







决策树是通过一系列规则对数据进行分类的过程。它提供一种在什么条件下会得到什么值的类似规则的方法。决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树。
决策树的优点:计算量简单,可解释性强,比较适合处理有缺失属性值的样本,能够处理不相关的特征;
缺点:容易过拟合(后续出现了随机森林,减小了过拟合现象)或者剪枝。
一、基本术语

在决策树算法的学习过程中,信息增益是特征选择的一个重要指标,它定义为一个特征能够为分类系统带来多少信息,带来的信息越多,说明该特征越重要,相应的信息增益也就越大。
信息增益=信息熵-条件熵。
条件熵:类别下计算的熵值:
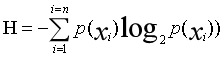
H’=p1H1+p2H2…,则此时的信息增益ΔH=H-H’
(信息熵不变:分类下每个类别所占比例与其对数相乘;因此每个特征的条件熵越小,信息增益越大,该特征可以被选中为做分裂节点)
信息增益代表了在一个条件下,信息复杂度(不确定性)减少的程度。
二、ID3:

计算举例

















 1714
1714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









