







一、FM算法
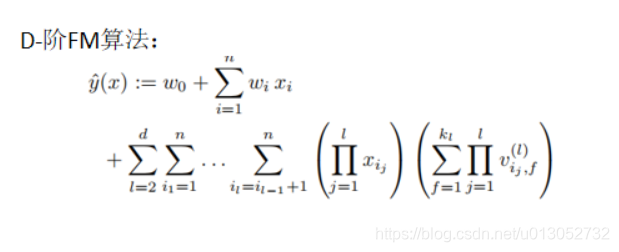
因为计算量大,一般FM采用2阶特征组合的方式
实际上高阶/非线性的特征组合适合采用深度模型
是FM的核心思想,使得稀疏数据下学习不充分的问题也能得到充分解决 => 可提供的非零样本大大增加
二、FM算法的应用场景

三、libFM算法
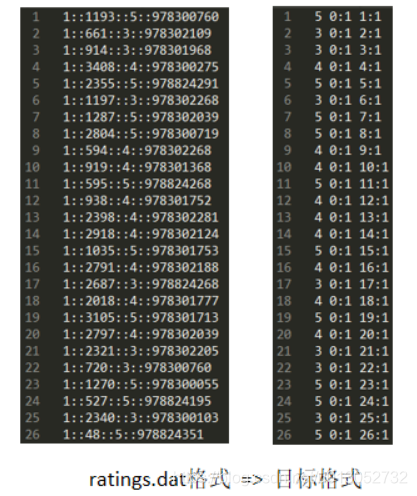
使用libFM自带的libsvm格式转换
triple_format_to_libfm.pl (perl文件)
-target 目标变量
-delete_column 不需要的变量
perl triple_format_to_libfm.pl -in ratings.dat -target 2 -delete_column 3 -separator "::"
自动将.dat文件 => .libfm文件
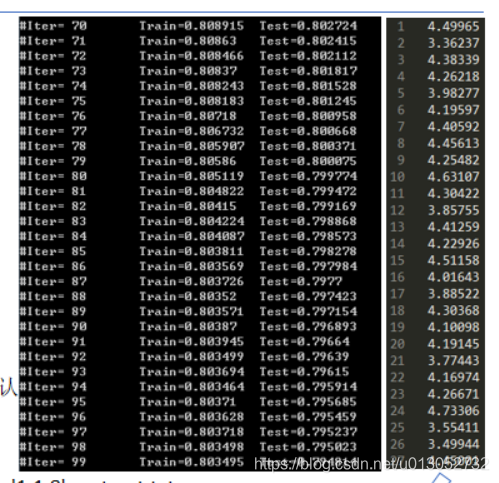
使用libFM训练FM模型
-train 指定训练集,libfm格式或者二进制文件
-test 指定测试集,libfm格式或者二进制文件
-task,说明任务类型classification还是regression dim,指定k0,k1,k2,
-iter,迭代次数,默认100
-method,优化方式,可以使用SGD, SGDA, ALS, MCMC,默认为MCMC
-out,指定输出文件 libFM -task r -train ratings.dat.libfm -test ratings.dat.libfm -dim '1,1,8' -out out.txt
四、 使用libFM进行分类
Titanic数据集,train.csv和test.csv
Step1,对train.csv和test.csv进行处理 去掉列名,针对test.csv增加虚拟target列(值设置为1) Step2,将train.csv, test.csv转换成libfm格式
perl triple_format_to_libfm.pl -in ./titanic/train.csv -target 1 -delete_column 0 -separator ","
perl triple_format_to_libfm.pl -in ./titanic/test.csv -target 1 -delete_column 0 -separator ","
Titanic数据集,train.csv和test.csv
Step3,使用libfm进行训练,输出结果文件 titanic_out.txt libFM -task c -train ./titanic/train.csv.libfm -test ./titanic/test.csv.libfm -dim '1,1,8' -out titanic_out.txt
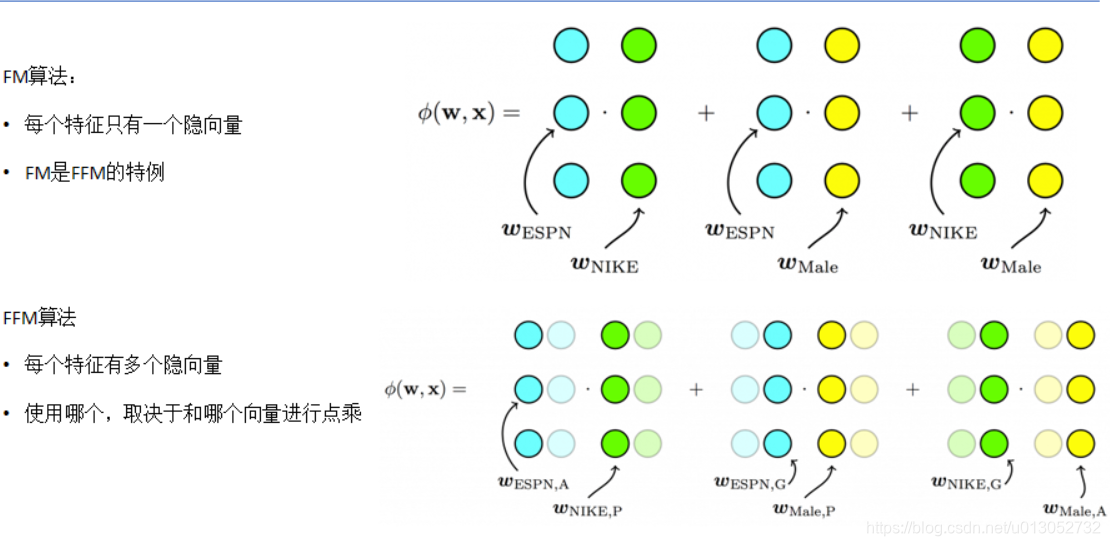
五、FFM算法



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









