







前言
前期回顾: Python机器学习基础篇二《为什么用Python进行机器学习》
上面这篇里面写了文本和序列相关。
我们要讨论的第二种机器学习算法是无监督学习算法。无监督学习包括没有已知输出、没 有老师指导学习算法的各种机器学习。在无监督学习中,学习算法只有输入数据,并需要 从这些数据中提取知识。
3.1 无监督学习的类型
本章将研究两种类型的无监督学习:数据集变换与聚类。
数据集的无监督变换(unsupervised transformation)是创建数据新的表示的算法,与数据的 原始表示相比,新的表示可能更容易被人或其他机器学习算法所理解。无监督变换的一个 常见应用是降维(dimensionality reduction),它接受包含许多特征的数据的高维表示,并找到表示该数据的一种新方法,用较少的特征就可以概括其重要特性。降维的一个常见应用是为了可视化将数据降为二维。
无监督变换的另一个应用是找到“构成”数据的各个组成部分。这方面的一个例子就是对文本文档集合进行主题提取。这里的任务是找到每个文档中讨论的未知主题,并学习每个 文档中出现了哪些主题。这可以用于追踪社交媒体上的话题讨论,比如选举、枪支管制或流行歌手等话题。
与之相反,聚类算法(clustering algorithm)将数据划分成不同的组,每组包含相似的物项。思考向社交媒体网站上传照片的例子。为了方便你整理照片,网站可能想要将同一个 人的照片分在一组。但网站并不知道每张照片是谁,也不知道你的照片集中出现了多少个 人。明智的做法是提取所有的人脸,并将看起来相似的人脸分在一组。但愿这些人脸对应 同一个人,这样图片的分组也就完成了。
3.2 无监督学习的挑战
无监督学习的一个主要挑战就是评估算法是否学到了有用的东西。无监督学习算法一般用于不包含任何标签信息的数据,所以我们不知道正确的输出应该是什么。因此很难判断一个模型是否“表现很好”。例如,假设我们的聚类算法已经将所有的侧脸照片和所有的正面照片进行分组。这肯定是人脸照片集合的一种可能的划分方法,但并不是我们想要的那种方法。然而,我们没有办法“告诉”算法我们要的是什么,通常来说,评估无监督算法结果的唯一方法就是人工检查。
因此,如果数据科学家想要更好地理解数据,那么无监督算法通常可用于探索性的目的, 而不是作为大型自动化系统的一部分。无监督算法的另一个常见应用是作为监督算法的预 处理步骤。学习数据的一种新表示,有时可以提高监督算法的精度,或者可以减少内存占 用和时间开销。
在开始学习“真正的”无监督算法之前,我们先简要讨论几种简单又常用的预处理方法。 虽然预处理和缩放通常与监督学习算法一起使用,但缩放方法并没有用到与“监督”有关的信息,所以它是无监督的。
3.3 预处理与缩放
上一章我们学到,一些算法(如神经网络和 SVM)对数据缩放非常敏感。因此,通常的做法是对特征进行调节,使数据表示更适合于这些算法。通常来说,这是对数据的一种简单的按特征的缩放和移动。下面的代码(图 3-1)给出了一个简单的例子:
In[2]:
mglearn.plots.plot_scaling()
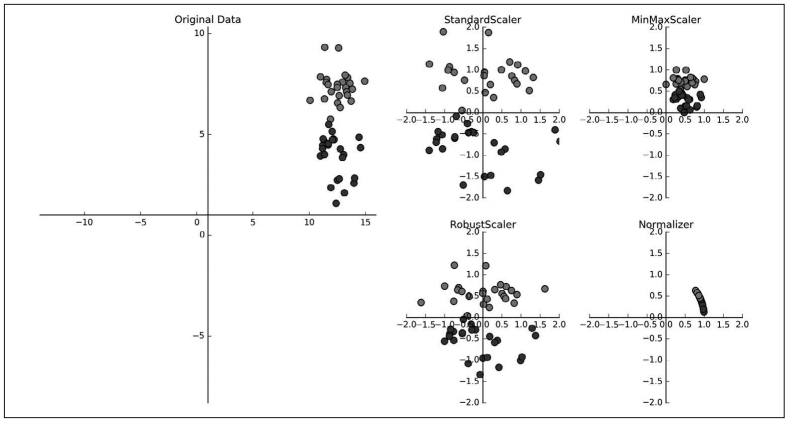
图 3-1:对数据集缩放和预处理的各种方法
3.3.1 不同类型的预处理
在图 3-1 中,第一张图显示的是一个模拟的有两个特征的二分类数据集。第一个特征(x 轴)位于 10 到 15 之间。第二个特征(y 轴)大约位于 1 到 9 之间。
接下来的 4 张图展示了 4 种数据变换方法,都生成了更加标准的范围。scikit-learn 中 的 StandardScaler 确保每个特征的平均值为 0、方差为 1,使所有特征都位于同一量级。但这种缩放不能保证特征任何特定的最大值和最小值。RobustScaler 的工作原理与 StandardScaler 类似,确保每个特征的统计属性都位于同一范围。但 RobustScaler 使用的 是中位数和四分位数 1 ,而不是平均值和方差。这样 RobustScaler 会忽略与其他点有很大不 同的数据点(比如测量误差)。这些与众不同的数据点也叫异常值(outlier),可能会给其他缩放方法造成麻烦。
