







 本文详细介绍Scrapy爬虫的基本概念、配置与调试方法。涵盖爬虫架构组件如Scheduler、Downloader、ItemPipeline等,以及创建与启动爬虫的步骤。通过实例演示数据抓取过程,适合初学者快速上手。
本文详细介绍Scrapy爬虫的基本概念、配置与调试方法。涵盖爬虫架构组件如Scheduler、Downloader、ItemPipeline等,以及创建与启动爬虫的步骤。通过实例演示数据抓取过程,适合初学者快速上手。
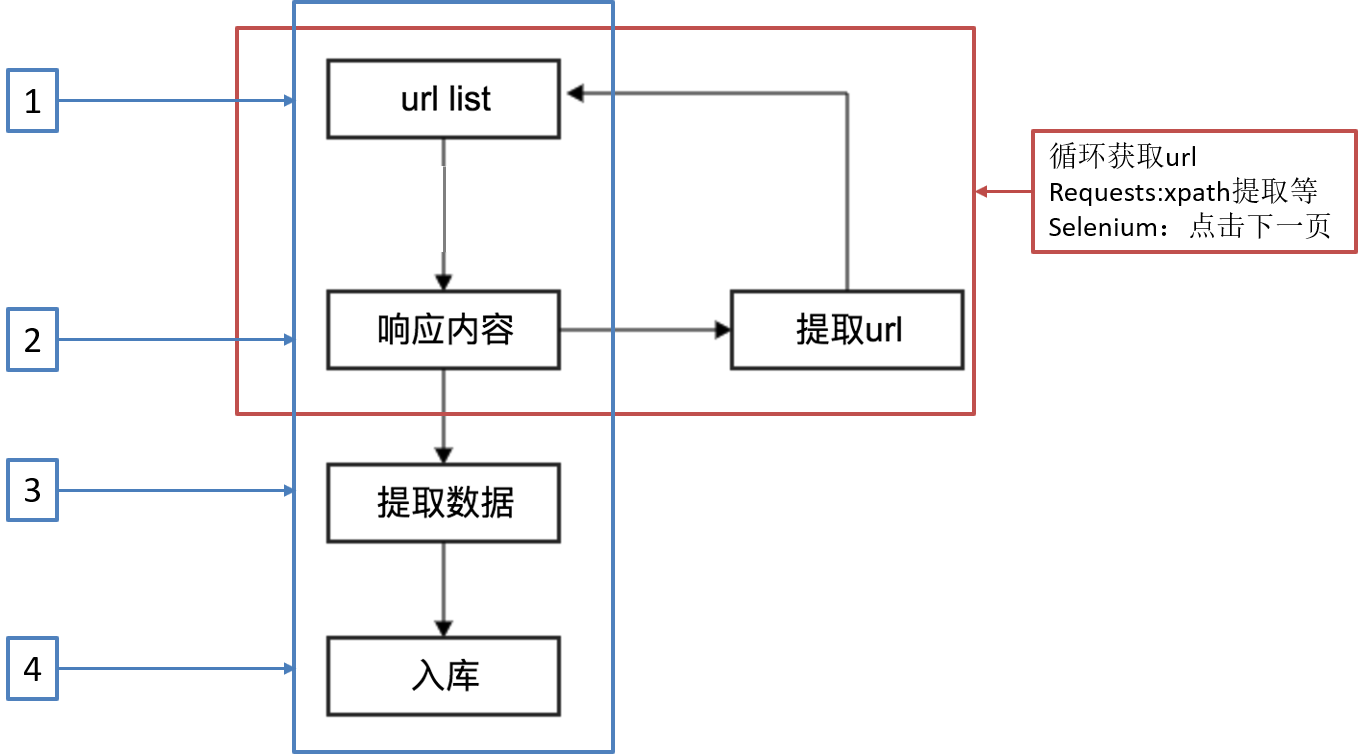
【传统爬虫流程】
1、scrapy爬虫基本概念
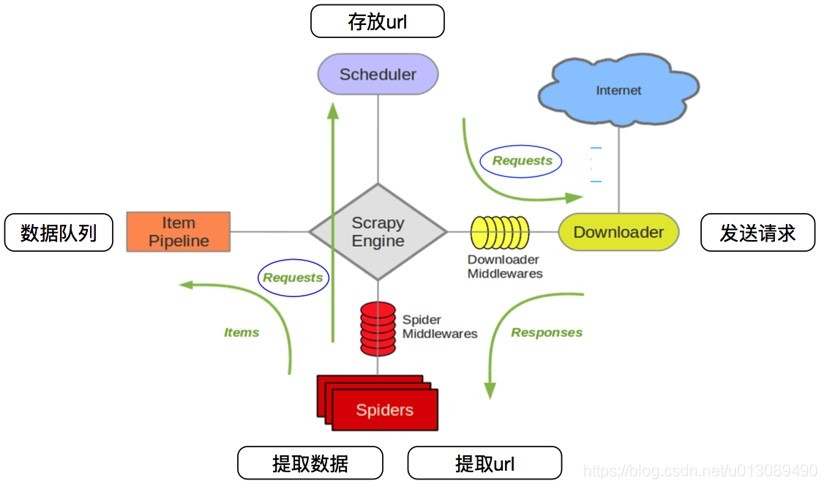
【概念说明】
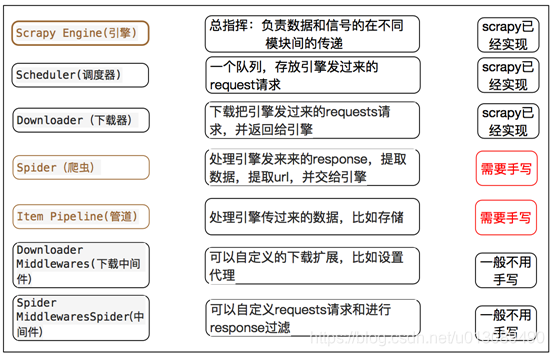
(1)Scheduler:是一个调度器;
(2)Downloader:下载器;
(3)Item Pipeline:数据管道
(4)Scarpy Engine:爬虫引擎
(5)Downloader Middlewares:下载中间件
(6)Spider Middlewares:爬虫中间件
【创建一个scrapy爬虫的步骤】
第一步:创建一个项目, scrapy startproject myspider
第二步:生成一个爬虫
cd myspider
scrapy genspider wzy “hnwznz.com”

