






1、ICE-G: Image Conditional Editing of 3D Gaussian Splats
中文标题:ICE-G:3D 高斯斑点的图像条件编辑

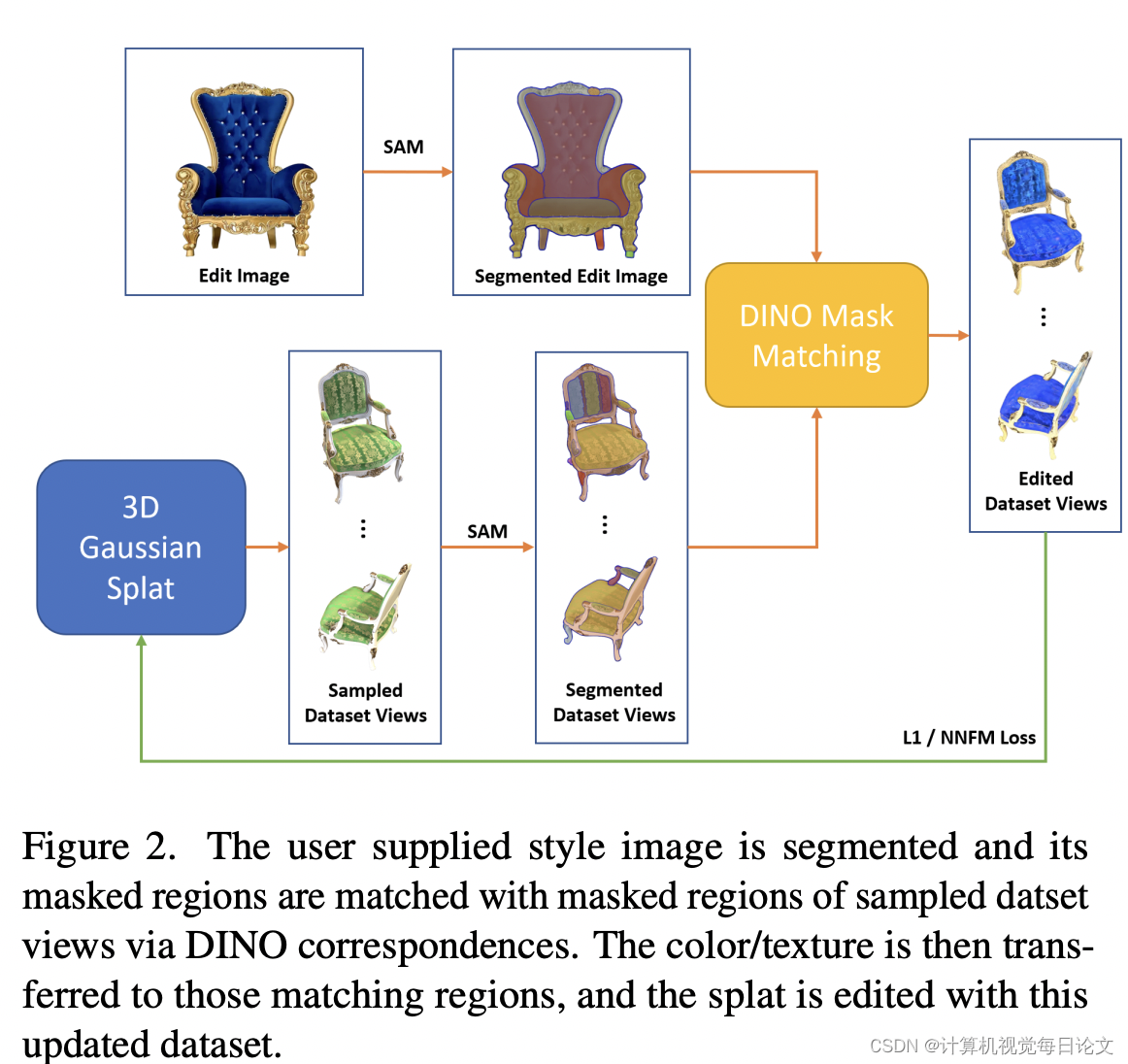
简介:近年来,出现了许多技术来创建高质量的3D资产和场景。然而,当涉及到这些3D对象的编辑时,现有方法要么速度慢、要么牺牲质量,要么无法提供足够的自定义能力。
为解决这一问题,我们提出了一种新颖的方法,可以快速编辑单个参考视图的3D模型。
我们的技术分为以下几个步骤:
1. 对编辑图像进行分割。
2. 利用DINO特征在选定的分割视图之间匹配语义对应区域。
3. 自动将编辑图像中特定区域的颜色或纹理以语义合理的方式应用到其他视图。
这些编辑后的视图可以作为更新的数据集,以进一步训练和重新设计3D场景,从而得到最终的编辑后3D模型。
我们的框架支持多种编辑任务,包括手动本地编辑、基于对应关系的风格转移,以及从多个示例图像中组合不同风格。
我们使用高斯斑点作为主要的3D表示形式,因为它们速度快且易于本地编辑。不过,我们的技术也适用于其他方法,如NeRFs。
通过多个实验案例,我们展示了该方法能够产生更高质量的结果,同时提供了精细的编辑控制能力。
项目主页:ice-gaussian.github.io
