







第一步:准备数据
iChallenge-PM 是百度大脑和中山大学中山眼科中心联合举办的iChallenge比赛中,提供的关于病理性近视(Pathologic Myopia,PM)的医疗类数据集,包含1200个受试者的眼底视网膜图片,训练、验证和测试数据集各400张。
- training.zip:包含训练中的图片和标签
- validation.zip:包含验证集的图片
- valid_gt.zip:包含验证集的标签
该数据集是从AI Studio平台中下载的,具体信息如下:
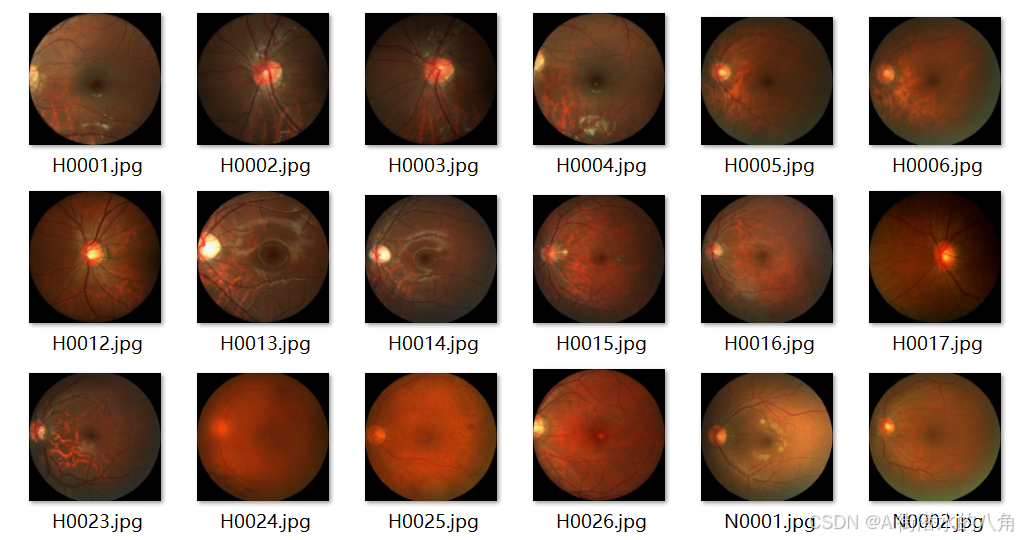
将图片分成两大类:self.class_indict = ["非病理性", "病理性近视"]
第二步:搭建模型
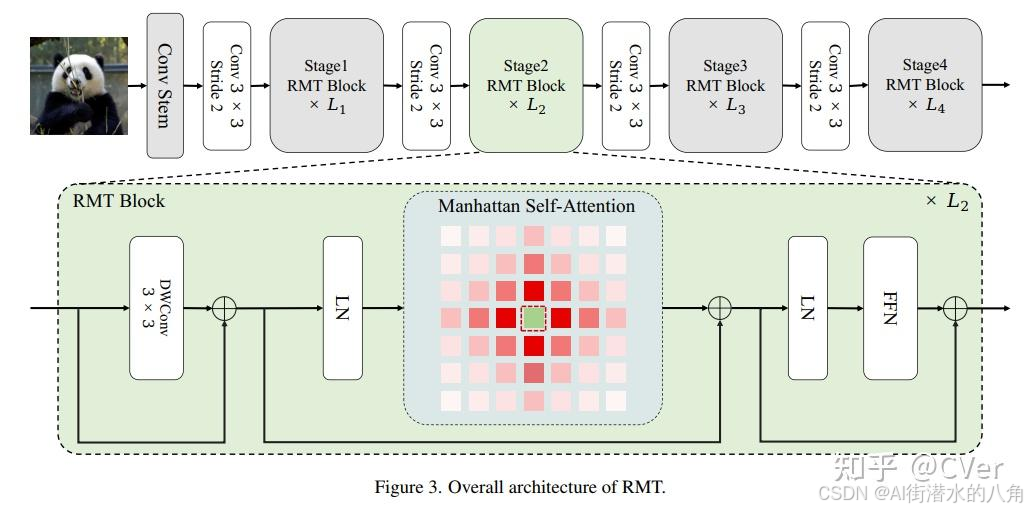
本文选择CVPR 2024 视觉新主干!RMT:RetNet遇见视觉Transformer,其网络结构如下:
第三步:训练代码
1)损失函数为:交叉熵损失函数
2)RMT代码:
import torch
import torch.nn as nn
from torch.nn.common_types import _size_2_t
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
import math
import torch
import torch.nn.functional as F
import torch.nn as nn
from timm.models.layers import DropPath, trunc_normal_
from timm.models.vision_transformer import VisionTransformer
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import time
from typing import Tuple, Union
from functools import partial
from einops import einsum
class SwishImplementation(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
result = i * torch.sigmoid(i)
ctx.save_for_backward(i)
return result
@staticmethod
def backward(ctx, grad_output):
i = ctx.saved_tensors[0]
sigmoid_i = torch.sigmoid(i)
return grad_output * (sigmoid_i * (1 + i * (1 - sigmoid_i)))
class MemoryEfficientSwish(nn.Module):
def forward(self, x):
return SwishImplementation.apply(x)
def rotate_every_two(x):
x1 = x[:, :, :, :, ::2]
x2 = x[:, :, :, :, 1::2]
x = torch.stack([-x2, x1], dim=-1)
return x.flatten(-2)
def theta_shift(x, sin, cos):
return (x * cos) + (rotate_every_two(x) * sin)
class DWConv2d(nn.Module):
def __init__(self, dim, kernel_size, stride, padding):
super().__init__()
self.conv = nn.Conv2d(dim, dim, kernel_size, stride, padding, groups=dim)
def forward(self, x: torch.Tensor):
'''
x: (b h w c)
'''
x = x.permute(0, 3, 1, 2) # (b c h w)
x = self.conv(x) # (b c h w)
x = x.permute(0, 2, 3, 1) # (b h w c)
return x
class RetNetRelPos2d(nn.Module):
def __init__(self, embed_dim, num_heads, initial_value, heads_range):
'''
recurrent_chunk_size: (clh clw)