与之相反,MinMaxScaler 移动数据,使所有特征都刚好位于 0 到 1 之间。对于二维数据集来说,所有的数据都包含在 x 轴 0 到 1 与 y 轴 0 到 1 组成的矩形中。
最后,Normalizer 用到一种完全不同的缩放方法。它对每个数据点进行缩放,使得特征向量的欧式长度等于 1。换句话说,它将一个数据点投射到半径为 1 的圆上(对于更高维度的情况,是球面)。这意味着每个数据点的缩放比例都不相同(乘以其长度的倒数)。如果只有数据的方向(或角度)是重要的,而特征向量的长度无关紧要,那么通常会使用这种 归一化。
3.3.2 应用数据变换
前面我们已经看到不同类型的变换的作用,下面利用 scikit-learn 来应用这些变换。我们 将使用第 2 章见过的 cancer 数据集。通常在应用监督学习算法之前使用预处理方法(比 如缩放)。举个例子,比如我们想要将核 SVM(SVC)应用在 cancer 数据集上,并使用 MinMaxScaler 来预处理数据。首先加载数据集并将其分为训练集和测试集(我们需要分开 的训练集和数据集来对预处理后构建的监督模型进行评估):
In[3]:
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target,
random_state=1)
print(X_train.shape)
print(X_test.shape)
Out[3]:
(426, 30)
(143, 30)
提醒一下,这个数据集包含 569 个数据点,每个数据点由 30 个测量值表示。我们将数据 集分成包含 426 个样本的训练集与包含 143 个样本的测试集。
与之前构建的监督模型一样,我们首先导入实现预处理的类,然后将其实例化:
In[4]:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
然后,使用 fit 方法拟合缩放器(scaler),并将其应用于训练数据。对于 MinMaxScaler 来 说,fit 方法计算训练集中每个特征的最大值和最小值。与第 2 章中的分类器和回归器 (regressor)不同,在对缩放器调用 fit 时只提供了 X_train,而不用 y_train:
In[5]:
scaler.fit(X_train)
Out[5]:
MinMaxScaler(copy=True, feature_range=(0, 1))
为了应用刚刚学习的变换(即对训练数据进行实际缩放),我们使用缩放器的 transform 方法。在 scikit-learn 中,每当模型返回数据的一种新表示时,都可以使用 transform 方法:
In[6]:
# 变换数据
X_train_scaled = scaler.transform(X_train)
# 在缩放之前和之后分别打印数据集属性
print("transformed shape: {}".format(X_train_scaled.shape))
print("per-feature minimum before scaling:\n {}".format(X_train.min(axis=0)))
print("per-feature maximum before scaling:\n {}".format(X_train.max(axis=0)))
print("per-feature minimum after scaling:\n {}".format(
X_train_scaled.min(axis=0)))
print("per-feature maximum after scaling:\n {}".format(
X_train_scaled.max(axis=0)))
Out[6]:
transformed shape: (426, 30)
per-feature minimum before scaling:
[ 6.98 9.71 43.79 143.50 0.05 0.02 0. 0. 0.11
0.05 0.12 0.36 0.76 6.80 0. 0. 0. 0.
