









实践环境
Windows 10
Python 3.11.9
PyCharm Community Edition 2025.1
非教程,非科普文,仅记录我自己的探索实践过程。
实践预期
本地部署大模型,安装向量数据库Chroma,文本向量化后存入Chroma数据库,查询条件进行向量化后在Chroma数据库中进行查询,将查询结果与问题一起扔给大模型,大模型生成增强后的新答案。
一、安装Ollama
Ollama 是一个开源框架,专为在本地机器上便捷部署和运行大模型而设计
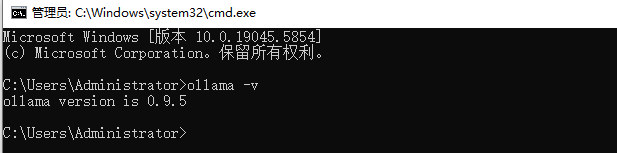
验证Ollama安装是否成功
二、本地部署向量模型
1、拉取模型
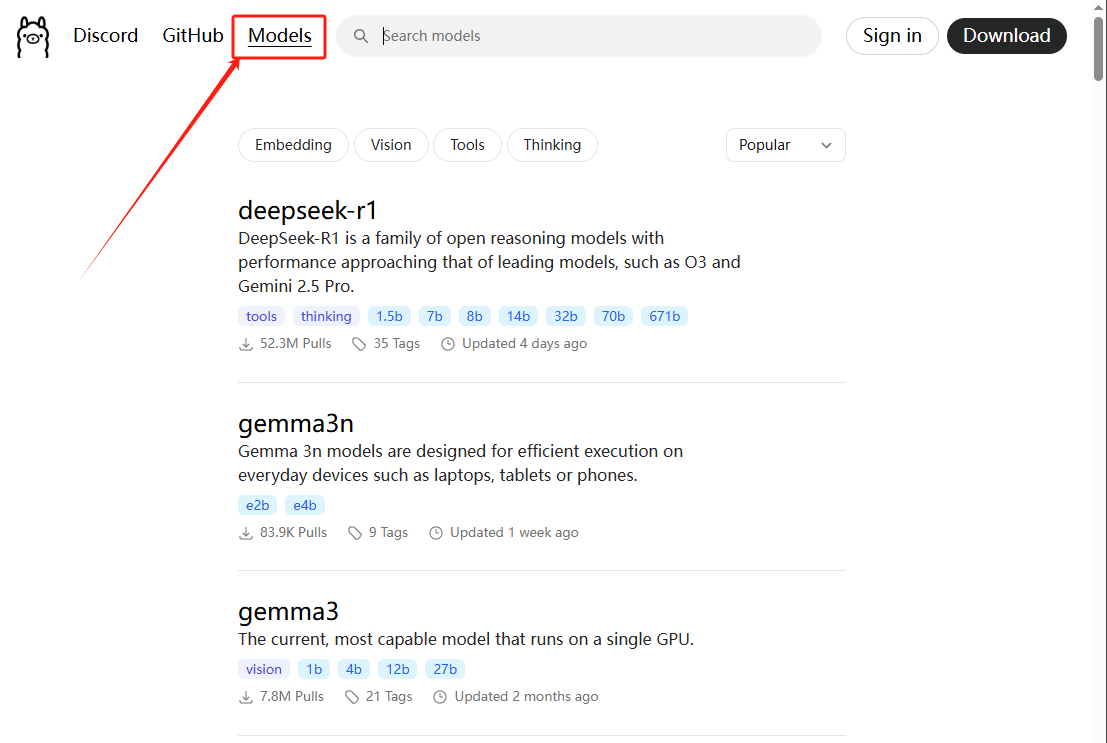
Ollama官网,进入Models页面,查看模型列表
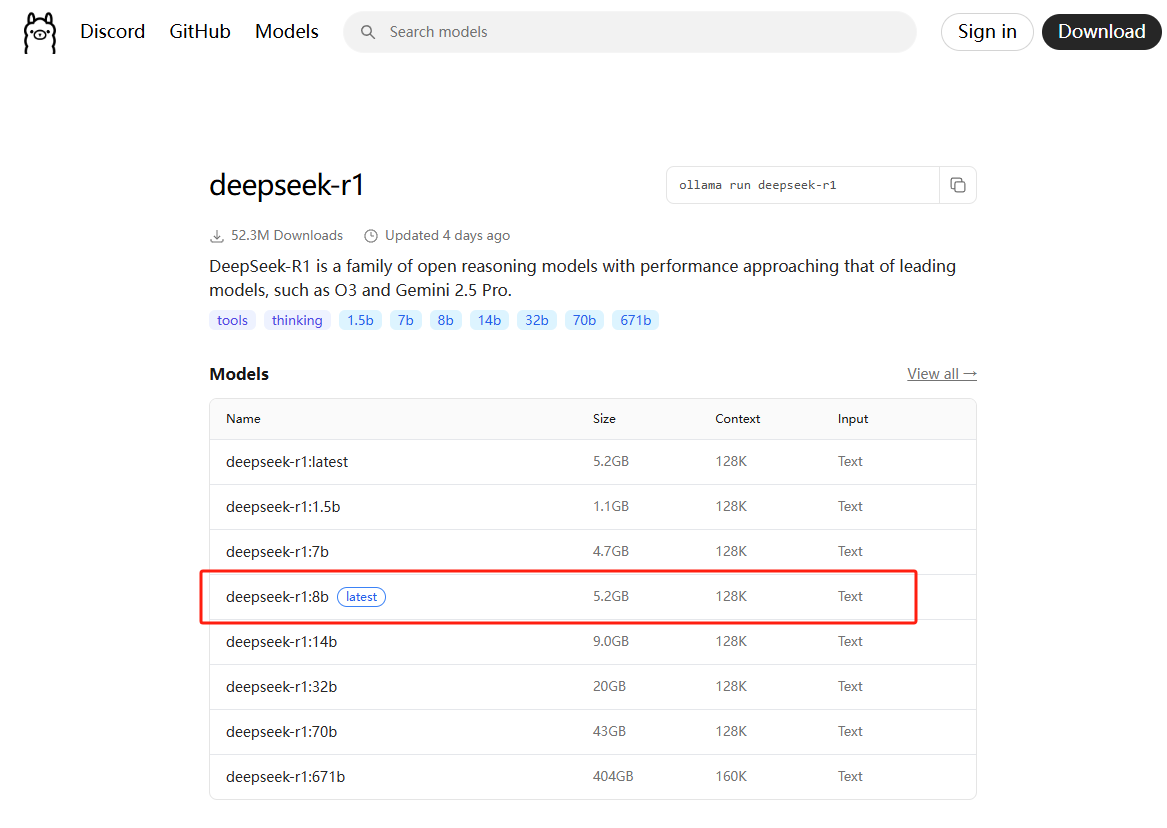
点击deepseek-r1,进入二级页面,查看模型介绍,选择要部署的版本
2、部署模型
回到Windows Cmd, 执行命令拉取模型,尝试部署 deepseek-r1:8b
ollama pull deepseek-r1:8b
模型下载比较费时间,需要耐心等待。