2、Beyond LLaVA-HD: Diving into High-Resolution Large Multimodal Models
中文标题:超越 LLaVA-HD:深入研究高分辨率大型多模态模型
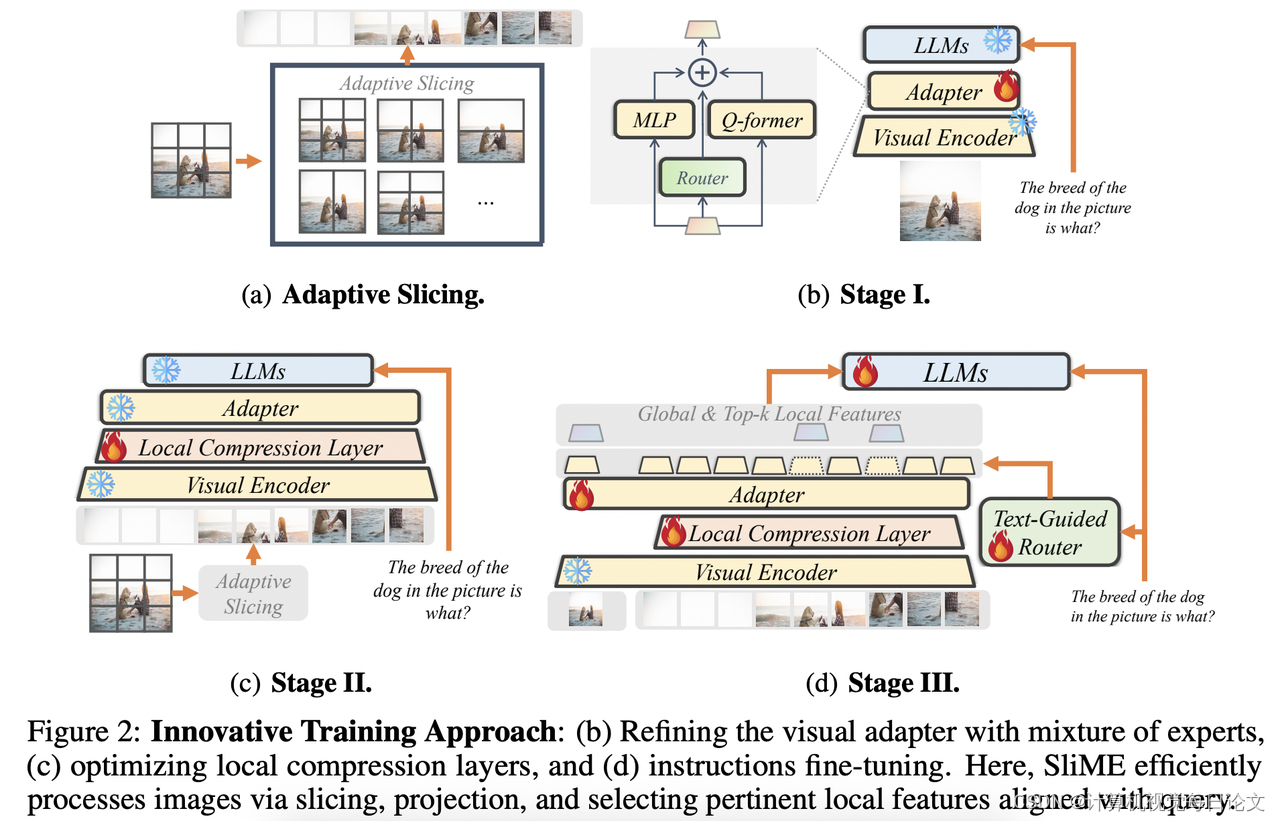
简介:高分辨率的清晰视觉对于大型多模态模型(LMM)的视觉感知和推理至关重要。现有方法通常采用直接的分辨率放大方法,使用全局分支和局部分支(被切片的图像补丁)的组合。这意味着更高分辨率需要更多的局部补丁,导致计算开销过高,同时局部图像标记的优势可能会降低全局上下文。
为解决这些问题,我们提出了一个新的框架和优化策略:
1. 我们使用适配器的混合物从全局视角提取上下文信息,基于不同适配器在不同任务上的优秀表现。
2. 对于局部补丁,我们引入了可学习的查询嵌入来减少图像标记数量,并通过基于相似性的选择器进一步选择最重要的标记。
我们的实验结果表明,"少即是多"的模式,即利用更少但更有信息量的局部图像标记可以提高性能。
此外,我们提倡一种交替训练的方式,确保全局和局部方面的平衡学习,因为端到端训练无法产生最佳结果。
最后,我们还引入了一个对图像细节要求高的挑战性数据集,以增强局部压缩层的训练。
所提出的SliME方法在只有200万个训练数据的情况下,在各种基准测试中取得了领先的性能。
