




文章目录
一、GAN的核心原理与数学基础
1.1 生成模型的革命性突破
生成对抗网络(Generative Adversarial Networks)由Ian Goodfellow等人于2014年提出,通过对抗训练机制开创了生成模型的新范式。其核心思想是构建两个神经网络—— 生成器(Generator) 和 判别器(Discriminator) ——在博弈中共同进化。具体公式如下:

其中:
- G:生成器,将随机噪声z映射到数据空间
- D:判别器,评估输入来自真实数据还是生成样本
- p_data:真实数据分布
- p_z:噪声先验分布(通常为标准正态分布)
1.2 对抗训练的数学本质
GAN的优化目标可分解为两个部分:
- 判别器目标:
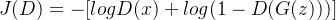
最大化对真实样本和生成样本的区分能力。
- 生成器目标:
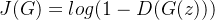
最小化判别器的判断准确率。
从概率散度角度看,GAN最小化了真实分布与生成分布之间的Jensen-Shannon散度:
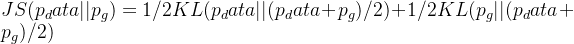
1.3 训练动态与纳什均衡
GAN的训练过程可视为寻找纳什均衡的双人博弈:
-
判别器梯度:

-
生成器梯度:
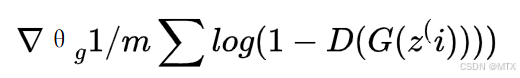
理想情况下,当p_g = p_data时达到全局最优,此时D(x)=0.5对所有x成立。
二、GAN的架构演进与技术变体
2.1 基础GAN的局限性
原始GAN面临的主要挑战:
- 模式崩溃(Mode Collapse):生成器只产生有限多样性的样本
- 训练不稳定:梯度消失或振荡导致难以收敛
- 评估困难:缺乏客观的质量度量标准
2.2 经典改进架构
(1)DCGAN(深度卷积GAN)
关键创新:
- 使用转置卷积进行上采样
- 去除全连接层
- 引入批量归一化
- LeakyReLU激活函数
(2)WGAN(Wasserstein GAN)
通过Wasserstein距离改进训练稳定性:
【主要贡献】:
- 彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度;
- 基本解决了collapse mode的问题,确保了生成样本的多样性;
- 训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高。
以上一切好处在于:不需要精心设计的网络架构,最简单的多层全连接网络就可以做到。
【主要改进】:
- 判别器最后一层去掉sigmoid;
- 生成器和判别器的loss不取log;
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c;
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行。
关于Wasserstein GAN的具体介绍,参考博客:论文阅读:Wasserstein GAN
(3)Progressive GAN
渐进式训练策略:
- 从低分辨率(4×4)开始训练
- 逐步添加更高分辨率层
- 平滑过渡阶段(fade-in)
2.3 前沿变体对比
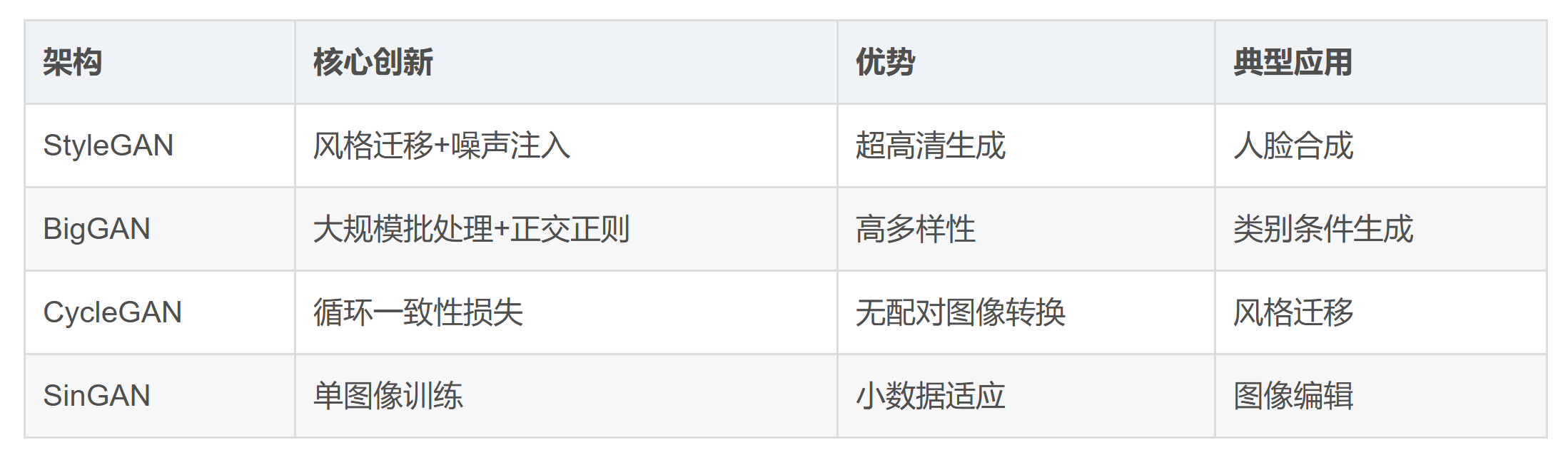
三、GAN的训练技巧与优化策略
3.1 训练稳定性提升
(1)双时间尺度更新规则(TTUR):
- 判别器学习率 > 生成器学习率(典型4:1)
- 使用Adam优化器(β1=0.5, β2=0.999)
(2)谱归一化(Spectral Normalization):
# 对判别器每层权重进行L2归一化
def spectral_norm(w):
w_shape = w.shape
w = tf.reshape(w, [-1, w_shape[-1]])
u = tf.random.normal([1, w_shape[-1]])
for _ in range(3): # 幂迭代次数
v = tf.matmul(u, w, transpose_b=True)
v /= tf.norm(v)
u = tf.matmul(v, w)
u /= tf.norm(u)
sigma = tf.matmul(tf.matmul(v, w), u, transpose_b=True)
return w / sigma
3.2 模式崩溃解决方案
(1)小批量判别(Minibatch Discrimination):
- 计算样本间相似度特征
- 作为额外信息输入判别器
(2)经验回放(Experience Replay):
- 保存历史生成样本
- 以一定概率与当前样本混合训练
四、GAN的应用场景与技术实现
4.1 图像生成与编辑
(1)高分辨率人脸合成(StyleGAN2示例):
# 风格混合示例
latent1 = get_latent() # 源特征1
latent2 = get_latent() # 源特征2
mixed = []
for i in range(18): # 18个风格层
ratio = 1.0 if i < 9 else 0.0 # 混合策略
mixed.append(latent1[i]*ratio + latent2[i]*(1-ratio))
img = generator(mixed)
(2)图像修复(Inpainting):
- 构建掩码区域:mask = np.zeros_like(img)
- 上下文编码:context = encoder(img*(1-mask))