CMD 输入指令查看模型列表:
ollama list
3、Ollama Python库
Ollama在Python中的使用参考链接![]() https://github.com/ollama/ollama-python/tree/main
https://github.com/ollama/ollama-python/tree/main
4、测试本地模型
打开Pycharm,在终端执行命令:
pip install ollama
新建Embed.py文件
import ollama
LLM_Ollama_DEEPSEEK_R1 = "deepseek-r1:8b"
def get_embedding(text, model_name="deepseek-r1:8b"):
response = ollama.embed(model_name, text)
embedding = response['embeddings']
return embedding
print("-----------------------------------Convert String To Vector Result: \n")
vectors = get_embedding("你是谁")
print(vectors[0])
print("Vector length:", len(vectors[0]))
启动调试,控制台输出:
新建Chat.py文件
from ollama import chat
LLM_Ollama_DEEPSEEK_R1 = "deepseek-r1:8b"
messages = [
{
'role': 'user',
'content': '简述海水很咸的原因?',
},
]
response = chat(LLM_Ollama_DEEPSEEK_R1, messages=messages)
print("\n --------------------------------- Result:\n")
print(response['message']['content'])
启动调试,控制台输出:

三、使用Chroma数据库
1、参考资源
- 官方网站:https://www.trychroma.com
- GitHub:https://github.com/chroma-core/chroma
- 文档教程:https://docs.trychroma.com
2、安装Chromedb
pip install chromadb安装报错了,查看镜像源,设置镜像源,然后重新安装
#清除pip缓存
pip cache purge
#查看源列表
pip config list
#设置阿里云镜像
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
#重新安装chromadb
pip install chromadb
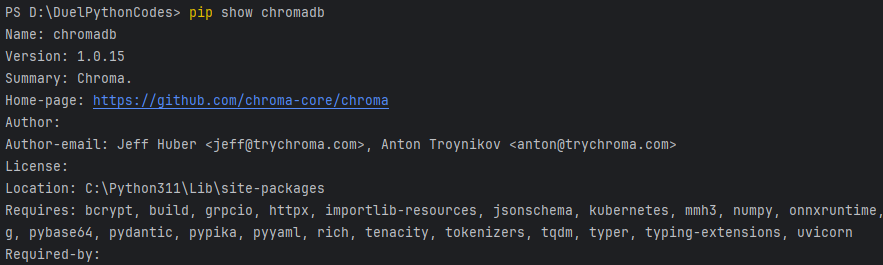
#查看chromadb是否已完成安装
pip show chromadb
安装成功
 四、 chromadb + Ollama 实现RAG应用
四、 chromadb + Ollama 实现RAG应用
1、RAG 应用流程
工作原理参考借鉴:
工作原理介绍![]() https://juejin.cn/post/7424431087894380584
https://juejin.cn/post/7424431087894380584
完整的 RAG 应用流程两个阶段:
数据准备阶段

- 数据提取: 从各种数据源(例如网页、文档、数据库等)提取需要用于 RAG 系统的文本数据。
- 分块: 将提取的文本数据分割成更小的块(例如段落、句子等),以便于后续的向量化和检索。
- 向量化: 使用嵌入模型将每个文本块转换为向量表示,捕捉其语义信息。
- 数据入库: 将文本块的向量表示存储到向量数据库中,以便于快速检索。
检索生成阶段

- 问题向量化: 将用户提出的问题转换为向量表示。
- 根据问题查询匹配数据: 使用问题向量在向量数据库中进行相似性搜索,找到与问题最相关的文本块。
- 获取索引数据: 获取与问题相关的文本块的索引信息,例如文本块的来源、位置等。
- 将数据注入 Prompt: 将检索到的相关文本块作为上下文信息,注入到 Prompt 中,提供给 LLM。
- LLM 生成答案: LLM 根据 Prompt 中的问题和上下文信息,生成最终的答案。
tips:chromadb内置了all-MiniLM-L6-v2作为嵌入模型,首次运行会下载。默认存放在C:\Users\Administrator\.cache\chroma\onnx_models\