3、Real3D: Scaling Up Large Reconstruction Models with Real-World Images
中文标题:Real3D:使用真实世界图像放大大型重建模型

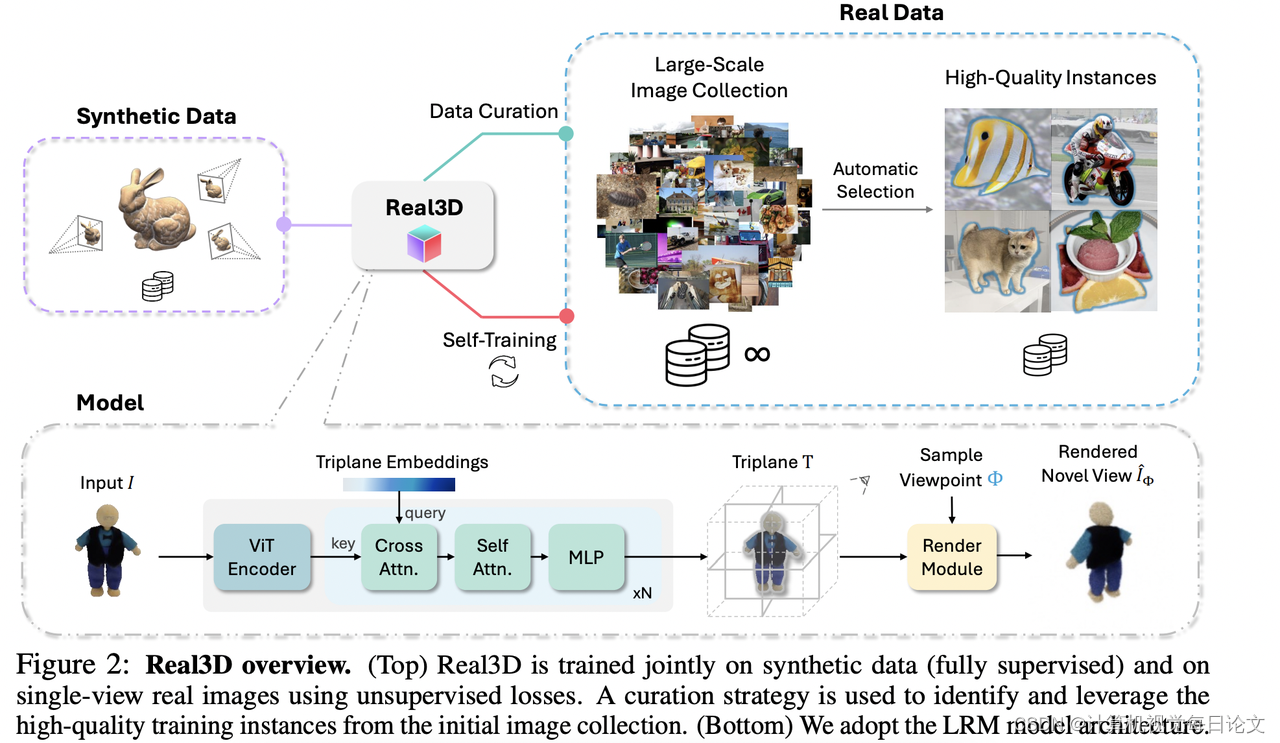
简介:本文介绍了Real3D,这是第一个可以使用单视角真实世界图像进行训练的大型重建模型(LRM)系统。通常,训练单视角LRM的默认策略是使用大规模合成3D资源或多视角捕获的数据集,采用完全监督的方法进行训练。但这些资源难以超越现有数据集的规模,也不一定代表物体形状的真实分布。
为了解决这些限制,本文提出了一种新颖的自我训练框架,可以同时利用现有的合成数据和多样化的单视角真实图像。我们提出了两种无监督损失函数,即像素级和语义级损失函数,即使对于没有地面真实3D或新视角的训练样本,也可以对LRM进行监督。
为了进一步提高性能并扩大图像数据,我们开发了一种自动数据筛选方法,从野外图像中收集高质量的样本。
实验结果表明,Real3D在包括真实和合成数据以及域内和域外形状的四种不同评估设置中始终优于先前的工作。
代码和模型可以在此处找到:https://hwjiang1510.github.io/Real3D/。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









