







面试题
如果对比过 vllm 进行大模型推理 和 直接调用模型generate 就会知道 vllm可以让推理速度比直接调用模型generate快2-4倍。
那问题来了,为什么vllm能够加快大模型推理速度?
标准答案
问题一:大模型推理存在哪些问题?
在回答该问题之前,需要先理清楚 LLMs 结构特点:
大模型一般都是采用自回归生成方式,即根据前面的语句预测下一个字的概率:
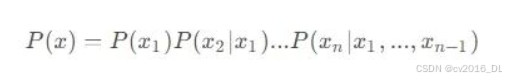
而自回归生成方式方式会存在以下问题:
-
问题一: KV Cache 太大
LLM 服务需要为每个请求维护一个键值(KV)缓存,用于存储模型在生成文本时的上下文信息。随着请求数量的增加,KV缓存的大小迅速增长,占用大量 GPU 内存。
对于13B 参数的模型,单个请求的 KV Cache 可能就需要数 1.6 GB的内存。这限制了同时处理的请求数量,进而限制了系统的吞吐量。
-
问题二:复杂的解码算法
LLM 服务通常提供多种解码算法供用户选择,如贪婪解码、采样解码和束搜索(beam search)。这些算法对内存管理的复杂性有不同的影响。
例如,在并行采样中,多个输出可以共享相同的输入提示的 KV 缓存,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5410
5410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









