







第一步:准备数据
蘑菇数据集,英文为 mushrooms,总共有6000多 张图片。
共九种,具体信息如下:self.class_indict = ['Agaricus', 'Amanita', 'Boletus', 'Cortinarius', 'Entoloma', 'Hygrocybe', 'Lactarius', 'Russula', 'Suillus']

第二步:搭建模型
ResNet18中的"18"指的是网络中的加权层数量。具体来说,它包含了18个卷积层和全连接层。
ResNet18的架构包括:
- 1个7x7卷积层
- 16个3x3卷积层(组织成8个残差块,每个块包含2个卷积层)
- 1个全连接层
下面为大家展示的是ResNet18的整体架构。
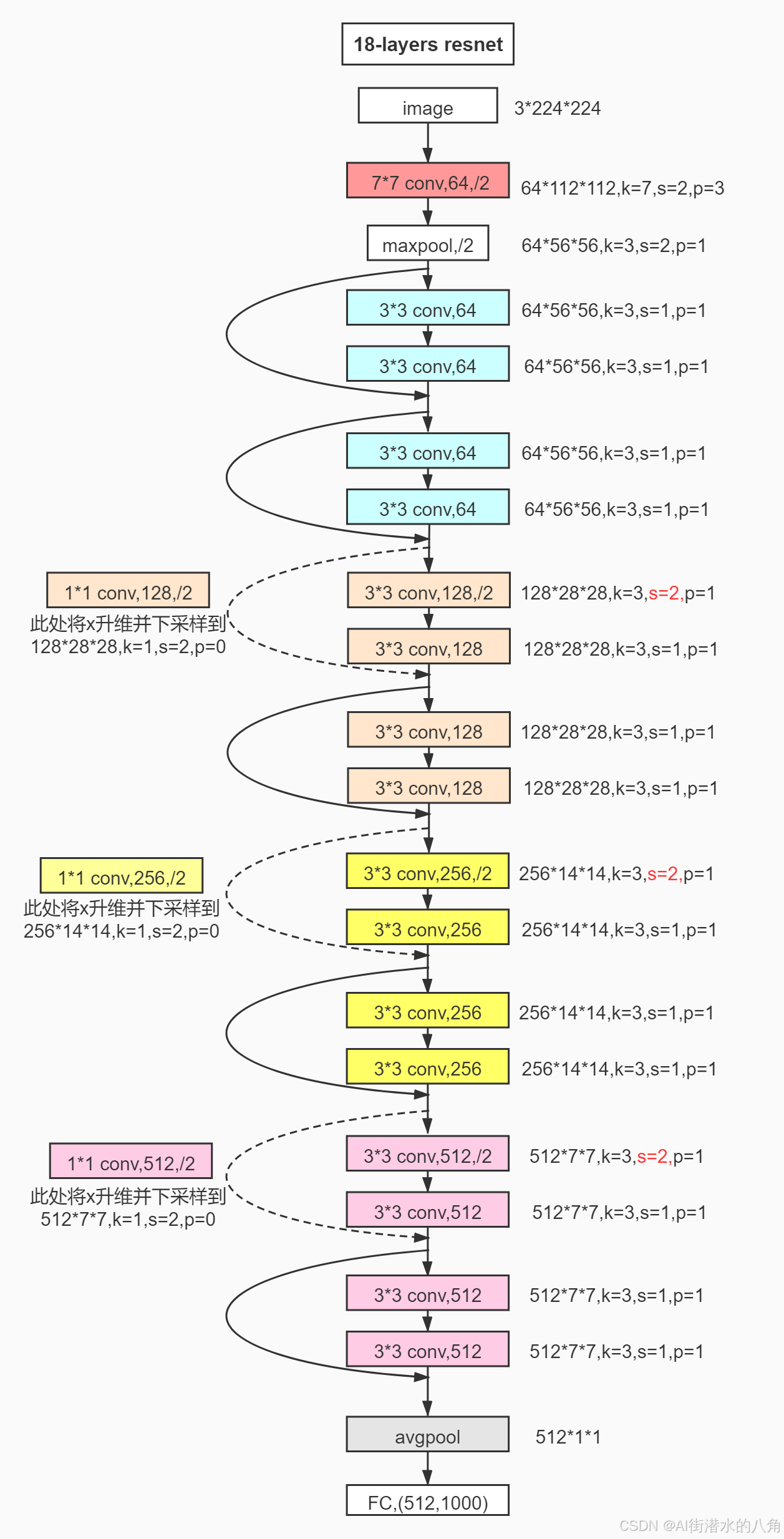
第三步:训练代码
1)损失函数为:交叉熵损失函数
2)ResNet18代码:
from functools import partial
from typing import Any, Callable, List, Optional, Type, Union
import torch
import torch.nn as nn
from torch import Tensor
from ..transforms._presets import ImageClassification
from ..utils import _log_api_usage_once
from ._api import register_model, Weights, WeightsEnum
from ._meta import _IMAGENET_CATEGORIES
from ._utils import _ovewrite_named_param, handle_legacy_interface
__all__ = [
"ResNet",
"ResNet18_Weights",
"ResNet34_Weights",
"ResNet50_Weights",
"ResNet101_Weights",
"ResNet152_Weights",
"ResNeXt50_32X4D_Weights",
"ResNeXt101_32X8D_Weights",
"ResNeXt101_64X4D_Weights",
"Wide_ResNet50_2_Weights",
"Wide_ResNet101_2_Weights",
"resnet18",
"resnet34",
"resnet50",
"resnet101",
"resnet152",
"resnext50_32x4d",
"resnext101_32x8d",
"resnext101_64x4d",
"wide_resnet50_2",
"wide_resnet101_2",
]
def conv3x3(in_planes: int, out_planes: int, stride: int = 1, groups: int = 1, dilation: int = 1) -> nn.Conv2d:
"""3x3 convolution with padding"""
return nn.Conv2d(
in_planes,
out_planes,
kernel_size=3,
stride=stride,
padding=dilation,
groups=groups,
bias=False,
dilation=dilation,
)
def conv1x1(in_planes: int, out_planes: int, stride: int = 1) -> nn.Conv2d:
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion: int = 1
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError("BasicBlock only supports groups=1 and base_width=64")
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition" https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion: int = 4
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.0)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(
self,
block: Type[Union[BasicBlock, Bottleneck]],
layers: List[int],
num_classes: int = 1000,
zero_init_residual: bool = False,
groups: int = 1,
width_per_group: int = 64,
replace_stride_with_dilation: Optional[List[bool]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
_log_api_usage_once(self)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError(
"replace_stride_with_dilation should be None "
f"or a 3-element tuple, got {replace_stride_with_dilation}"
)
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts wi 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











