










目录
前言:
以前搞算法应用的,不太懂底层,收集一些定义和概念,基本上是搜寻英文内容然后机翻加个人总结。
讲错的话欢迎指出。
基础
NUMA
NUMA(Non Uniform Memory Access)技术可以使众多服务器像单一系统那样运转,同时保留小系统便于编程和管理的优点。基于电子商务应用对内存访问提出的更高的要求,NUMA也向复杂的结构设计提出了挑战。
非统一内存访问(NUMA)是一种用于多处理器的电脑内存体设计,内存访问时间取决于处理器的内存位置。 在NUMA下,处理器访问它自己的本地存储器的速度比非本地存储器(存储器的地方到另一个处理器之间共享的处理器或存储器)快一些。
NIC
NIC(Network Interface Controller):
NIC 是计算机系统中的网络接口控制器,通常是一块独立的硬件设备或集成在主板或网络适配器中。NIC 负责处理计算机与网络之间的通信,实现数据包的发送和接收。在分布式系统和集群中,NIC 的性能对于实现高效的通信和数据传输至关重要。在深度学习的多 GPU 训练中,NIC 用于实现节点间的通信,确保模型参数的同步和训练数据的分发。
NVMe
NVMe(Non-Volatile Memory Express):
NVMe 是一种用于连接和通信非易失性存储设备(如固态硬盘 SSD)的协议和接口标准。相比于传统的存储协议(如SATA),NVMe 提供更高的性能和更低的延迟。在深度学习中,NVMe 技术可以加速大规模数据集的加载,以及模型参数的读写,从而提高训练效率。NVMe SSDs通常用于存储深度学习模型和训练数据。
GPU相关
P2P
Peer to Peer:
P2P,即点对点通信,是NVIDIA GPU的功能之一,使CUDA程序能够在不经过连接到CPU的共享系统内存的情况下,访问并传输数据从一个GPU的内存到另一个GPU。这一功能在NVIDIA GPU上已存在8到9年。P2P与"Unified Virtual Addressing" (UVA)一起,是CUDA进行GPU计算的重要改进。它们支持在多GPU和多节点系统环境中高效运行,并简化了高度并行代码的编程。
在拥有2-4个GPU的工作站上,P2P和UVA可以为一些程序提供适度的性能提升。而对于大型GPU加速的超级计算机,它们允许一个节点(系统)上的GPU通过高速网络如InfiniBand,使用RDMA(Remote Direct Memory Access)访问另一个节点上的GPU的内存。这对于大规模并行超级计算非常重要,也推动着全球最快计算机系统的性能。在工作站上,这一功能显著但不如在超级计算机上重要,因为通过CPU内存池的标准内存传输在效率上是可以接受的。需要注意的是,这正是为什么单CPU系统通常更适合GPU加速工作站的原因,因为双CPU系统可能因为从一个CPU内存空间到连接到另一个CPU的PCIe通道上的GPU的内存传输而导致性能下降。
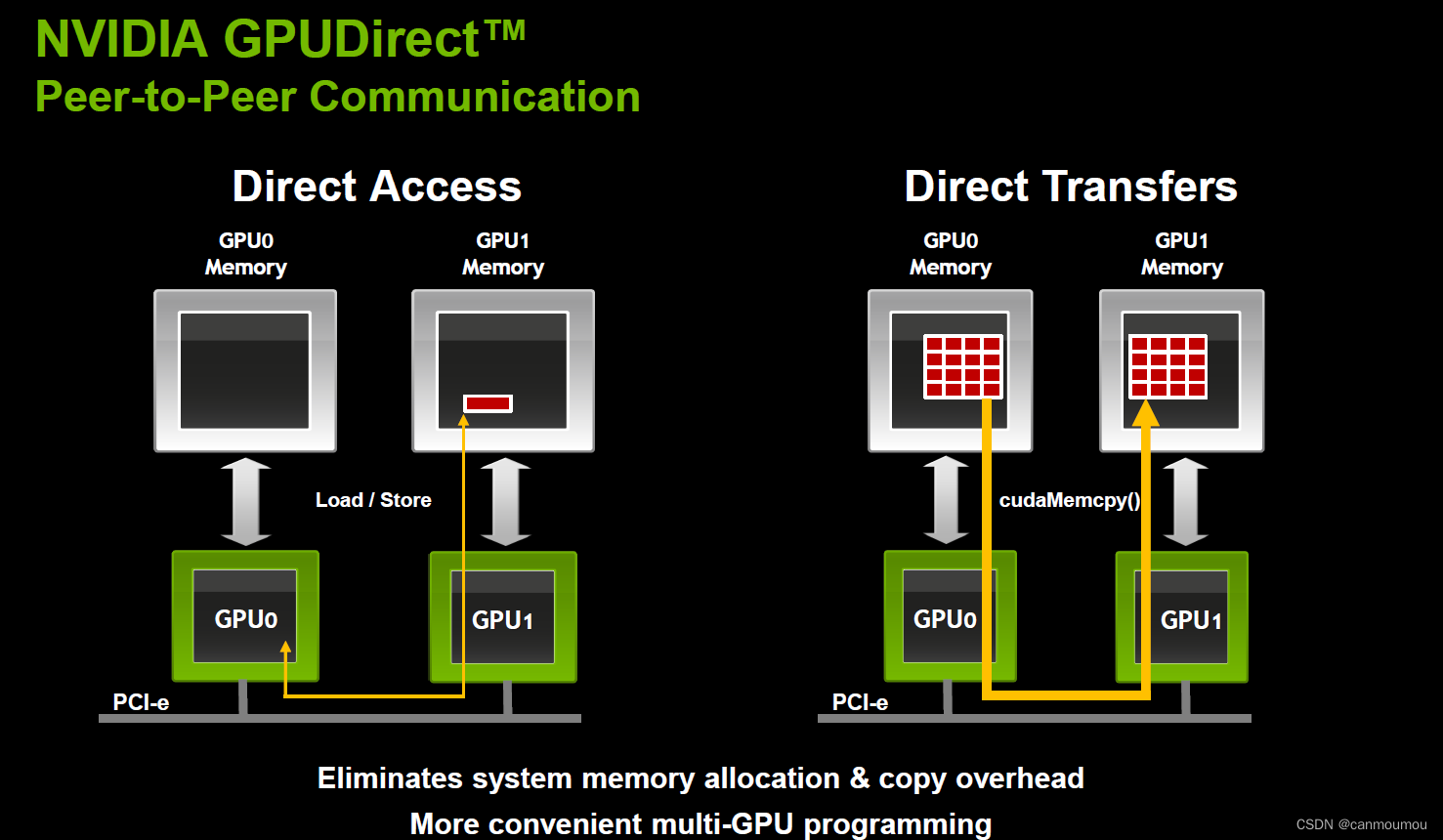
可以用NCCL中的standalone目录下/p2pBandwidthLatencyTest来测试
P2P可以理解为一种能力。相信可以参考:P2P peer-to-peer on NVIDIA RTX 2080Ti vs GTX 1080Ti GPUs