- 对抗修复:output = generator(context, mask)
4.2 跨模态生成
(1)文本到图像生成(StackGAN架构):
- Stage-I: 生成低分辨率草图(64×64)
- Stage-II: 细化到高分辨率(256×256)
- 附加条件:文本嵌入向量 + 类别标签
(2)音乐生成(MuseGAN多轨生成):
- 钢琴卷表示法(Piano Roll)
- 多判别器架构(音高、节奏、和弦判别)
4.3 医学与科学应用
(1)医学图像增强:
-
低剂量CT到常规CT的转换
-
组织病理切片染色标准化
(2)分子设计:
# 分子生成模型
z = sample_latent()
adj_matrix, features = generator(z)
mol = graph_to_molecule(adj_matrix, features)
if check_valid(mol):
properties = predictor(mol)
五、GAN的Python实现示例
import random
import math
# ==================== 基础数学运算 ====================
class Matrix:
"""简单的矩阵类,支持基本运算"""
def __init__(self, rows, cols, data=None):
self.rows = rows
self.cols = cols
if data is None:
self.data = [[0.0 for _ in range(cols)] for _ in range(rows)]
else:
self.data = data
def __getitem__(self, idx):
return self.data[idx]
def __setitem__(self, idx, value):
self.data[idx] = value
def shape(self):
return (self.rows, self.cols)
def transpose(self):
"""矩阵转置"""
result = Matrix(self.cols, self.rows)
for i in range(self.rows):
for j in range(self.cols):
result[j][i] = self[i][j]
return result
def copy(self):
"""创建矩阵副本"""
new_data = [row[:] for row in self.data]
return Matrix(self.rows, self.cols, new_data)
def matmul(A, B):
"""矩阵乘法"""
assert A.cols == B.rows, "矩阵维度不匹配"
result = Matrix(A.rows, B.cols)
for i in range(A.rows):
for j in range(B.cols):
sum_val = 0.0
for k in range(A.cols):
sum_val += A[i][k] * B[k][j]
result[i][j] = sum_val
return result
def add_matrices(A, B):
"""矩阵加法"""
assert A.shape() == B.shape(), "矩阵维度不匹配"
result = Matrix(A.rows, A.cols)
for i in range(A.rows):
for j in range(A.cols):
result[i][j] = A[i][j] + B[i][j]
return result
def multiply_scalar(matrix, scalar):
"""矩阵数乘"""
result = Matrix(matrix.rows, matrix.cols)
for i in range(matrix.rows):
for j in range(matrix.cols):
result[i][j] = matrix[i][j] * scalar
return result
# ==================== 激活函数 ====================
def relu(x):
"""ReLU激活函数"""
if isinstance(x, (list, tuple)):
return [max(0.0, val) for val in x]
else:
return max(0.0, x)
def relu_derivative(x):
"""ReLU导数"""
if isinstance(x, (list, tuple)):
return [1.0 if val > 0 else 0.0 for val in x]
else:
return 1.0 if x > 0 else 0.0
def sigmoid(x):
"""Sigmoid激活函数"""
try:
return 1.0 / (1.0 + math.exp(-x))
except OverflowError:
return 0.0 if x < 0 else 1.0
def sigmoid_derivative(x):
"""Sigmoid导数"""
s = sigmoid(x)
return s * (1.0 - s)
# ==================== 神经网络层 ====================
class DenseLayer:
"""全连接层"""
def __init__(self, input_size, output_size):