【特别提示】在scrapy.cfg文件中不能有中文,包括注释也不能有中文。
如何启动一个爬虫:scarpy crawl 爬虫名
2、scrapy爬虫
【简单爬虫示例】
import scrapy
class WzySpider(scrapy.Spider):
'''
该类必须继承scrapy.Spider
'''
# name表示爬虫的名称,通过scrapy genspider 爬虫名称 域名
name = 'wzy'
# allowed_domains表示允许爬取的范围
allowed_domains = ['itcast.cn']
# start_urlsb:最开始请求的url地址
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
def parse(self, response):
'''
parse()这个方法名称
:param response:
:return:
'''
#处理start_url地址的响应
print("*"*100)
li_list = response.xpath("//div[@class='tea_con']//li")
print(len(li_list))
print("&"*100)
content_list=[]
for li in li_list:
item={}
item["name"] = li.xpath(".//h3/text()").extract_first()
item["title"] = li.xpath(".//h4/text()").extract_first()
# print(item)
#注意yield不能列表,必须是Requet、BaseItem、dict或者Nnoe四种类型
yield item
3、scrapy常用简单配置
3.1、如何调试scrapy爬虫
如果是在window环境下,首先我们需要安装pywin32模块(pip3 install pywin32),否则无法调试。
在爬虫目录下创建一个main.py文件,如下图
import sys
import os
from scrapy.cmdline import execute
# os.path.abspath(__file__)返回文件的完整路径,F:\PycharmProjects\scrapy_stu\tencent\main.py
# os.path.dirname(__file__) 返回文件的目录,F:/PycharmProjects/scrapy_stu/tencent
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy", "crawl", "wzy"])
# ModuleNotFoundError: No module named 'win32api'
# pywin32

















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









