




 这篇博客介绍了如何使用Python的pandas库进行数据筛选、替换、删除重复项、排序、创建数据透视表和修改列名等操作,提供了一系列实例来演示这些功能的用法,旨在帮助用户实现高效的数据处理。
这篇博客介绍了如何使用Python的pandas库进行数据筛选、替换、删除重复项、排序、创建数据透视表和修改列名等操作,提供了一系列实例来演示这些功能的用法,旨在帮助用户实现高效的数据处理。
欢迎关注微信公众号:excelwork
一直以来,Excel一直作为一个高效的数据展示、处理、分析的工具被我们使用,但随着处理量增大,不可避免的遇到长时间等待响应或干脆“未响应 ”。因此,我们需要找到替代工具来避免此类问题,Python中的pandas是如何像Excel一样处理数据呢。
”。因此,我们需要找到替代工具来避免此类问题,Python中的pandas是如何像Excel一样处理数据呢。
先构造示例数据(python3):
import pandas as pddata=pd.DataFrame([{2,5,6,7,8},(2,5,6,7,8),[12,31,4,5,6],range(11,111,20),range(9,23,3)],columns=['col_a','col_b','col_c','col_d','col_e'],index=['row_1','row_2','row_3','row_4','row_5'])
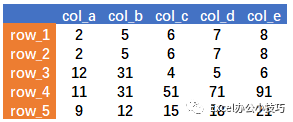
一、数据筛选、替换
1.1 数据筛选
我们通常使用去除重复项功能,目的就在于此,pandas中使用drop_duplicates函数实现,参数默认情况下是保留重复值中的一个,或者keep='first'。
print(data[data['col_a']& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2871
2871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