self.input_size = input_size
self.output_size = output_size
# Xavier初始化
scale = math.sqrt(2.0 / (input_size + output_size))
self.weights = Matrix(output_size, input_size)
self.biases = Matrix(output_size, 1)
for i in range(output_size):
for j in range(input_size):
self.weights[i][j] = random.uniform(-scale, scale)
self.biases[i][0] = 0.0
self.last_input = None
self.last_output = None
def forward(self, input_matrix):
"""前向传播"""
self.last_input = input_matrix
output = matmul(self.weights, input_matrix)
# 加上偏置
for i in range(output.rows):
output[i][0] += self.biases[i][0]
self.last_output = output
return output
def backward(self, grad_output, learning_rate):
"""反向传播"""
# 计算权重梯度
grad_weights = matmul(grad_output, self.last_input.transpose())
# 计算偏置梯度
grad_biases = grad_output
# 计算输入梯度
grad_input = matmul(self.weights.transpose(), grad_output)
# 更新参数
for i in range(self.weights.rows):
for j in range(self.weights.cols):
self.weights[i][j] -= learning_rate * grad_weights[i][j]
self.biases[i][0] -= learning_rate * grad_biases[i][0]
return grad_input
# ==================== 激活层 ====================
class ActivationLayer:
"""激活函数层"""
def __init__(self, activation, activation_derivative):
self.activation = activation
self.activation_derivative = activation_derivative
self.last_input = None
def forward(self, input_matrix):
"""前向传播"""
self.last_input = input_matrix
output = Matrix(input_matrix.rows, input_matrix.cols)
for i in range(input_matrix.rows):
for j in range(input_matrix.cols):
output[i][j] = self.activation(input_matrix[i][j])
return output
def backward(self, grad_output, learning_rate):
"""反向传播"""
grad_input = Matrix(grad_output.rows, grad_output.cols)
for i in range(grad_output.rows):
for j in range(grad_output.cols):
grad_input[i][j] = grad_output[i][j] * self.activation_derivative(self.last_input[i][j])
return grad_input
# ==================== 神经网络 ====================
class NeuralNetwork:
"""神经网络"""
def __init__(self):
self.layers = []
def add(self, layer):
"""添加层"""
self.layers.append(layer)
def forward(self, input_matrix):
"""前向传播"""
output = input_matrix
for layer in self.layers:
output = layer.forward(output)
return output
def backward(self, loss_grad, learning_rate):
"""反向传播"""
grad = loss_grad
for layer in reversed(self.layers):
grad = layer.backward(grad, learning_rate)
# ==================== 损失函数 ====================
def binary_cross_entropy_loss(y_pred, y_true):
"""二元交叉熵损失"""