通常情况下,同一块PCIE Swithc上的几张GPU之间P2P通信贷款相同,如果跨越PCIE SWITCH则会有一定损失。
UVA
UVA(Unified Virtual Addressing)也是启用点对点(P2P)数据直接通过PCIe总线或在支持的配置中通过NVLink传输的必要前提条件,他说可以绕过主机内存的。
Unified Virtual Addressing(UVA)是一种计算模型,用于处理GPU计算中的内存管理。UVA的核心思想是将系统中的所有内存(包括CPU和GPU内存)统一视为一个虚拟地址空间,而不再需要显式地在CPU和GPU之间进行内存拷贝。
在传统的GPU编程模型中,开发者必须显式地分配和管理GPU内存,并且在CPU和GPU之间进行数据传输时需要进行内存拷贝。这导致了繁琐的内存管理工作和额外的数据传输开销。
而有了UVA,开发者可以使用统一的虚拟地址空间,无论是在CPU还是GPU上执行的代码都能够透明地访问整个系统的内存,而无需手动管理内存分配和传输。这种模型大大简化了程序员的工作,提高了代码的可移植性和可维护性。
在上下文中提到的P2P传输,UVA是一个必要的前提条件。通过UVA,GPU可以直接访问其他GPU的内存,而无需将数据经过主机内存。这种直接的点对点传输方式在一些应用中可以显著提高性能,特别是在多GPU系统中。总体而言,UVA对于简化GPU计算中的内存管理,提高程序性能和可编程性方面都起到了关键的作用。
UM
Unified Memory
Unified Memory(UM)是一种内存管理技术,用于简化GPU编程中的内存管理任务。UM允许开发者使用一个统一的虚拟地址空间来访问系统中的所有内存,包括CPU和GPU的内存,而无需手动进行显式的内存分配和数据传输。
UM的核心概念是将CPU和GPU的内存统一到一个地址空间中,使得程序员能够透明地访问整个系统的内存,而不必担心不同内存域之间的复杂管理。具体来说,UM允许在CPU和GPU之间共享数据,而无需显式地在它们之间进行内存拷贝。这种共享使得在CPU和GPU之间传递数据变得更为简单和高效。
在CUDA编程模型中,NVIDIA引入了Unified Memory,使得程序员可以使用cudaMallocManaged等API分配统一内存,而无需手动管理CPU和GPU内存的分配和释放。UM在GPU加速计算中特别有用,因为它减少了开发者需要关注的细节,提高了代码的可移植性和可维护性。
需要注意的是,UM与Unified Virtual Addressing(UVA)密切相关。UVA是一个更广泛的概念,而UM是实现UVA的一种具体方式,特指在CUDA中通过统一内存管理的机制。
Mapped/Zero Copy Memory
Mapped/Zero Copy Memory 是一种内存管理技术,通常用于GPU编程,特别是在CUDA中常见。这种技术的目标是允许 CPU 和 GPU 共享相同的内存地址空间,从而避免在它们之间进行显式的内存复制。
Mapped Memory:
Mapped Memory 允许 GPU 直接访问 CPU 分配的内存。在这种情况下,CPU 分配了一块内存,然后将其映射到 GPU 地址空间中。这使得 CPU 和 GPU 可以在相同的内存地址上进行读写操作,而无需复制数据。通过这种映射,对内存的修改可以在 CPU 和 GPU 之间保持同步。