0.01 0. 7.93 12.02 50.41 185.20 0.07 0.03 0.
0. 0.16 0.06]
per-feature maximum before scaling:
[ 28.11 39.28 188.5 2501.0 0.16 0.29 0.43 0.2
0.300 0.100 2.87 4.88 21.98 542.20 0.03 0.14
0.400 0.050 0.06 0.03 36.04 49.54 251.20 4254.00
0.220 0.940 1.17 0.29 0.58 0.15]
per-feature minimum after scaling:
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
per-feature maximum after scaling:
[ 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
变换后的数据形状与原始数据相同,特征只是发生了移动和缩放。你可以看到,现在所有特征都位于 0 到 1 之间,这也符合我们的预期。
为了将 SVM 应用到缩放后的数据上,还需要对测试集进行变换。这可以通过对 X_test 调用 transform 方法来完成:
In[7]:
# 对测试数据进行变换
X_test_scaled = scaler.transform(X_test)
# 在缩放之后打印测试数据的属性
print("per-feature minimum after scaling:\n{}".format(X_test_scaled.min(axis=0)))
print("per-feature maximum after scaling:\n{}".format(X_test_scaled.max(axis=0)))
Out[7]:
per-feature minimum after scaling:
[ 0.034 0.023 0.031 0.011 0.141 0.044 0. 0. 0.154 -0.006
-0.001 0.006 0.004 0.001 0.039 0.011 0. 0. -0.032 0.007
0.027 0.058 0.02 0.009 0.109 0.026 0. 0. -0. -0.002]
per-feature maximum after scaling:
[ 0.958 0.815 0.956 0.894 0.811 1.22 0.88 0.933 0.932 1.037
0.427 0.498 0.441 0.284 0.487 0.739 0.767 0.629 1.337 0.391
0.896 0.793 0.849 0.745 0.915 1.132 1.07 0.924 1.205 1.631]
你可以发现,对测试集缩放后的最大值和最小值不是 1 和 0,这或许有些出乎意料。有些特征甚至在 0~1 的范围之外!对此的解释是,MinMaxScaler(以及其他所有缩放器)总是对训练集和测试集应用完全相同的变换。也就是说,transform 方法总是减去训练集的最小值,然后除以训练集的范围,而这两个值可能与测试集的最小值和范围并不相同。
3.3.3 对训练数据和测试数据进行相同的缩放
为了让监督模型能够在测试集上运行,对训练集和测试集应用完全相同的变换是很重要 的。如果我们使用测试集的最小值和范围,下面这个例子(图 3-2)展示了会发生什么:
In[8]:
from sklearn.datasets import make_blobs
# 构造数据
X, _ = make_blobs(n_samples=50, centers=5, random_state=4, cluster_std=2)
