4294967295 |
| 长整型 | Long | 10 进制:8, 2 进制:00001000 | 8 | -2^64 … 2^64 |
| 无符号长整型 | ULong | 10 进制:9, 2 进制:00001001 | 8 | 0 … 2^128-1 |
| 单精浮点类型 | Float | 10 进制:10, 2 进制:00001010 | 4 | -2^128 … 2^128 |
| 双精浮点类型 | Double | 10 进制:11, 2 进制:00001011 | 8 | -2^1024 … 2^1024 |
| 字符类型 | Char | 10 进制:12, 2 进制:00001100 | 1 | ASCII |
| 字符串类型 | String | 10 进制:13, 2 进制:00001101 | 可变 | 由一个或多个 Char 组成 |
| 组合类型 | Complex | 10 进制:14, 2 进制:00001110 | 可变 | 由一个或多个基本类型 1~9 组成,由协议两端双方进行约定编解码 |
| 空类型 | Null | 10 进制:15, 2 进制:00001111 | 0 |
上表需要关注的是数据类型对应的 Tag 值与 Length 值
5.2 协议消息约定
| 名称 | 消息 | 标记:Tag |
|---|---|---|
| 设备故障码 | DEVICE_FAULT_1 | 1 |
5.3 示例
通过三层 TLV 嵌套,完成协议消息的封包
- 第一层:与协义消息对应
- 第二层:与消息字段对应
- 第三层:与字段值对应,包括其值的类型信息
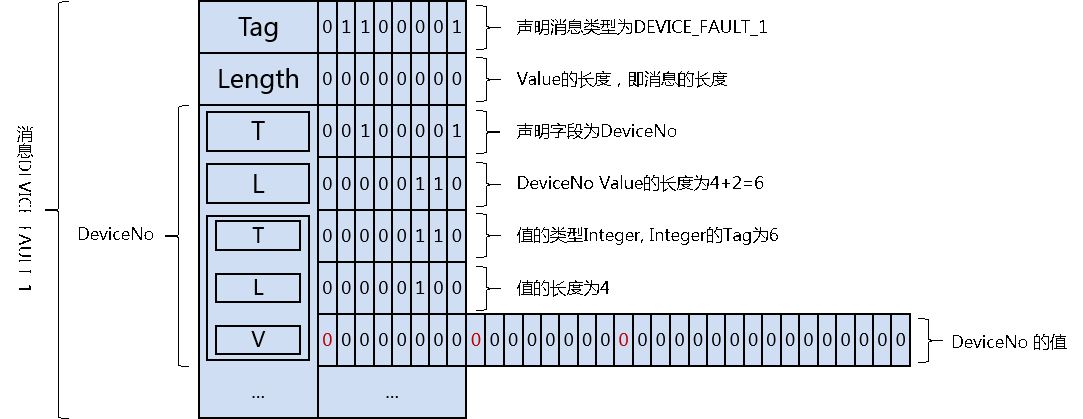
Tips:每层嵌套都有 2 个或以上的字节增加 (Tag 和 Length),一般通信双方可以按照协议对数据类型进行推定,所以大家可以根据实际需要,决定是否省略第三层的 Tag 和 Length,即可通过配置文件或其它方式让程序了解字段的类型,从而降低数据包的大小,节省流量。
6 总结
从上面可以看出,TLV 是一种与业务无关的编码方式,可以较容易用来实现自定义协议
TLV封包与解包详解
Tavi_于 2020-04-25 22:17:39 发布
何谓 TLV
所谓通讯协议就是指通信双方对数据传送控制的一种约定。约定中包括对数据格式,同步方式,传送速度,传送步骤,纠错方式以及控制字符定义等问题做出统一规定,通信双方必须共同遵守,倘若一方不遵守,便会直接导致数据不能被解析!更通俗来讲,它可以理解两个节点之间为了协同工作实现信息交换,协商一定的规则和约定,例如规定字节序,各个字段类型等。