num_chunks: (nch ncw)
clh * clw == cl
nch * ncw == nc
default: clh==clw, clh != clw is not implemented
'''
super().__init__()
angle = 1.0 / (10000 ** torch.linspace(0, 1, embed_dim // num_heads // 2))
angle = angle.unsqueeze(-1).repeat(1, 2).flatten()
self.initial_value = initial_value
self.heads_range = heads_range
self.num_heads = num_heads
decay = torch.log(
1 - 2 ** (-initial_value - heads_range * torch.arange(num_heads, dtype=torch.float) / num_heads))
self.register_buffer('angle', angle)
self.register_buffer('decay', decay)
def generate_2d_decay(self, H: int, W: int):
'''
generate 2d decay mask, the result is (HW)*(HW)
'''
index_h = torch.arange(H).to(self.decay)
index_w = torch.arange(W).to(self.decay)
grid = torch.meshgrid([index_h, index_w])
grid = torch.stack(grid, dim=-1).reshape(H * W, 2) # (H*W 2)
mask = grid[:, None, :] - grid[None, :, :] # (H*W H*W 2)
mask = (mask.abs()).sum(dim=-1)
mask = mask * self.decay[:, None, None] # (n H*W H*W)
return mask
def generate_1d_decay(self, l: int):
'''
generate 1d decay mask, the result is l*l
'''
index = torch.arange(l).to(self.decay)
mask = index[:, None] - index[None, :] # (l l)
mask = mask.abs() # (l l)
mask = mask * self.decay[:, None, None] # (n l l)
return mask
def forward(self, slen: Tuple[int], activate_recurrent=False, chunkwise_recurrent=False):
'''
slen: (h, w)
h * w == l
recurrent is not implemented
'''
if activate_recurrent:
sin = torch.sin(self.angle * (slen[0] * slen[1] - 1))
cos = torch.cos(self.angle * (slen[0] * slen[1] - 1))
retention_rel_pos = ((sin, cos), self.decay.exp())
elif chunkwise_recurrent:
index = torch.arange(slen[0] * slen[1]).to(self.decay)
sin = torch.sin(index[:, None] * self.angle[None, :]) # (l d1)
sin = sin.reshape(slen[0], slen[1], -1) # (h w d1)
cos = torch.cos(index[:, None] * self.angle[None, :]) # (l d1)
cos = cos.reshape(slen[0], slen[1], -1) # (h w d1)
mask_h = self.generate_1d_decay(slen[0])
mask_w = self.generate_1d_decay(slen[1])
retention_rel_pos = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