# 将其分为训练集和测试集
X_train, X_test = train_test_split(X, random_state=5, test_size=.1)
# 绘制训练集和测试集
fig, axes = plt.subplots(1, 3, figsize=(13, 4))
axes[0].scatter(X_train[:, 0], X_train[:, 1],
c=mglearn.cm2(0), label="Training set", s=60)
axes[0].scatter(X_test[:, 0], X_test[:, 1], marker='^',
c=mglearn.cm2(1), label="Test set", s=60)
axes[0].legend(loc='upper left')
axes[0].set_title("Original Data")
# 利用MinMaxScaler缩放数据
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 将正确缩放的数据可视化
axes[1].scatter(X_train_scaled[:, 0], X_train_scaled[:, 1],
c=mglearn.cm2(0), label="Training set", s=60)
axes[1].scatter(X_test_scaled[:, 0], X_test_scaled[:, 1], marker='^',
c=mglearn.cm2(1), label="Test set", s=60)
axes[1].set_title("Scaled Data")
# 单独对测试集进行缩放
# 使得测试集的最小值为0,最大值为1
# 千万不要这么做!这里只是为了举例
test_scaler = MinMaxScaler()
test_scaler.fit(X_test)
X_test_scaled_badly = test_scaler.transform(X_test)
# 将错误缩放的数据可视化
axes[2].scatter(X_train_scaled[:, 0], X_train_scaled[:, 1],
c=mglearn.cm2(0), label="training set", s=60)
axes[2].scatter(X_test_scaled_badly[:, 0], X_test_scaled_badly[:, 1],
marker='^', c=mglearn.cm2(1), label="test set", s=60)
axes[2].set_title("Improperly Scaled Data")
for ax in axes:
ax.set_xlabel("Feature 0")
ax.set_ylabel("Feature 1")
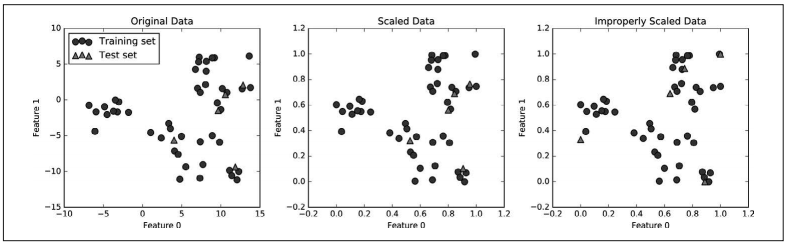
图 3-2:对左图中的训练数据和测试数据同时缩放的效果(中)和分别缩放的效果(右)
第一张图是未缩放的二维数据集,其中训练集用圆形表示,测试集用三角形表示。第二张 图中是同样的数据,但使用 MinMaxScaler 缩放。这里我们调用 fit 作用在训练集上,然后 调用 transform 作用在训练集和测试集上。你可以发现,第二张图中的数据集看起来与第 一张图中的完全相同,只是坐标轴刻度发生了变化。现在所有特征都位于 0 到 1 之间。你 还可以发现,测试数据(三角形)的特征最大值和最小值并不是 1 和 0。