Tag:标记
Length:一般为value的长度,也可以是整个TLV的长度;
Value:真正的数据长度。
如下表格所示:完整的TLV的协议:
为了读取一个TLV错误导致后面的TLV都全部乱序了。
| 报文头 | Tag | Length | Value | CRC16校验和 |
|---|---|---|---|---|
| 1 Byte | 1 Byte | n+5 Bytes | n Bytes | 2 Bytes |
报文头:用来标志一个报文的开始;
CRC16:占 2 个字节,从报文头开始到数据结尾 (Value) 所有数据的 CRC 校验和;
具体可以参考下面的案例:

这里列举了产品的 ID 时间 和温度的TLV报文, 假如数据报文是如下这样简单的 TLV:

当接收数据时发生一个温度的 TLV 错误 ,变成如下所示:

这里一个 TLV 错误,导致数据读取时找到最近的 0x03 作为温度的 Tag, 0x02 表示 Length, 0x0c 16 就是 value 值, 那后面岂不是乱套了, 若定义了 0x04 标识,那在从该位置进行解析,接收的数据就 GG 了.
所以加上标识和和CRC校验位, 标识一般采用 0xfd,不容易引起错误, 最好不要用 0x01 02 等作为头;
CRC校验时需要将整个 HTLV 都校验,如果检验错误直接丢弃该 HTLV 数据,再寻找下一个 HTLV 即可。
好了,直接上代码吧:
TLV 封包代码如下:
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include"crc-itu-t.c"
#include<stdlib.h>
#define TLV_MAX_SIZE 128
#define TLV_MIN_SIZE 6
#define Tag_temper 0x03 //可以使用枚举
#define HEADER 0xfd
int tlv_pack(char *buf, int size, int cmd)
{
unsigned short crc16;
int pack_len = 0x02
/* Only 2 byte value */
if(!buf || size<TLV_MIN_SIZE )
{
printf("Invalid input arguments\n");
return 0;
}
/* Packet head */
buf[0] = HEADER;
/* Tag */
buf[1] = Tag_temper;
/* Length, this packet total 6 bytes */
buf[2] = pack_len;
/* Value */
buf[3] = 0x0e; //如果value多的话,可以用for循环
buf[3] = 0x03;
//CRC检验算法网上也比较多,可以直接用就行
crc16 = crc_itu_t(MAGIC_CRC, buf, 4); //HTLV计算出一个unsigned short类型crc的值
ushort_to_bytes(&buf[4], crc16);//将16位的crc值(1个字节8个位)转换成两个字节加到HTLV最后变成HTLV CRC的tlv报文
return pack_len;
}
下面是 TLV 解包的代码有些复杂,不要过多依赖对端,考虑了粘包的可能性。
加入了ACK/NAK机制:
ACK 表示确认收到报文,可以进行下一次传输;
NAK 表示报文出错,请求再次重传,一般不超过三次.
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include "tlv_unpack.h"
#include "crc-itu-t.h"
#include "hex_str_to_int.h"
int tlv_unpack(char *r_buf, int size, int cli_fd, char *tlv)
{
int i;
int len;
unsigned short val;
unsigned short crc16;
int data;
start_loop:
int ofset = 0;
//首先判断读取的全部帧当中,是否存在有效数据, 否则传输NAK报文请求重传
if (size < MIN_PACK_SIZE)
{
printf("Pack too short and get data stream failure: %s\n", strerror(errno));
//写NAK报文给客户端 MAGIC_CRC选定的CRC校验的除数
crc16 = crc_itu_t(MAGIC_CRC, (unsigned char *)nak_buf, 4); //获得unsigned short类型校验位, 第一个为除数, 第二个为数组指针, 第三个为校验长度
ushort_to_bytes(&nak_buf[4], crc16); //将CRC的2字节的校验值,转化成两个一字节存在unsigned char 当中
write(cli_fd, nak_buf, strlen(MIN_PACK_SIZE) );
return -1;
}
//在一个buf中一帧一帧解析TLV,进行读取数据
for (i=0; i<size; i++)
{
//读到报文头
if (r_buf[i] == HEARDER)
{
//只有帧头和标志位,没有value值 (读到buf的最后了)
if (size-i < 2)
{
printf("remain data too short and read ok.\n")
printf("Wait continue input data.\n")
//这里需要注意, 若将字符串后面的'\0'也读取到了,那么会将目的buf的后面数据全部清除
