







一 、 前言:
在实际数据分析时, 我们常常要对不规范的数据进行规整化,一般规整化的过程比较繁琐。 如果采用pandas 的apply 函数可以快速的批量规整。
二、 案例
例如我们有一份旅客预定房间情况: abe 预订了 1号房, tom 预订了 2、4、5号房, sam 预订了 3号房。现在我们希望知道这些旅客预订的第一个房间。
1. 从一列序列值批量取元素
假设我们拿到下面一份程序员录入的表:
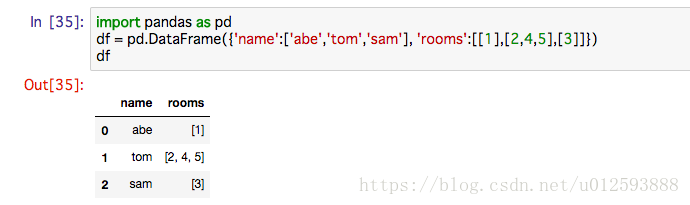
其中,name 为旅客名字, rooms 为旅客预定的房间(可以有多个),rooms 的所有值 都是序列类型的。
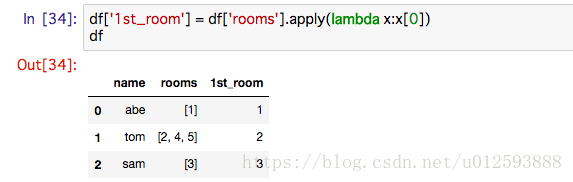
现在我们采用apply 内嵌 lambda 函数取序列第一个元素的方法, 就可以方便地得到旅客预定的第一个房间:
2. 从一列 复杂多样数据类型 的数值批量取元素
然而, 实际当中录入数据更可能把rooms 录入单个的数据(即int 型),我们得到的初始表如下:
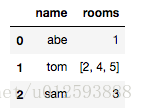
这个时候, 前面的方法会报错, 因为id = 0,2时, rooms 的值均不是list 类型, 执行到 lambda x:x[0] 会报错。
即便采用try except异常处理, 虽然程序可以正常运行, 但不能达到转换的效果。
但假如我们在lambda 函数中考虑了异常的情况: 就可以直接转换了。(见我的上一篇博文 python lambda 函数处理异常。)
代码如下:
def getLambda(x, exec_str, ep_str):
val = 0
try:
exec(exec_str)
except:
exec(ep_str)
return val
df['1st_room'] = df['rooms'].apply(lambda x:getLambda(x, "val = x[0]", "val = x"))我们得到的结果如下:
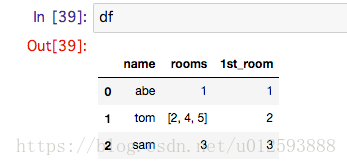
完美的解决了这个问题。

















 220
220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