第三张图展示了如果我们对训练集和测试集分别进行缩放会发生什么。在这种情况下,对 训练集和测试集而言,特征的最大值和最小值都是 1 和 0。但现在数据集看起来不一样。 测试集相对训练集的移动不一致,因为它们分别做了不同的缩放。我们随意改变了数据的排列。这显然不是我们想要做的事情。
再换一种思考方式,想象你的测试集只有一个点。对于一个点而言,无法将其正确地缩放以满足 MinMaxScaler 的最大值和最小值的要求。但是,测试集的大小不应该对你的处理方式有影响。
3.3.4 预处理对监督学习的作用
现在我们回到 cancer 数据集,观察使用 MinMaxScaler 对学习 SVC 的作用(这是一种不同的 方法,实现了与第 2 章中相同的缩放)。首先,为了对比,我们再次在原始数据上拟合 SVC:
In[10]:
from sklearn.svm import SVC
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target,
random_state=0)
svm = SVC(C=100)
svm.fit(X_train, y_train)
print("Test set accuracy: {:.2f}".format(svm.score(X_test, y_test)))
Out[10]:
Test set accuracy: 0.63
下面先用 MinMaxScaler 对数据进行缩放,然后再拟合 SVC:
In[11]:
# 使用0-1缩放进行预处理
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 在缩放后的训练数据上学习SVM
svm.fit(X_train_scaled, y_train)
# 在缩放后的测试集上计算分数
print("Scaled test set accuracy: {:.2f}".format(
svm.score(X_test_scaled, y_test)))
Out[11]:
Scaled test set accuracy: 0.97
正如我们上面所见,数据缩放的作用非常显著。虽然数据缩放不涉及任何复杂的数学,但良好的做法仍然是使用 scikit-learn 提供的缩放机制,而不是自己重新实现它们,因为即使在这些简单的计算中也容易犯错。
你也可以通过改变使用的类将一种预处理算法轻松替换成另一种,因为所有的预处理类都 具有相同的接口,都包含 fit 和 transform 方法:
In[12]:
# 利用零均值和单位方差的缩放方法进行预处理
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 在缩放后的训练数据上学习SVM
svm.fit(X_train_scaled, y_train)
# 在缩放后的测试集上计算分数
print("SVM test accuracy: {:.2f}".format(svm.score(X_test_scaled, y_test)))
Out[12]:
SVM test accuracy: 0.96
前面我们已经看到了用于预处理的简单数据变换的工作原理,下面继续学习利用无监督学习进行更有趣的变换。
3.4 降维、特征提取与流形学习
前面讨论过,利用无监督学习进行数据变换可能有很多种目的。最常见的目的就是可视 化、压缩数据,以及寻找信息量更大的数据表示以用于进一步的处理。
为了实现这些目的,最简单也最常用的一种算法就是主成分分析。我们也将学习另外两种 算法:非负矩阵分解(NMF)和 t-SNE,前者通常用于特征提取,后者通常用于二维散点 图的可视化。
3.4.1 主成分分析
主成分分析(principal component analysis,PCA)是一种旋转数据集的方法,旋转后的特征在统计上不相关。在做完这种旋转之后,通常是根据新特征对解释数据的重要性来选择它的一个子集。下面的例子(图 3-3)展示了 PCA 对一个模拟二维数据集的作用:
In[13]:
mglearn.plots.plot_pca_illustration()
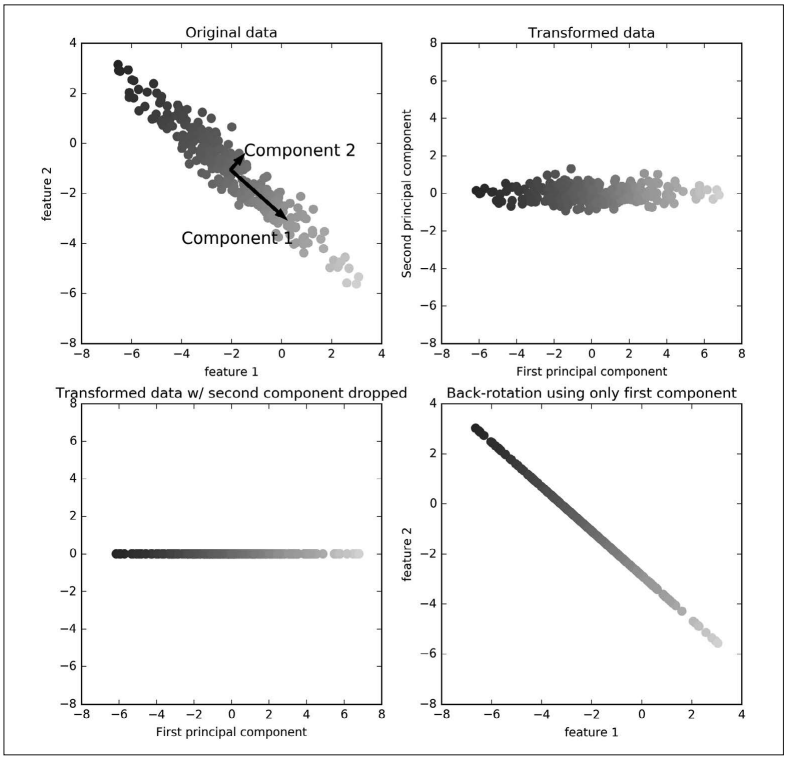
图 3-3:用 PCA 做数据变换
第一张图(左上)显示的是原始数据点,用不同颜色加以区分。算法首先找到方差最大的 方向,将其标记为“成分 1”(Component 1)。这是数据中包含最多信息的方向(或向量), 换句话说,沿着这个方向的特征之间最为相关。然后,算法找到与第一个方向正交(成直 角)且包含最多信息的方向。在二维空间中,只有一个成直角的方向,但在更高维的空间 中会有(无穷)多的正交方向。虽然这两个成分都画成箭头,但其头尾的位置并不重要。 我们也可以将第一个成分画成从中心指向左上,而不是指向右下。利用这一过程找到的方 向被称为主成分(principal component),因为它们是数据方差的主要方向。一般来说,主 成分的个数与原始特征相同。
第二张图(右上)显示的是同样的数据,但现在将其旋转,使得第一主成分与 x 轴平行且 第二主成分与 y 轴平行。在旋转之前,从数据中减去平均值,使得变换后的数据以零为中 心。在 PCA 找到的旋转表示中,两个坐标轴是不相关的,也就是说,对于这种数据表示, 除了对角线,相关矩阵全部为零。
我们可以通过仅保留一部分主成分来使用 PCA 进行降维。在这个例子中,我们可以仅保 留第一个主成分,正如图 3-3 中第三张图所示(左下)。这将数据从二维数据集降为一维数 据集。但要注意,我们没有保留原始特征之一,而是找到了最有趣的方向(第一张图中从 左上到右下)并保留这一方向,即第一主成分。
最后,我们可以反向旋转并将平均值重新加到数据中。这样会得到图 3-3 最后一张图中的 数据。这些数据点位于原始特征空间中,但我们仅保留了第一主成分中包含的信息。这种 变换有时用于去除数据中的噪声影响,或者将主成分中保留的那部分信息可视化。
- 将 PCA 应用于 cancer 数据集并可视化
PCA 最常见的应用之一就是将高维数据集可视化。正如第 1 章中所说,对于有两个以上特 征的数据,很难绘制散点图。对于 Iris(鸢尾花)数据集,我们可以创建散点图矩阵(见 第 1 章图 1-3),通过展示特征所有可能的两两组合来展示数据的局部图像。但如果我们想 要查看乳腺癌数据集,即便用散点图矩阵也很困难。这个数据集包含 30 个特征,这就导 致需要绘制 30 * 14 = 420 张散点图!我们永远不可能仔细观察所有这些图像,更不用说试 图理解它们了。
不过我们可以使用一种更简单的可视化方法——对每个特征分别计算两个类别(良性肿瘤 和恶性肿瘤)的直方图(见图 3-4)。
In[14]:
fig, axes = plt.subplots(15, 2, figsize=(10, 20))
malignant = cancer.data[cancer.target == 0]
benign = cancer.data[cancer.target == 1]
ax = axes.ravel()
for i in range(30):
_, bins = np.histogram(cancer.data[:, i], bins=50)
ax[i].hist(malignant[:, i], bins=bins, color=mglearn.cm3(0), alpha=.5)
ax[i].hist(benign[:, i], bins=bins, color=mglearn.cm3(2), alpha=.5)
ax[i].set_title(cancer.feature_names[i])