Zero Copy Memory:
Zero Copy Memory 是一种技术,它使 CPU 和 GPU 共享相同的内存地址空间,而无需实际复制数据。在 Zero Copy Memory 中,CPU 分配的内存可以直接由 GPU 访问,而不需要将数据从 CPU 复制到 GPU。这减少了不必要的数据传输,提高了程序的效率。
这两种技术的核心思想是通过共享内存地址空间,使得 CPU 和 GPU 能够直接访问相同的数据,而无需复制。这在一些情况下可以提高程序的性能,尤其是在需要频繁交换数据的应用中。但需要注意,使用这些技术时需要谨慎管理同步,以确保在 CPU 和 GPU 之间正确地协调对内存的访问。
Stream(流)
- 在GPU编程中,“stream” 通常是指一系列的GPU命令序列,它们按照提交的顺序在GPU上执行。每个流都是独立的,可以在同一时间内执行多个流,从而实现并发性。这样的并发性可以提高GPU的利用率,尤其在处理大规模并行任务时。
- 在CUDA(Compute Unified Device Architecture)编程模型中,流由
cudaStream_t类型表示。通过将GPU任务提交到不同的流上,可以在GPU上并发执行这些任务。例如,一个应用程序可以使用一个流来处理计算任务,另一个流来处理数据传输任务,从而提高整体性能。
CE(上下文引擎)
- 上下文引擎(Context Engine)是GPU驱动程序中的组件之一,它负责管理GPU上下文的创建、销毁和切换。上下文是GPU资源的容器,包括内存、寄存器状态、命令队列等。上下文引擎的主要任务是协调和调度不同上下文之间的切换,以便在GPU上实现多任务并发执行。
- 在NVIDIA GPU的驱动程序中,上下文引擎的概念可能与GPU上的任务调度和上下文切换有关。上下文引擎的性能和效率对于GPU的整体性能至关重要,特别是在多任务环境下。
Pined memory
首先,让我们来理解什么是pinned memory。在一般的内存管理中,操作系统负责管理内存,将数据从主存(RAM)复制到GPU内存时,通常会经过两个阶段:首先是将数据从主存拷贝到操作系统内核缓冲区,然后再从内核缓冲区复制到GPU内存。这个过程可能涉及到多次数据拷贝,导致性能损失。
而pinned memory的主要优势在于,它是直接锁定在主存中的内存,这意味着它不会被操作系统交换到磁盘上,而是一直保持在物理内存中。因此,当你需要将数据从主存传输到GPU时,可以直接通过DMA(Direct Memory Access)引擎实现,避免了中间阶段的复制,提高了数据传输的效率。
现在,让我们看看为什么在RDMA技术中,尤其是在NCCL这样的通信库中,使用pinned memory更为重要。RDMA允许两台计算机之间直接进行内存的数据传输,而不需要CPU的干预。这就要求涉及的内存必须是可直接访问的,而pinned memory正好符合这个要求。在RDMA中,通过pinned memory,GPU可以将数据直接发送到网络适配器,而无需将数据从主存复制到GPU内存。
