







 本文详细介绍了GAN的基本原理,DCGANs的改进点,以及WGAN如何解决了GAN训练的不稳定性问题,提供了一个评估训练进程的明确指标,并给出了相关函数在tensorflow和pytorch中的实现说明。
本文详细介绍了GAN的基本原理,DCGANs的改进点,以及WGAN如何解决了GAN训练的不稳定性问题,提供了一个评估训练进程的明确指标,并给出了相关函数在tensorflow和pytorch中的实现说明。
GAN、 DCGANs:deep convolutional generative adversarial networks、 WGANS:Wasserstein GAN
DCGANs:deep convolutional generative adversarial networks、
WGANS:Wasserstein GAN)
GAN
GAN模型没有损失函数,优化过程是一个“二元极小极大博弈(minimax two-player game)”问题:
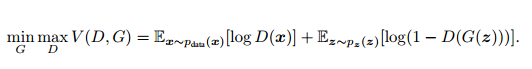
这是关于判别网络D和生成网络G的价值函数(Value Function),训练网络D使得最大概率地分对训练样本的标签(最大化log D(x)),训练网络G最小化log(1 – D(G(z))),即最大化D的损失。训练过程中固定一方,更新另一个网络的参数,交替迭代,使得对方的错误最大化,最终,G 能估测出样本数据的分布。生成模型G隐式地定义了一个概率分布Pg,我们希望Pg 收敛到数据真实分布Pdata。论文证明了这个极小化极大博弈当且仅当Pg = Pdata时存在最优解,即达到纳什均衡,此时生成模型G恢复了训练数据的分布,判别模型D的准确率等于50%。

DCGANs
改进后相比原始GAN的算法实现流程却只改了四点:
1.将所有的池化层变为带步长的卷积层(分类器),带分数步长的卷积层(生成器)
2.在分类器和生成器中都使用batchnorm
3.去除全连接层
4.在生成器中除了输出层使用tanh以外,其他激活层均使用ReLU
5.在分类器中激活层均使用LeakyRelu
Generator生成器:
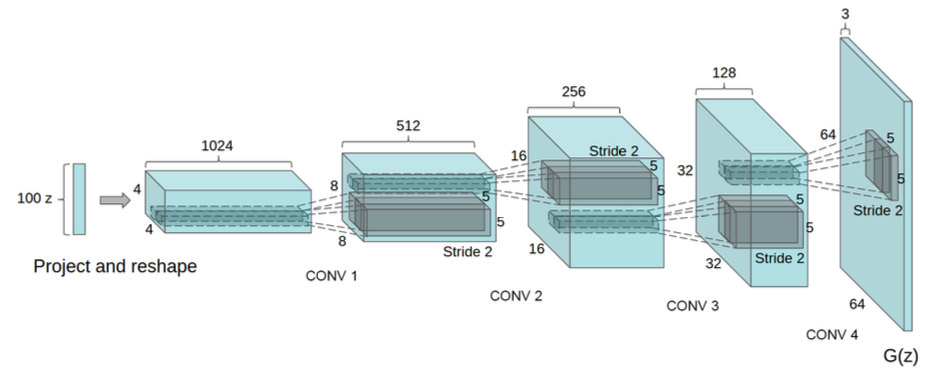
相应的tensorflow代码:
def generator(self, z, y=None):
with tf.variable_scope("generator") as scope:
if not self.y_dim:
s_h, s_w = self.output_height, self.output_width
s_h2, s_w2 = conv_out_size_same(s_h, 2), conv_out_size_same(s_w, 2)
s_h4, s_w4 = conv_out_size_same(s_h2, 2), conv_out_size_same(s_w2, 2)
s_h8, s_w8 = conv_out_size_same(s_h4, 2), conv_out_size_same(s_w4, 2)
s_h16, s_w16 = conv_out_size_same(s_h8, 2), conv_out_size_same(s_w8, 2)
# project `z` and reshape
self.z_, self.h0_w, self.h0_b = linear(
z, self.gf_dim*8*s_h16*s_w16, 'g_h0_lin', with_w=True)
self.h0 = tf.reshape(
self.z_, [-1, s_h16, s_w16, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(self.h0))
self.h1, self.h1_w, self.h1_b = deconv2d(
h0, [self.batch_size, s_h8, s_w8, self.gf_dim*4], name='g_h1', with_w=True)
h1 = tf.nn.relu(self.g_bn1(self.h1))
h2, self.h2_w, self.h2_b = deconv2d(
h1, [self.batch_size, s_h4, s_w4, self.gf_dim*2], name='g_h2', with_w=True)
h2 = tf.nn.relu(self.g_bn2(h2))
h3, self.h3_w, self.h3_b = deconv2d(
h2, [ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1678
1678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









