







OmniVision-968M 已于 2024 年 11 月 21 日进行了重大升级,带来了多项改进和新功能。
- 实时预览:您可以在 Hugging Face Space 上实时预览和体验 OmniVision-968M 的新功能和改进。访问链接 👉 Hugging Face Space 。
- 模型文件更新:最新的模型文件已更新并可在以下位置下载:🤗 NexaAIDev/omnivision-968M 。
以下是此次升级的主要亮点:
一、主要特点
-
9倍的Token减少:
- 图像Token减少:将图像Token从729减少到81,大幅降低了延迟和计算成本。
- 优势:这种减少不仅提高了处理速度,还降低了对计算资源的需求,使其更适合在资源受限的边缘设备上运行。
-
增强的准确性:
- 减少幻觉:通过使用来自可信数据的DPO(Direct Policy Optimization)训练,减少了模型生成幻觉的可能性。
- 优势:这种训练方法提高了模型的可靠性和准确性,使其在实际应用中表现更佳。
二、技术细节
- 架构改进:在 LLaVA 的基础上进行了优化,特别是在图像Token处理和训练方法上进行了改进。
- DPO训练:通过使用可信数据进行直接策略优化训练,提高了模型的准确性和可靠性。
应用场景
OmniVision 的设计使其特别适合以下应用场景:
- 边缘计算设备:由于其低延迟和低计算成本,OmniVision 非常适合在智能手机、物联网设备和其他边缘计算设备上运行。
- 多模态应用:能够同时处理视觉和文本输入,使其适用于需要综合处理多种数据类型的应用,如智能助手、增强现实(AR)和虚拟现实(VR)等。
- 实时应用:由于其高效的处理能力,OmniVision 可以用于需要实时响应的应用,如实时翻译、实时图像识别和实时数据分析等。
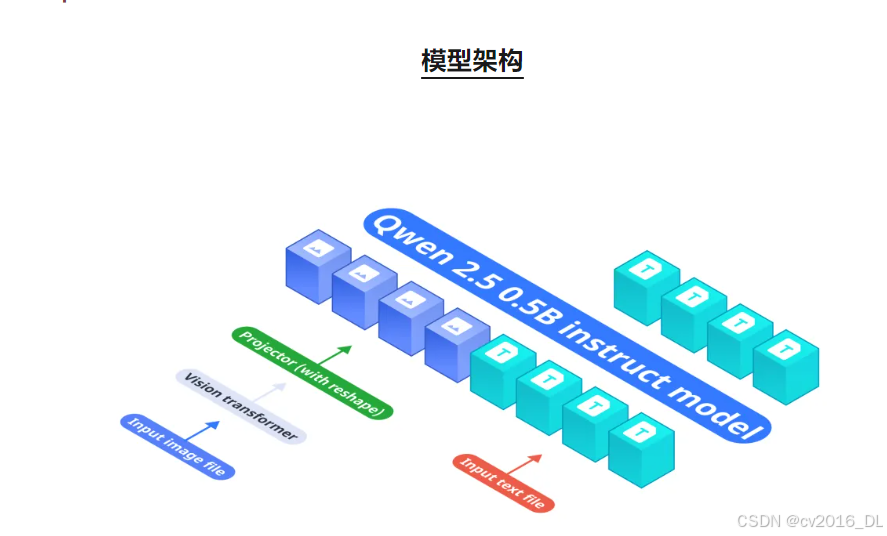
1. 基础语言模型
OmniVision 使用 Qwen2.5-0.5B-Instruct 作为基础语言模型,负责处理文本输入。这款模型以高效的文本理解能力和轻量化设计为特点,为视觉语言任务提供了稳固的语言处理基础。