总结一下,pinned memory在GPU设计中的作用是为了优化数据传输的性能,特别是在涉及RDMA技术的情况下,如在NCCL这样的通信库中。它通过直接锁定在主存中的内存,避免了中间阶段的复制,提高了数据传输的效率,使得GPU能够更高效地与其他设备进行通信。
对于CUDA架构而言,主机端内存被分为两种,一种是可分页内存(pageable memory)和页锁定内存(page-lock / pinned memory)。
可分页内存
可分页内存是由操作系统API malloc()在主机上分配的,页锁定内存是由CUDA函数cudaHostAlloc()在主机内存上分配的。页锁定内存的重要属性是主机的操作系统将不会对这块内存进行分页和交换操作,确保该内存始终驻留在物理内存中。
页锁定内存
GPU知道页锁定内存的物理地址,可以通过“直接内存访问(Direct Memory Access,DMA)”技术直接在主机和GPU之间复制数据,速率更快。由于每个页锁定内存都需要分配物理内存,并且这些内存不能交换到磁盘上,所以页锁定内存比使用标准malloc()分配的可分页内存更消耗内存空间。
总的来说,叶锁定内存和可分页内存的区别在于数据传输的路径和方式。叶锁定内存允许直接的、无CPU干预的数据传输,而可分页内存则需要经过CPU的拷贝过程。
GPipe
Gpipe(Gradient Pipeline):
Gpipe 是一种用于加速深度学习训练的技术,特别是在处理大型模型时。Gpipe 将深度学习模型分为多个子模型(管道阶段),这些子模型可以并行处理不同的输入。通过将模型的前向和反向传播划分为多个阶段,Gpipe 允许在 GPU 上并行执行这些阶段,从而减少训练时间。这对于大型模型和复杂任务的训练尤为有益。 Gpipe 的设计有助于提高 GPU 利用率,减小 GPU 内存需求,以及加速训练过程。
ZeRO(Zero Redundancy Optimizer)
ZeRO 是一个优化技术,旨在减少深度学习模型的内存占用和通信开销。在分布式训练中,模型参数需要在不同的 GPU 设备之间同步。ZeRO 提供了一种零冗余的方式,将模型参数划分为多个部分,使得每个 GPU 只保留模型的一部分,从而减少了内存占用。此外,ZeRO 还通过使用零拷贝技术和优化的通信算法来减少通信开销,提高训练性能。
ZeRO-Offload:
ZeRO-Offload 是 NVIDIA 的一项技术,旨在通过将模型参数的状态分割和分布到多个 GPU 设备上,减少深度学习训练中的内存占用。这种技术通过将模型参数分割成多个分片,每个 GPU 只保留部分参数,从而降低了每个 GPU 上的内存需求。ZeRO-Offload 还利用 GPU 之间的高性能通信来实现模型参数的同步,确保训练的一致性。这有助于在大型模型和大批量训练中降低内存占用,使得更大的模型可以在有限的 GPU 内存中训练。
、
ZeRO-Infinity:
ZeRO-Infinity 是 ZeRO 的演进版本,旨在进一步优化深度学习模型的内存占用和分布式训练的性能。它采用零冗余的设计理念,通过将模型参数分为更小的微批次(micro-batches)来减小内存需求。此外,ZeRO-Infinity 还引入了一种动态的模型分片策略,允许在训练过程中根据需要动态地调整模型参数的分布。这种动态性使得 ZeRO-Infinity 更加灵活,能够适应不同模型和训练负载的要求。通过这些优化,ZeRO-Infinity 旨在提供更高效、更灵活的分布式深度学习训练。