ax[i].set_yticks(())
ax[0].set_xlabel("Feature magnitude")
ax[0].set_ylabel("Frequency")
ax[0].legend(["malignant", "benign"], loc="best")
fig.tight_layout()
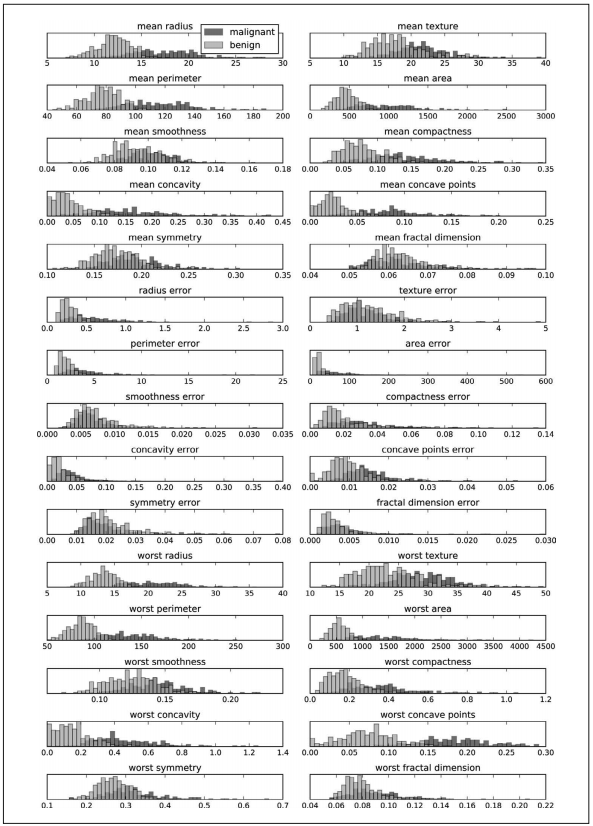
图 3-4:乳腺癌数据集中每个类别的特征直方图
这里我们为每个特征创建一个直方图,计算具有某一特征的数据点在特定范围内(叫作 bin)的出现频率。每张图都包含两个直方图,一个是良性类别的所有点(蓝色),一个是 恶性类别的所有点(红色)。这样我们可以了解每个特征在两个类别中的分布情况,也可 以猜测哪些特征能够更好地区分良性样本和恶性样本。例如,“smoothness error”特征似乎 没有什么信息量,因为两个直方图大部分都重叠在一起,而“worst concave points”特征 看起来信息量相当大,因为两个直方图的交集很小。
但是,这种图无法向我们展示变量之间的相互作用以及这种相互作用与类别之间的关系。 利用 PCA,我们可以获取到主要的相互作用,并得到稍为完整的图像。我们可以找到前两 个主成分,并在这个新的二维空间中用散点图将数据可视化。
在应用 PCA 之前,我们利用 StandardScaler 缩放数据,使每个特征的方差均为 1:
In[15]:
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
scaler = StandardScaler()
scaler.fit(cancer.data)
X_scaled = scaler.transform(cancer.data)
学习并应用 PCA 变换与应用预处理变换一样简单。我们将 PCA 对象实例化,调用 fit 方 法找到主成分,然后调用 transform 来旋转并降维。默认情况下,PCA 仅旋转(并移动) 数据,但保留所有的主成分。为了降低数据的维度,我们需要在创建 PCA 对象时指定想要 保留的主成分个数:
In[16]:
from sklearn.decomposition import PCA
# 保留数据的前两个主成分
pca = PCA(n_components=2)
# 对乳腺癌数据拟合PCA模型
pca.fit(X_scaled)
# 将数据变换到前两个主成分的方向上
X_pca = pca.transform(X_scaled)
print("Original shape: {}".format(str(X_scaled.shape)))
print("Reduced shape: {}".format(str(X_pca.shape)))
Out[16]:
Original shape: (569, 30)
Reduced shape: (569, 2)
现在我们可以对前两个主成分作图(图 3-5):
In[17]:
# 对第一个和第二个主成分作图,按类别着色
plt.figure(figsize=(8, 8))
mglearn.discrete_scatter(X_pca[:, 0], X_pca[:, 1], cancer.target)
plt.legend(cancer.target_names, loc="best")
plt.gca().set_aspect("equal" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1490
1490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