2、实践源码
import chromadb
import json
import ollama
LLM_Ollama_DEEPSEEK_R1 = "deepseek-r1:8b"
# 创建客户端,内存模式,数据不会进行持久化
chroma_client = chromadb.Client()
# 创建集合
collection = chroma_client.get_or_create_collection(name="my_collection")
# 用于测试的文本段落
localdata_documents = [
"1919年5月4日,北京的爱国学生开展了集会、游行、罢课等活动,反对北洋政府准备在损害中国主权的《凡尔赛和约》上签字,得到社会各界广泛支持,最终形成了全国规模的爱国运动,并取得了胜利。五四运动促进了马列主义在中国的传播,在思想上、干部上为中国共产党的建立作了准备。",
"1920年春夏之交,陈独秀以马克思主义研究会为基础,多次召集会议,商讨建党问题。1920年8月 ,在上海环龙路渔阳里2号的《新青年》编辑部成立了中国共产党上海发起组,推选陈独秀为负责人,标志着中国第-一个共产党早期组织的诞生。",
"1928年4月28日,毛泽东率领的秋收起义部队,和朱德、陈毅领导的湘南起义和南昌起义部分部队在井冈山胜利会师,是中国人民解放军建军史上的重要历史事件。钢山会师后根据中共湘南特委决定,两军合编为工农革命军第四军,壮大了井冈山的革命武装力量,对巩固扩大全国第一个农村革命 根据地,推动全国革命事业发展,具有深远的意义。",
]
# 用于测试的文本段落元数据
localdata_metadatas = [
{"date": "1919年5月", "location": "北京", "event": "五四运动"},
{"date": "1920年8月", "location": "上海", "event": "共产党的早期组织"},
{"date": "1928年4月", "location": "江西", "event": "井冈山会师"},
]
# 文本向量化函数
def get_embedding(text, model_name="deepseek-r1:8b"):
response = ollama.embed(model_name, text)
embedding = response['embeddings']
return embedding
# 将文本向量化
doc_embeddings = get_embedding(localdata_documents)
# 向量化完成后,输出前5个
print(type(doc_embeddings)) # List类型
print("\n 文本内容向量化结果 : 只输出前5个 -----------------------------\n")
for i, element in enumerate(doc_embeddings):
embedding_item = element[:5]
print(embedding_item)
# 将文本、文本元数据、文本向量数据保存到Chroma数据库
# 如果不填,则在写入时,使用默认的嵌入函数进行向量化
# 本实践源码中,使用了本地化部署的大模型对文本进行了向量化处理
collection.add(
documents=localdata_documents,
metadatas=localdata_metadatas,
ids=["id1", "id2", "id3"],
embeddings=doc_embeddings,
)
# 查询条件向量化处理
query_embedding = get_embedding("井冈山会师")
print("\n 查询条件向量化结果: 只输出前5个 -----------------------------\n")
query_embedding_result = query_embedding[0][:5]
print(query_embedding_result)
# 从Chroma中查询数据,向量化后的查询条件作为参数
results = collection.query(
query_embeddings=query_embedding,
n_results=1
)
# 格式化输出查询结果
print(type(results)) # Result为Dict类型
formatted_json = json.dumps(results, indent=4, ensure_ascii=False) # 转为Json格式,输出后便于阅读
print("\n Chromadb查询结果 -----------------------------\n")
print(formatted_json)
# 将Chroma查询的结果,嵌入提示词中,提供给 deepseek-r1:8b 大模型,用于答案生成
data = results["documents"][0][0]
output = ollama.generate(
model=LLM_Ollama_DEEPSEEK_R1,
prompt=f"根据这段文字:{data}。回答这个问题:概括井冈山会师经过?",
think=False
)
print("\n LLM Result --------------------------------\n")
print(output["response"])
控制台输出:
文本内容向量化结果 : 只输出前5个 -----------------------------
[-0.0065811593, 0.0025668987, 0.0012655873, 0.0012356776, -0.0052756034]
[-0.0028774142, 0.0007679193, 0.00024022924, -0.004543038, -0.004750963]
[-0.001057489, -0.003188561, 0.011073442, 0.00017057206, -0.0072994265]
查询条件向量化结果: 只输出前5个 -----------------------------
[-0.0010892575, 0.0040866444, 0.009315611, 0.009925646, 0.001663873]
<class 'dict'>
Chromadb查询结果 -----------------------------
{
"ids": [
[
"id3"
]
],
"embeddings": null,
"documents": [
[
"1928年4月28日,毛泽东率领的秋收起义部队,和朱德、陈毅领导的湘南起义和南昌起义部分部队在井冈山胜利会师,是中国人民解放军建军史上的重要历史事件。钢山会师后根据中共湘南特委决定,两军合编为工农革命军第四军,壮大了井冈山的革命武装力量,对巩固扩大全国第一个农村革命 根据地,推动全国革命事业发展,具有深远的意义。"
]
],
"uris": null,
"included": [
"metadatas",
"documents",
"distances"
],
"data": null,
"metadatas": [
[
{
"date": "1928年4月",
"location": "江西",
"event": "井冈山会师"
}
]
],
"distances": [
[
0.16255146265029907
]
]
}
LLM Result --------------------------------
好的,我为您整理这段关于井冈山会师的文字。1928年4月,毛泽东指挥的秋收起义部队与朱德、陈毅领导的湘南起义和南昌起义余部在井冈山胜利会师。随后根据中共湘南特委指示,这两支革命力量合并组建为工农革命军第四军,进一步壮大了井冈山地区的革命武装,并对巩固和发展全国首个农村革命根据地产生了重要影响。
这段历史是中国人民解放军发展历程中的关键节点之一,对于推动当时全国范围内的革命运动具有重要意义。通过这样的会师事件,中国共产党得以整合和扩大革命力量,为后续的革命斗争奠定了坚实的基础。

















 4263
4263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