PCIe(Peripheral Component Interconnect Express)
PCIe 是一种高速串行计算机扩展总线标准,用于在计算机系统内部连接各种硬件设备,包括GPU、存储设备和网络适配器。在深度学习中,特别是在多 GPU 设置中,PCIe 用于连接不同 GPU 设备,以便它们可以进行相互通信和数据传输。PCIe 性能的优化对于减少数据传输的延迟和提高分布式训练性能至关重要。
CUDA相关
线程束(Warp):
是GPU执行线程的基本单位,通常包含32个线程。这些线程会同时执行相同的指令。
段对齐(Segment Alignment):
在CUDA中,指的是线程访问全局内存时的地址对齐方式。不同版本的CUDA架构对于内存访问的要求和优化条件有所不同。
银行冲突(Bank Conflict)
银行冲突(Bank Conflict)是指在GPU的共享内存(Shared Memory)中,多个线程尝试同时访问同一个存储器银行(Memory Bank)造成的冲突现象。共享内存被划分为多个存储器银行,每个银行通常只能同时处理一个线程的读或写操作。如果多个线程同时访问了同一个存储器银行,会导致额外的等待和串行化,从而降低程序的并行性和性能。因此,避免银行冲突是共享内存优化中的重要目标之一,可以通过合理的内存分配和访问模式来减少冲突,提升程序的效率。
通信相关
RDMA
Remote Direct Memory Access (RDMA) 是一种超高速的网络内存访问技术,它允许程序以极快速度访问远程计算节点的内存。速度快的原因如下图所示,一次网络访问,不需要经过操作系统的内核(Sockets、TCP/IP等),这些操作系统内核操作都会耗费CPU时间。RDMA直接越过了这些操作系统内核开销,直接访问到网卡(Network Interface Card,NIC)。一些地方又称之为HCA(Host Channel Adapter)。
RDMA本身指的是一种技术,具体协议层面,包含Infiniband(IB),RDMA over Converged Ethernet(RoCE)和internet Wide Area RDMA Protocol(iWARP)。三种协议都符合RDMA标准,使用相同的上层接口,在不同层次上有一些差别。上述几种协议都需要专门的硬件(网卡)支持。
GPU Direct RDMA (GDR)
GDR 是一种技术,允许 GPU 直接进行 RDMA(Remote Direct Memory Access)操作,而无需通过主机内存进行中转。这使得 GPU 之间的数据传输更为高效,因为它可以绕过主机内存,直接在 GPU 之间进行数据交换。
在 NCCL 中,GDR 可能用于优化 GPU 设备之间的通信,特别是在高性能计算环境中,例如在使用 NVIDIA GPU 的集群中进行并行计算时。
GDR 的使用通常要求系统硬件和驱动的支持,以确保 GPU 之间的直接数据传输是高效的。
CollNet
CollNet其实不是一种算法,而是一种自定义的网络通信方式,需要加载额外的插件来使用。说下基于SHArP协议的,具体加载方法这个链接里有写。
