







 本文介绍了使用格子LSTM进行中文命名实体识别(NER)的研究,该模型融合了字和词的信息,解决了分词错误问题。实验表明,格子LSTM在多种数据集上优于基于字和词的LSTM基线,取得最优结果。
本文介绍了使用格子LSTM进行中文命名实体识别(NER)的研究,该模型融合了字和词的信息,解决了分词错误问题。实验表明,格子LSTM在多种数据集上优于基于字和词的LSTM基线,取得最优结果。
摘要
我们研究了一个面向中文NER的格子结构的LSTM模型,它编码一系列输入字符,以及所有匹配词典的潜在单词。与基于字符的方法相比,我们的模型显式地利用了单词和单词序列信息。与基于词的方法相比,格LSTM不存在分词错误。门控递归细胞使我们的模型能够从句子中选择最相关的字符和单词,以获得更好的NER结果。在不同数据集上的实验表明,lattice LSTM的性能优于基于字和基于字符的LSTM基线,取得了最好的效果。
1简介
命名实体识别(NER)作为信息抽取的一项基础性工作,近年来一直受到人们的关注。传统上,这项任务是作为一个序列标签问题来解决的,其中实体边界和类别标签是联合预测的。英语NER的当前技术水平是通过使用LSTM-CRF模型实现的,字符信息被集成到单词表示中。
汉语ner与分词相关。特别是,命名实体边界也是单词边界。一种直观的方法是在应用词序标注之前,先进行分词。然而,由于NEs是分词OOV的一个重要来源,因此segmentation→NER这条线可能会遇到错误传播的潜在问题,并且实体边界的错误分割会导致NER出错。由于跨域分词仍然是一个未解决的问题,所以在开放域中,这个问题可能会很严重。研究表明,在中文NER领域,基于字符的方法优于基于单词的方法。
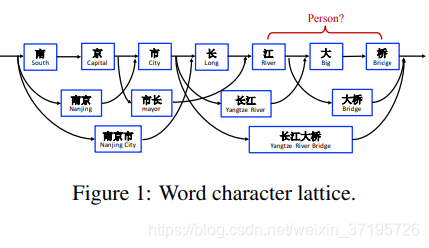
然而,基于字符的NER的一个缺点是没有充分利用显式的单词和单词序列信息,这可能是有用的。为了解决这个问题,我们将潜在的单词信息集成到特征为基础的LSTM-CRF,通过使用格子结构的LSTM表示句子中的词汇词。如图1所示,我们通过将句子与一个大的自动获得的词典相匹配来构造一个单词字符格。因此,可以使用诸如“长江大桥”、“长江”、“大桥”之类的单词序列来消除上下文中潜在的相关命名实体的歧义,例如人名“大桥江”。
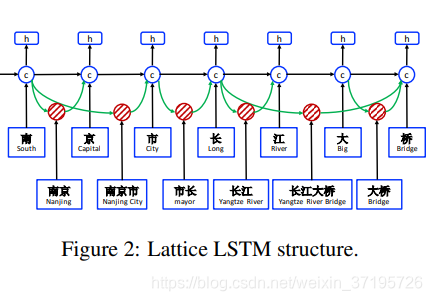
由于格中有指数数量的字字符路径,我们利用lattice-LSTM结构自动控制从句首到句尾的信息流。如图2所示,门控单元用于动态地将信息从不同的路径路由到每个字符。通过对NER数据的训练,lattice-LSTM可以学习从上下文中自动找到更多有用的单词,从而获得更好的NER性能。
结果表明,我们的模型在字符序列标记模型和基于LSTMCRF的单词序列标记模型上都有显著的优越性,在不同领域的中文NER数据集上都取得了最好的结果。我们的代码和数据发布于https://github.com/jiesutd/LatticeLSTM。
2 相关工作
我们的工作与现有的神经网络方法相一致。Hammerton(2003)试图使用单向LSTM来解决这个问题,LSTM是最早的神经网络模型之一。Collobert等人(2011)使用CNN-CRF结构,获得最佳统计模型的竞争结果。多斯桑托斯等人(2015)使用字符CNN来扩充CNN-CRF模型。最近的工作利用了LSTM-CRF体系结构。Huang等人(2015)使用手工制作的拼写功能;Ma和Hovy(2016)以及Chiu和Nichols(2016)使用字符CNN来表示拼写特征;Lample等人。(2016)改为使用字符LSTM。我们的基于词的基线系统采用了与这一行类似的结构。
字符序列标记一直是中国内质网的主要方法(Chen等人,2006b;Lu等人,2016;Dong等人,2016)。有明确的讨论比较了基于统计单词和基于字符的方法,显示后者在经验上是一个更好的选择(He and Wang,2008;Liu et al.,2010;Li et al.,2014)。我们发现,在适当的表示设置下,同样的结论适用于神经网络。另一方面,与单词LSTM和字符LSTM相比,lattice-LSTM是一个更好的选择。
如何更好地利用词信息一直受到研究者的关注(Gao等人,2005),其中切分信息被用作中文NER的软特征(Zhao和Kit,2008;Peng和Dredze,2015;He和Sun,2017a),联合切分和内质网的研究使用了双重分解(Xu等人,2014),多任务学习(Peng and Dredze,2016)等。我们的工作正在进行中,重点是神经表示学习。虽然上述方法会受到分割训练数据和分割错误的影响,但我们的方法不需要分词器。不考虑多任务设置,模型在概念上更简单。
利用外部信息源已经被用于NER。特别是,词汇特征已被广泛使用(Calbor等人,2011;PasSOS等人,2014;黄等人,2015;罗等人,2015)。Rei(2017)使用词级语言建模目标来增强NER训练,在大的原始文本上执行多任务学习。彼得斯等人(2017)预训练字符语言模型以增强单词表示。Yang等人(2017b)通过多任务学习开发跨领域和跨语言知识。我们利用外部数据的预训练字嵌入词典在大的自动分割文本,而半监督技术,如语言建模是正交的,也可以用于我们的lattice-LSTM模型。
lattice结构的RNNs可以看作是树结构RNNs到DAGs的自然延伸。它们已用于为NMT编码器建模运动动力学(Sun等人,2017)、依赖话语DAG(Peng等人,2017&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