2.视觉编码器
OmniVision 的视觉编码器为 SigLIP-400M,运行在 384×384 分辨率下,使用 14×14 的 patch 大小生成高质量的图像嵌入。这一模块确保了视觉信号的细粒度表示。
3.投影层
OmniVision 的投影层采用多层感知机(MLP)结构,将视觉编码器生成的嵌入与语言模型的 Token 空间对齐。相比传统的 LLaVA 架构,OmniVision 的投影层设计实现了 9倍图像Token压缩,将图像 Token 从 729(27×27)减少到 81(9×9),大幅降低延迟和计算成本,同时保持信息完整性。
工作流程
视觉编码器将输入图像转化为嵌入,随后投影层调整嵌入以匹配 Qwen2.5-0.5B-Instruct 的 Token 空间,从而实现端到端的视觉语言理解。
三、训练方法
1. 预训练
预训练阶段以大规模图像-文本对(如图像描述数据集)为基础,建立基本的视觉与语言对齐能力。在这一阶段,仅解冻投影层参数,以学习视觉嵌入与文本 Token 空间之间的基本关系。
2. 监督微调(SFT)
在第二阶段,OmniVision 使用基于图像的问题回答数据集(如多轮问答和对话历史)进行微调。通过对图像与文本上下文的联合建模,模型生成的响应更加符合实际场景需求。
3. 直接偏好优化(DPO)
最后一个阶段是直接偏好优化(DPO)。OmniVision 首先利用基础模型生成响应,然后由教师模型进行最小化编辑修正,保留响应的语义相似性,同时专注于关键性输出的优化。这些经过修改的响应形成“被选-被拒”对,用于进一步微调模型输出质量。DPO 训练方法以小幅调整代替显著改动,确保在改进质量的同时,不破坏模型核心能力。
四、OmniVision 的应用场景
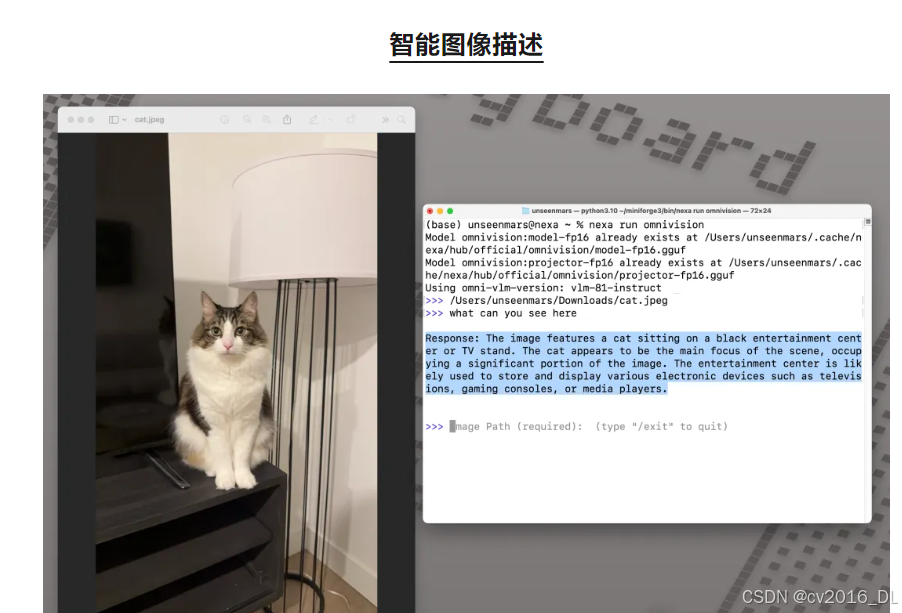
提问:“你看到了什么?”
结果:OmniVision 生成基于图的精确文字描述,适合内容生成与监控分析
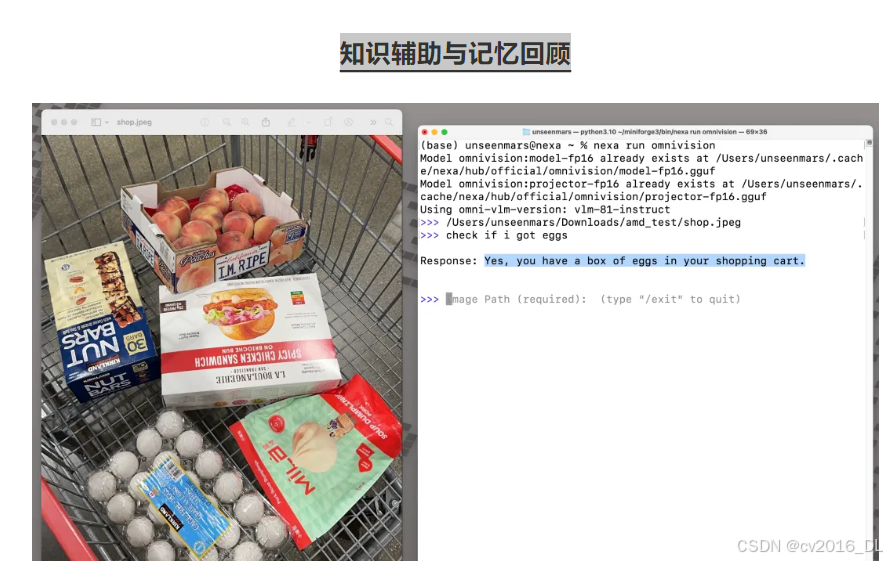
提问:“我买鸡蛋了么?”