SHArP+NCCLdocs.nvidia.com/networking/display/SHARPv261/Using+NVIDIA+SHARP+with+NVIDIA+NCCL
目前NVIDIA官方的CollNet实现应该是只有基于SHArP的这一种,需要搭配Infiniband以及Infiniband交换机一起食用(yummy),好一个NVIDIA全家桶。怕大家没接触过SHArP,先给大家扫个盲(因为我就没接触过,研究HPC的同学倒是熟得很)。
1. 什么是SHArP
这个是介绍SHArP的论文:SHArP 论文,其实没必要细看。简单来说,SHArP是一个软硬结合的通信协议,实现在了NVIDIA Quantum HDR Switch的ASIC里。它可以把从各个node收到的数据进行求和,并发送回去。再说的通俗一点,通过使用SHArP,我们把求和(聚合/Reduce,随便怎么叫)的操作交由交换机完成了。这种做法,业界叫做In-network Computing(在网计算)。用术语展开来讲,就是将计算卸载到网络中进行。
更多相关的知识可以看这个英伟达的汇报
NVIDIA GTC SHArPwww.nvidia.com/en-us/on-demand/session/gtcspring21-s32067/
2. 为什么要SHArP?
通过把计算卸载到网络里,每个node(图片里为host)只需要收发一倍的数据量就可以完成AllReduce了。相比Tree和Ring算法,收发的数据量直接就减半了。这使得SHArP的潜力比Tree和Ring高了一倍。而且SHArP因为把计算卸载给交换机去做了,因此小数据的latency也会减少很多。
Topo
两个GPU和网卡之间可能有多个channel,什么是channel,什么是path呢?
Channel(通道)
在 NCCL 中,通道是指一组用于通信的 GPU 设备。通道可以包括一个或多个 GPU。在 NCCL 的术语中,通道是用于执行通信操作的基本单元。一个任务(例如点对点通信或规约操作)可以涉及到一个或多个通道。
Path(路径)
路径是指在 GPU 通道之间进行通信的物理或逻辑路径。NCCL 使用路径来表示数据在通道之间传输的方式。路径可以涉及到 GPU 设备之间的连接方式,例如 PCIe 或 NVLink,以及其他硬件拓扑结构。
Graph(图)
在 NCCL 中,图是指一个或多个通道的集合,它们可以一起执行并发的通信操作。图的存在使得多个通信操作能够以并行的方式执行,提高整体性能。一个图可以包含一个或多个通道。
Topology(拓扑)
拓扑指的是 GPU 设备之间的物理连接和关系。NCCL 使用拓扑信息来优化通信操作,以适应底层硬件的特性。拓扑信息包括 GPU 设备之间的连接方式、距离等,以便 NCCL 可以更智能地选择最优路径和通道。
简而言之:
- 通道(Channel) 是执行通信操作的基本单元。 \
- 路径(Path) 表示 GPU 设备之间通信的物理或逻辑路径。
- 图(Graph)是一个或多个通道的集合,允许并发执行多个通信操作。
- 拓扑(Topology) 描述 GPU 设备之间的物理连接和关系,用于优化通信操作。



















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











