







这篇博文应该是本人至今为止总结的第一篇与自然语言处理相关的论文笔记,初次提笔,难免会有疏漏,还请莫怪。《Chinese NER Using Lattice LSTM》,源码:(PyTorch版)https://github.com/jiesutd/LatticeLSTM,ACL 2018顶会论文。
一、摘要:针对中文命名实体识别提出一种lattice-LSTM模型,该模型能够这么对输入字符序列以及所有匹配语料库的潜在词进行编码。与基于字符方法相比,该模型能够充分利用词和词序列信息;与基于词的方法相比,该模型不存在分割错误问题;门控循环细胞允许该模型从句子中选择最相关的字符和词以提高命名实体结果。在多种数据集上的实验结果表明,Lattice LSTM模型的结果要优于基于词和基于字符的LSTM模型。
二、问题:中文命名实体识别与分词相关,而中文分词界面模糊,容易分词错误,进而造成错误传播。虽然基于字符的方法要优于基于词的方法,但携带的信息有限,未充分利用显式词和词序列信息,而这些信息可能很有用。
三、思路:即考虑如何将字符信息和词信息进行融合,使其能够有效避免分割错误问题。提出采用lattice LSTM结构自动控制从句首到句尾的信息流。
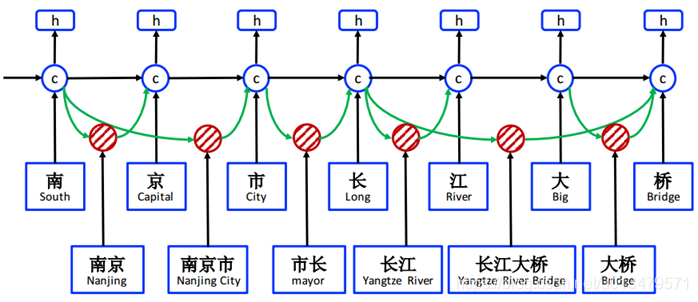
四、方法:
1、该模型采用LSTM-CRF作为主要框架,输入可表示为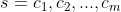 ,
, 表示为第j个字符,s也可进一步视为词序列,
表示为第j个字符,s也可进一步视为词序列,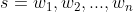 ,表示句子中的第i个词。采用
,表示句子中的第i个词。采用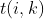 表示句子中在第i个词中第k个字符的索引j,采用BIOES标注模式。
表示句子中在第i个词中第k个字符的索引j,采用BIOES标注模式。
2、字符模型,词模型和Lattice模型
2.1 字符型模型:
(1) Char+bichar 字符嵌入连接character bigrams嵌入
![\textup{x}_{j}^{c}=\left [ \boldsymbol{\textbf{e}}^c(c_{j});\textbf{e}^b(c_{j},c_{j+1}) \right ] (3)](https://i-blog.csdnimg.cn/blog_migrate/503467c3b5fc0a2ccd60a52d52ddd3a3.gif)
(2) Char +softword 连接分割标签嵌入和字符嵌入
![\textup{x}_{i}^c=\left [ \textbf{e}^c(c_{j});\textbf{e}^s(seg(c_{j})) \right ] (4)](https://i-blog.csdnimg.cn/blog_migrate/28fe5d21c4a17b364979522926161d75.gif)
2.2 词模型
(1) Word+ char LSTM: 词嵌入以及词中字符向量连接并采用BiLSTM进行训练,得出输出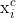 。
。
![\textup{x}_{i}^c=\left [ \overrightarrow{\mathbf{h}}_{t(i,len(i))}^c;\overleftarrow{\mathbf{h}}_{t(i,1)}^c \right ] (8)](https://i-blog.csdnimg.cn/blog_migrate/6f834a09e119492bca6d0f8f4140635c.gif%3D%5Cleft%20%5B%20%5Coverrightarrow%7B%5Cmathbf%7Bh%7D%7D_%7Bt%28i%2Clen%28i%29%29%7D%5Ec%3B%5Coverleftarrow%7B%5Cmathbf%7Bh%7D%7D_%7Bt%28i%2C1%29%7D%5Ec%20%5Cright%20%5D%20%288%29)
(2) Word+char LSTM’: 词嵌入以及词中字符向量连接并采用两个独立的LSTM训练,得出。
(3) Word+char CNN: 将CNN作用在每个词的字符序列上以获取字符表示。
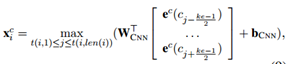
,ke=3,为卷积核大小,max为最大池化层;
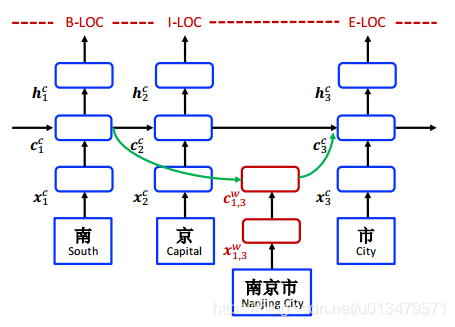
3、Lattice模型
输入:字符序以及与词库D中匹配的所有字符子序列;
四类向量:输入向量,输出隐层向量,细胞向量 和门控向量
和门控向量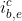
![]()
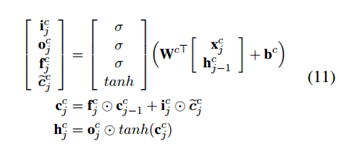
不同点在于考虑了语料中词的子序列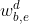 的状态,主要表现如下:
的状态,主要表现如下:
(1)针对每个句子子序列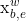 ,其当前状态
,其当前状态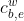 由字符序列b位置的隐层状态
由字符序列b位置的隐层状态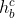 和子序列决定,显然若有输出的话,应作为词级输出,是作为下个状态
和子序列决定,显然若有输出的话,应作为词级输出,是作为下个状态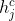 的输入,属于字符级,因此此处无需门控输出。
的输入,属于字符级,因此此处无需门控输出。
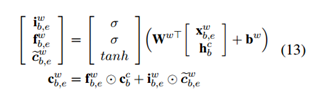
(2) 上述可以有多个子序列由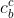 到达
到达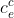 ,那么哪个子序列贡献最大呢?即最符合语义关系呢?此时需要一个额外门控来衡量每个子序列对的贡献。即:
,那么哪个子序列贡献最大呢?即最符合语义关系呢?此时需要一个额外门控来衡量每个子序列对的贡献。即:
![]()
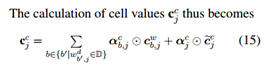
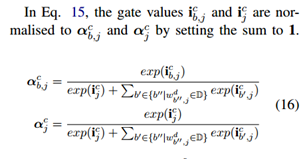
五、实验
1 数据集(四种)
OntoNotes, MSRA, Weibo NER,和自制的中文简历数据集(resume)。其中,resume采用YEDDA软件进行标注。
2、分割
针对无法采用黄金分割的数据集,采用Yang et al. (2017a)提出的方法进行分割,
3、词嵌入
在Chinese Giga-Word平台上采用Word2Vec进行训练。
4、实验结果
实验分别从字符嵌入,词嵌入和Lattice三个方面进行对比。

















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