memmvoe(r_buf, &r_buf[i], strlen(size-i) ); //数据拷贝到buf首部,等待下一次传输数据,再读取
crc16 = crc_itu_t(MAGIC_CRC, (unsigned char *)nak_buf, 4); //获得unsigned short类型校验位
ushort_to_bytes(&ack_buf[4], crc16); //将CRC的2字节的校验值,转化成两个一字节存在unsigned char 当中
write(cli_fd, ack_buf, strlen(MIN_PACK_SIZE) );
return size-i; //剩余字节数
}
ofset += i+2;
len = r_buf[ofset];
//帧(length)长度错误,直接丢弃该报文段,并发送NAK报文,请求重新发数据
if ( len < MIN_PACK_SIZE || len > MAX_PACK_SIZE)
{
memmove(r_buf, &r_buf[ofset], strlen(size-i-len));
crc16 = crc_itu_t(MAGIC_CRC, (unsigned char *)nak_buf, 4); //获得unsigned short类型校验位
ushort_to_bytes(&nak_buf[4], crc16); //将CRC的2字节的校验值,转化成两个一字节存在unsigned char 当中
write(cli_fd, nak_buf, strlen(MIN_PACK_SIZE) );
goto start_loop;
}
printf("Current TLV data abnormal.\n")
//报文未读完,继续保存到buf,下一次读取
if (len > size-i)
{
memmove(r_buf, &r_buf[ofset], strlen(size-i) );
printf("TLV packed is accomplish.\n");
printf("Wait next data input.\n");
crc16 = crc_itu_t(MAGIC_CRC, (unsigned char *)nak_buf, 4); //获得unsigned short类型校验位
ushort_to_bytes(&ack_buf[4], crc16); //将CRC的2字节的校验值,转化成两个一字节存在unsigned char 当中
write(cli_fd, ack_buf, strlen(MIN_PACK_SIZE) );
return size-i; //剩余字节数
}
//正常读取TLV数据包,需要首先判断CRC检验和是否相同, 不同则直接丢弃该报文段
crc16 = crc_itu_t(MAGIC_CRC, (unsigned char *)r_buf[i], len); //获得unsigned short类型校验位
val = bytes_to_ushort(&r_buf[i+len-2], crc16); //将CRC的2字节的校验值,转化成两个一字节存在unsigned char 当中
//CRC若不相等则检验失败,发送NAK报文请求重传
if (crc16 != val)
{
printf("CRC checkout failure.\n");
memmove(r_buf, &r_buf[i], strlen(len) );
crc16 = crc_itu_t(MAGIC_CRC, (unsigned char *)nak_buf, 4); //获得unsigned short类型校验位
ushort_to_bytes(&nak_buf[4], crc16); //将CRC的2字节的校验值,转化成两个一字节存在unsigned char 当中
write(cli_fd, nak_buf, strlen(MIN_PACK_SIZE) );
goto start_loop;
}
printf("CRC checkout sucessfuly.\n");
//解析成功,将该TLV数据包保存进行处理
ofset = 0;
ofset = (i+3);
if (r_buf[i+1] == Tag_temper)
{
; //实现自己想要的功能
}
//分析完成一个TLV数据包后,丢弃该包,分析下一个TLV
printf("Unpack a TLV data accomplish.\n");
memmove(r_buf, &r_buf[i], size-i-len);
size = size-i-len; //分析剩余TLV数据
goto start_loop;
}//if (r_buf[i] == HEARDER)
}//for (i=0; i<size; i++)
return 0;
}
via:
-
通信协议之序列化 - raochaoxun-ChinaUnix 博客 2012-07-07 15:15:34 stevenrao 于深圳
http://blog.chinaunix.net/uid-27105712-id-3266286.html -
看懂通信协议:自定义通信协议设计之 TLV 编码应用 - OSCHINA 原创 maxid 2014/03/09 11:45
https://my.oschina.net/maxid/blog/206546 -
TLV 封包与解包详解_tlv 竖解密 - 优快云 博客 Tavi_于 2020-04-25 22:17:39 发布
https://blog.youkuaiyun.com/Ternence_zq/article/details/105757272

















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