epsilon = 1e-15 # 避免log(0)
loss = 0.0
for i in range(y_pred.rows):
for j in range(y_pred.cols):
pred = max(epsilon, min(1 - epsilon, y_pred[i][j]))
if y_true[i][j] == 1:
loss -= math.log(pred)
else:
loss -= math.log(1 - pred)
return loss
def binary_cross_entropy_loss_grad(y_pred, y_true):
"""二元交叉熵损失梯度"""
epsilon = 1e-15
grad = Matrix(y_pred.rows, y_pred.cols)
for i in range(y_pred.rows):
for j in range(y_pred.cols):
pred = max(epsilon, min(1 - epsilon, y_pred[i][j]))
grad[i][j] = (pred - y_true[i][j]) / (pred * (1 - pred))
return grad
# ==================== GAN实现 ====================
class Generator:
"""生成器"""
def __init__(self, noise_dim, output_dim):
self.noise_dim = noise_dim
self.output_dim = output_dim
self.network = NeuralNetwork()
# 网络结构: noise -> 128 -> 256 -> output
self.network.add(DenseLayer(noise_dim, 128))
self.network.add(ActivationLayer(relu, relu_derivative))
self.network.add(DenseLayer(128, 256))
self.network.add(ActivationLayer(relu, relu_derivative))
self.network.add(DenseLayer(256, output_dim))
self.network.add(ActivationLayer(sigmoid, sigmoid_derivative))
def forward(self, noise):
"""生成假数据"""
return self.network.forward(noise)
def backward(self, grad_output, learning_rate):
"""生成器反向传播"""
self.network.backward(grad_output, learning_rate)
class Discriminator:
"""判别器"""
def __init__(self, input_dim):
self.input_dim = input_dim
self.network = NeuralNetwork()
# 网络结构: input -> 256 -> 128 -> 1
self.network.add(DenseLayer(input_dim, 256))
self.network.add(ActivationLayer(relu, relu_derivative))
self.network.add(DenseLayer(256, 128))
self.network.add(ActivationLayer(relu, relu_derivative))
self.network.add(DenseLayer(128, 1))
self.network.add(ActivationLayer(sigmoid, sigmoid_derivative))
def forward(self, input_data):
"""判别数据真伪"""
return self.network.forward(input_data)
def backward(self, grad_output, learning_rate):
"""判别器反向传播"""
self.network.backward(grad_output, learning_rate)
class GAN:
"""生成对抗网络"""
def __init__(self, noise_dim, data_dim, learning_rate=0.001):
self.noise_dim = noise_dim
self.data_dim = data_dim
self.learning_rate = learning_rate
self.generator = Generator(noise_dim, data_dim)
self.discriminator = Discriminator(data_dim)
def generate_noise(self, batch_size):
"""生成随机噪声"""
noise = Matrix(self.noise_dim, batch_size)
for i in range(self.noise_dim):
for j in range(batch_size):
noise[i][j] = random.uniform(-1, 1)
return noise
def train_step(self, real_data):
"""单步训练"""
batch_size = real_data.cols