结果:结合图像和上下文记忆,帮助用户回顾信息和场景。
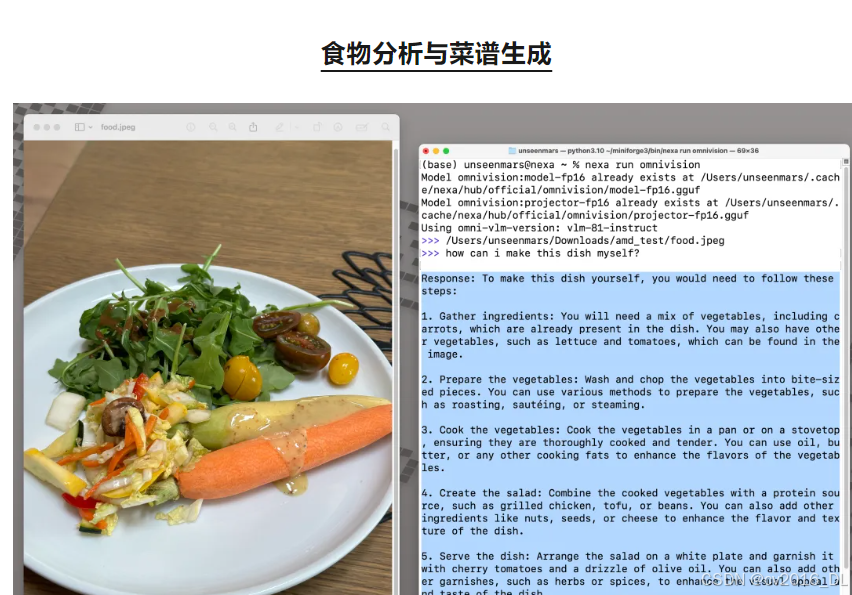
提问:“这是什么菜?怎么做?”
结果:通过识别图像中的食物,OmniVision 能生成相应菜谱,提升生活便捷性。
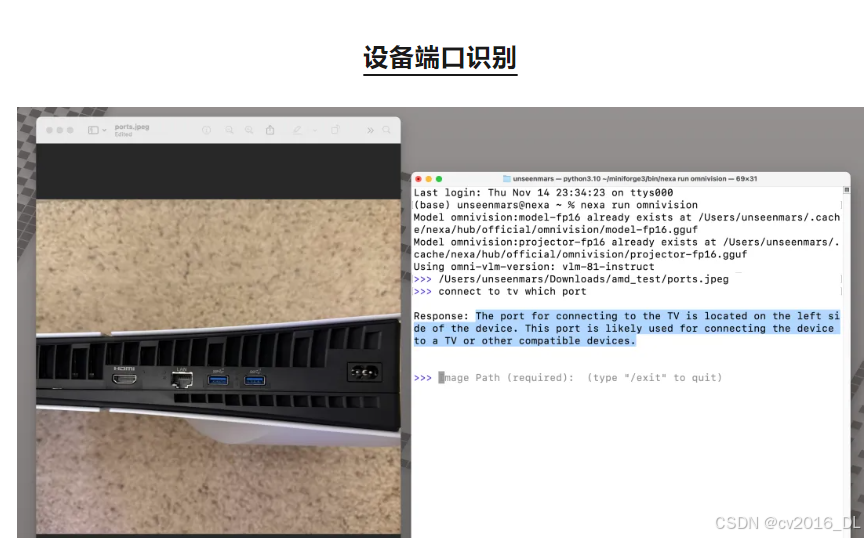
提问:“PS5 的 HDMI 接口在哪?”