# === 训练判别器 ===
# 真实数据
real_labels = Matrix(1, batch_size)
for j in range(batch_size):
real_labels[0][j] = 1.0
# 假数据
noise = self.generate_noise(batch_size)
fake_data = self.generator.forward(noise)
fake_labels = Matrix(1, batch_size)
for j in range(batch_size):
fake_labels[0][j] = 0.0
# 判别器前向传播
real_output = self.discriminator.forward(real_data)
fake_output = self.discriminator.forward(fake_data)
# 判别器损失
real_loss = binary_cross_entropy_loss(real_output, real_labels)
fake_loss = binary_cross_entropy_loss(fake_output, fake_labels)
d_loss = real_loss + fake_loss
# 判别器反向传播
real_grad = binary_cross_entropy_loss_grad(real_output, real_labels)
fake_grad = binary_cross_entropy_loss_grad(fake_output, fake_labels)
self.discriminator.backward(real_grad, self.learning_rate)
self.discriminator.backward(fake_grad, self.learning_rate)
# === 训练生成器 ===
# 生成器希望判别器将假数据判断为真实
noise = self.generate_noise(batch_size)
fake_data = self.generator.forward(noise)
fake_output = self.discriminator.forward(fake_data)
# 生成器损失(希望判别器输出接近1)
g_labels = Matrix(1, batch_size)
for j in range(batch_size):
g_labels[0][j] = 1.0
g_loss = binary_cross_entropy_loss(fake_output, g_labels)
# 生成器反向传播(通过判别器)
g_grad_output = binary_cross_entropy_loss_grad(fake_output, g_labels)
# 反向传播通过判别器
grad_through_discriminator = self.discriminator.network.backward(g_grad_output, 0) # 不更新判别器
# 反向传播通过生成器
self.generator.backward(grad_through_discriminator, self.learning_rate)
return d_loss, g_loss
def generate(self, num_samples):
"""生成样本"""
noise = self.generate_noise(num_samples)
return self.generator.forward(noise)
# ==================== 使用示例 ====================
if __name__ == "__main__":
# 创建GAN实例
gan = GAN(noise_dim=100, data_dim=784, learning_rate=0.001)
# 示例:创建随机真实数据(实际使用时替换为真实数据)
real_data = Matrix(784, 32)
for i in range(784):
for j in range(32):
real_data[i][j] = random.uniform(0, 1)
# 训练一步
d_loss, g_loss = gan.train_step(real_data)
print(f"判别器损失: {d_loss:.4f}, 生成器损失: {g_loss:.4f}")
# 生成样本
generated_samples = gan.generate(5)
print(f"生成了 {generated_samples.cols} 个样本")
六、GAN的未来发展路径
尽管GAN在生成质量上不断突破,仍面临三大核心挑战:
-
训练稳定性:新型优化器(如Consensus Optimization)和均衡策略
-
评估体系:建立与人类感知更一致的量化标准
-
伦理边界:深度伪造(Deepfake)检测与内容溯源技术
前沿方向包括:
- 物理引擎集成:实现符合物理规律的生成(如流体模拟)
- 神经渲染:将3D信息融入生成过程
- 能效优化:绿色AI框架下的轻量化生成

















&spm=1001.2101.3001.5002&articleId=153393181&d=1&t=3&u=7542414db8d440b5ab881fb47947acec)
 2373
2373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