结果:精准识别设备细节,适合消费者支持场景。
五、模型评测
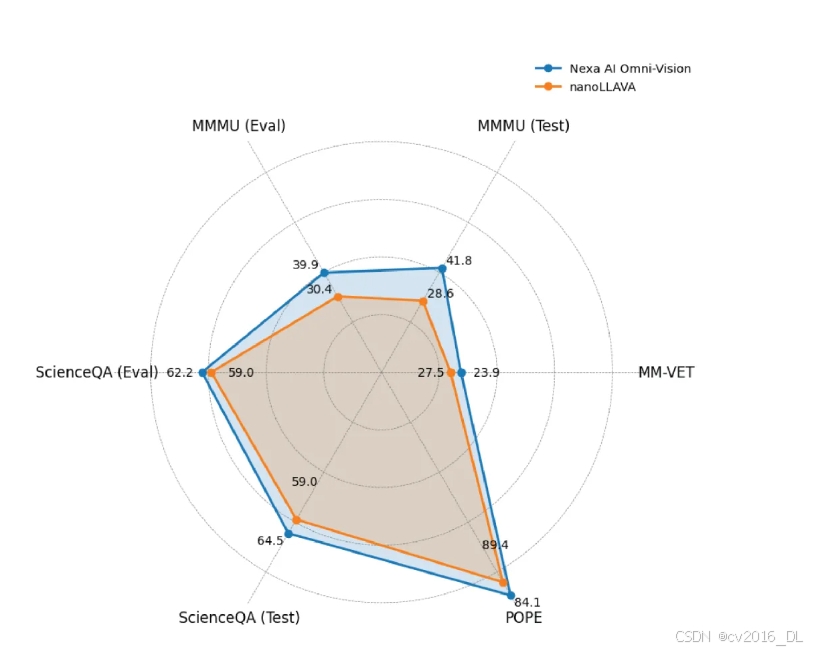
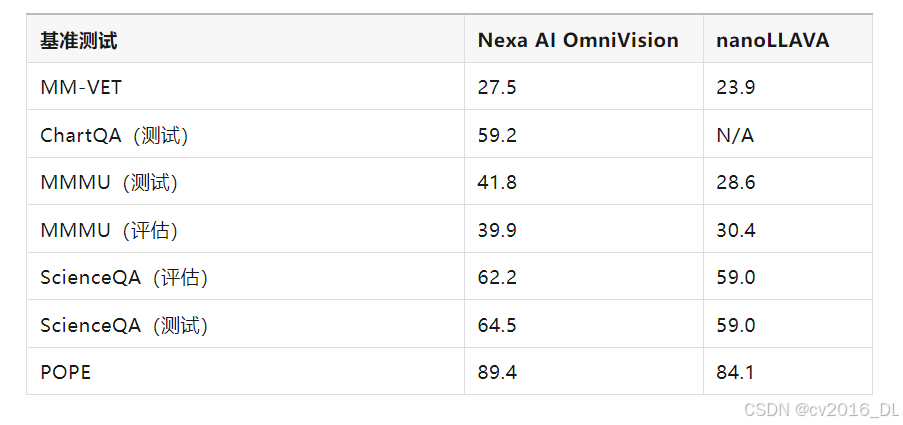
Omnivision 与 nanoLLAVA 的性能对比
在 MM-VET、ChartQA、MMMU、ScienceQA、POPE 等基准数据集上进行了系列实验,以评估 OmniVision 的性能。在所有任务中,OmniVision 的表现均优于之前全球最小的视觉语言模型。
七、快速上手 OmniVision
方法一:在线试用
访问 Hugging Face Space 平台:https://huggingface.co/spaces/NexaAIDev/omnivlm-dpo-demo
方法二:本地部署
1. 安装 Nexa SDK
访问 Nexa AI 平台:https://nexa.ai/NexaAI/omnivision/gguf-fp16/readme
在终端中运行以下命令:
nexa run omnivision2. 启动交互界面
使用 Streamlit,本地可视化操作更直观:nexa run omnivision -st
硬件需求
OmniVision 的 FP16 版本仅需 988MB 内存和 948MB 存储,适配多种设备,无论是开发者的个人电脑还是企业的边缘计算设备都能轻松运行。
八、未来发展方向
在当前 OmniVision 已展示的能力基础上,我们将持续推进模型的进一步优化:
-
扩展 DPO 数据集范围,提升复杂任务的响应质量。
-
增强文档理解能力,拓宽多模态场景适配。
-
打造工业级端侧 AI 多模态解决方案。

















 883
883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









