







目录:
无效query介绍
非人机交互识别
意图不明识别
小结
无效query介绍
用户query的类型划分:

非人机交互query: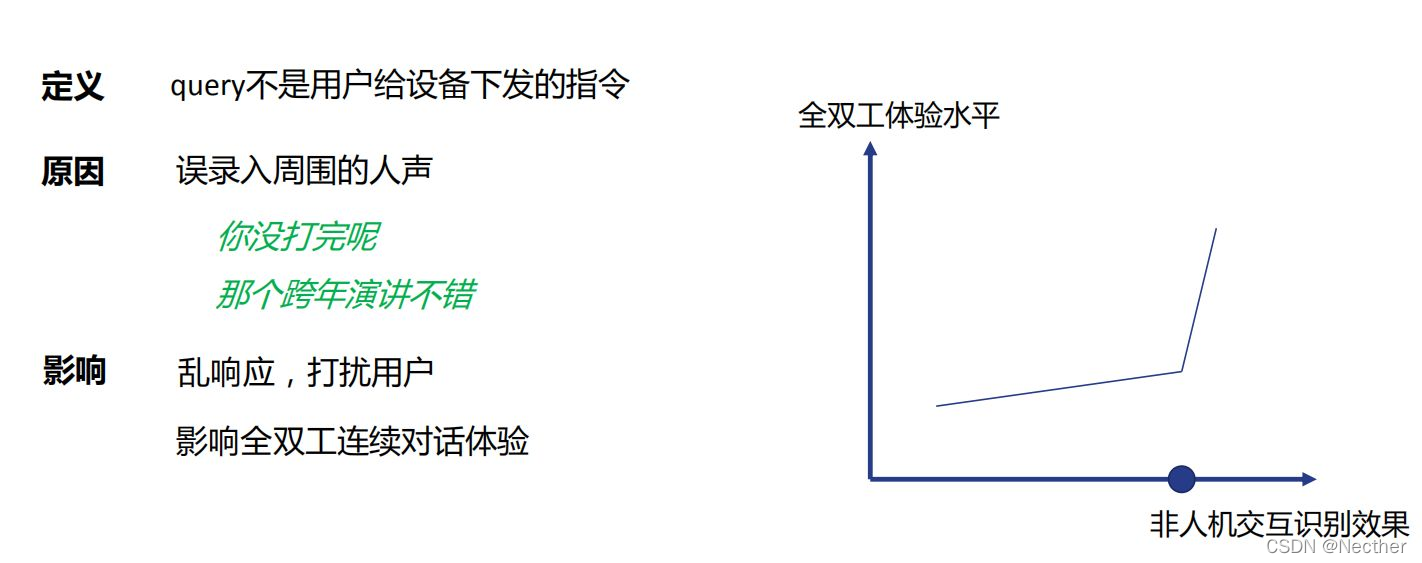
意图不明query:
无效query体验优化:
非人机交互:识别+不响应
意图不明:识别+兜底回复或引导澄清
非人机交互识别
非人机交互识别的难点:
信息不完备:
判断是否人机交互,需要多维度信息(声音、视觉等)
只靠音频信息会有很大歧义性
语音变化的多样性:
同一句话,由于语气、语调、语速、音色的不同,产生不同的音频
数据样本难以覆盖每种类型的语音
鸡尾酒会效应:
嘈杂环境下的有效指令识别
非人机交互识别-问题建模:


非人机交互识别-解决方案:
建模:针对单轮语音的二分类
关键任务:数据集构建+特征和模型设计
非人机交互识别-数据集构造:
非人机数据标注成本很高:听音频标注,标注10万条样本耗费100人日。
提升数据标注质量:存在大量模糊样本,需要提高Label的一致性
详细的标注规范,针对各类音频提供示例
多人标注验证
数据质量的提升→模型效果的提升
样本挖掘:
提升样本的多样性
随机采样
正样本挖掘:基于ASR置信度、基于误唤醒检测
提升样本的有效性
挖掘困难样本:模型打分置信度低
挖掘错误分类样本
非人机交互识别-模型分析:
语音特征
频谱 优于 mfcc、fbank特征
加入通过声学信号处理获取的特征没有提升
语音Encoder
CNN -> CNN+LsTM+ATTENTION
CNN是个很强的baseline
文本Encoder
CNN、TRANsFORMER、BERT效果差异不明显
语音Encoder和文本Encoder的融合
concat 优于 attention
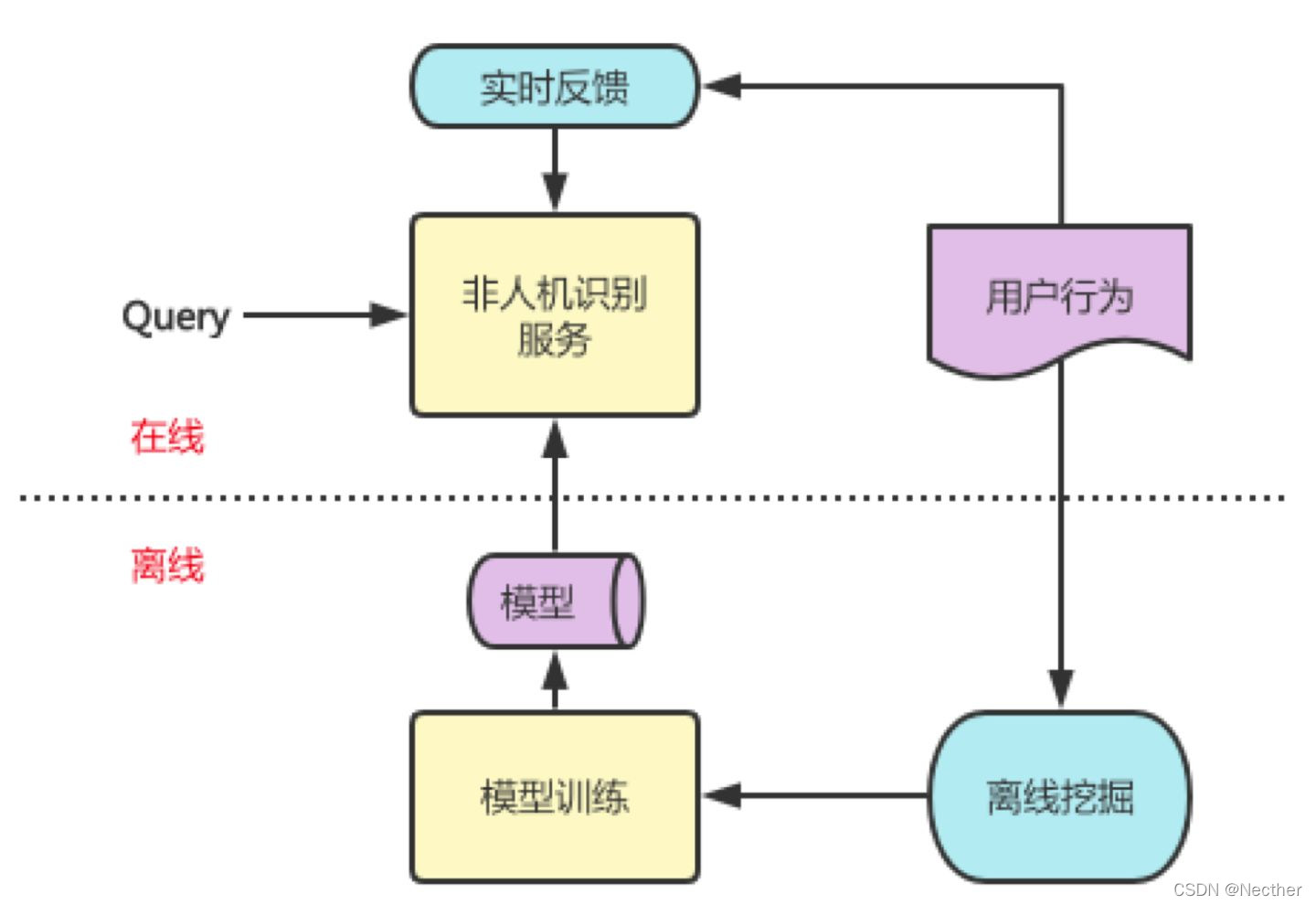
用户行为反馈
用户反馈类型
误拒识反馈:拒识后重复说
欠拒识反馈:用户说"闭嘴"
反馈生效方式
在线:动态调整策略
离线:反馈数据进入模型迭代
个性化策略
引入Context:基于用户的历史行为和session
非人机交互识别-能力现状评估
疑向:基于语音的非人机交互识别,天花板在哪里?
评估方法:评估普通人在非人机交互识别上的平均水平。
评估对象:普通标注人员,未经过非人机交互标注的专业训练。
结论:
普通人的识别准确率/召回率方差很大,平均F1值约为0.86。
目前在手机语音助手上已经接近普通人的水平。
意图不明识别
意图不明识别-问题类型划分:

乱序无意义识别:

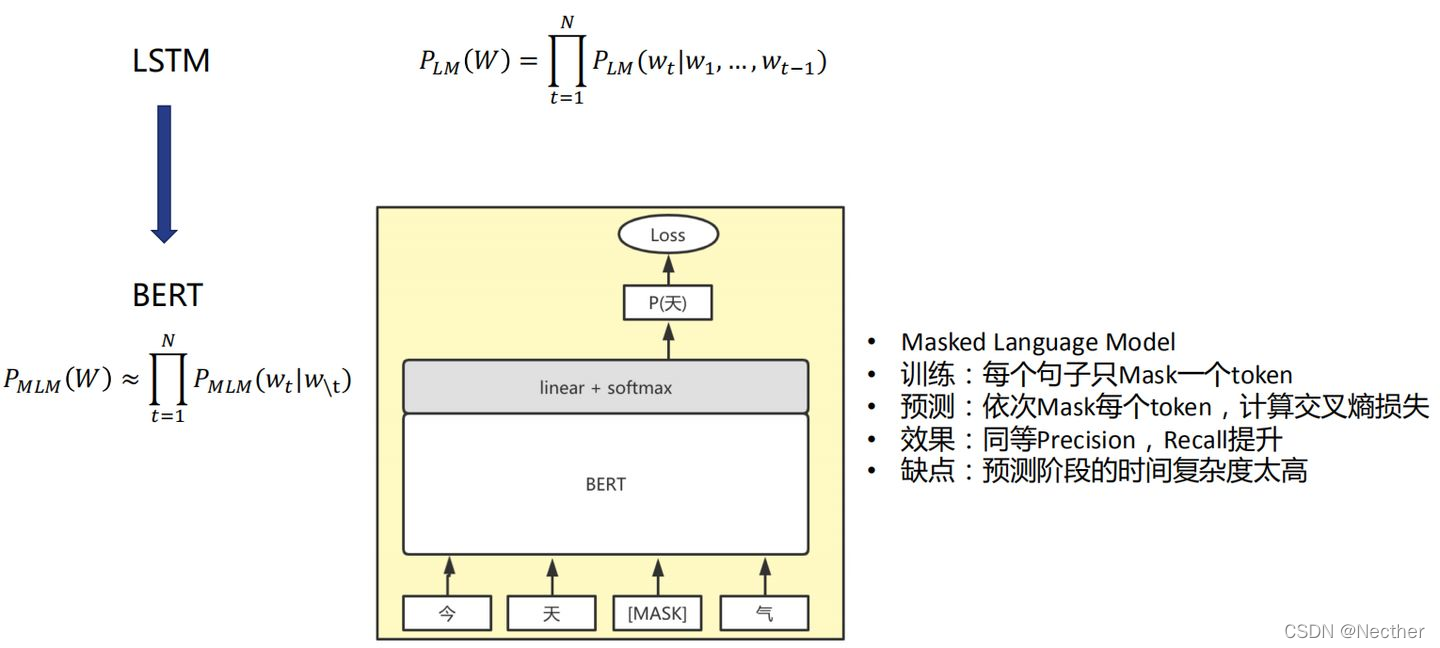
乱序无意义识别-如何得到更合理的perplexity:
乱序无意义识别-语言模型方案:
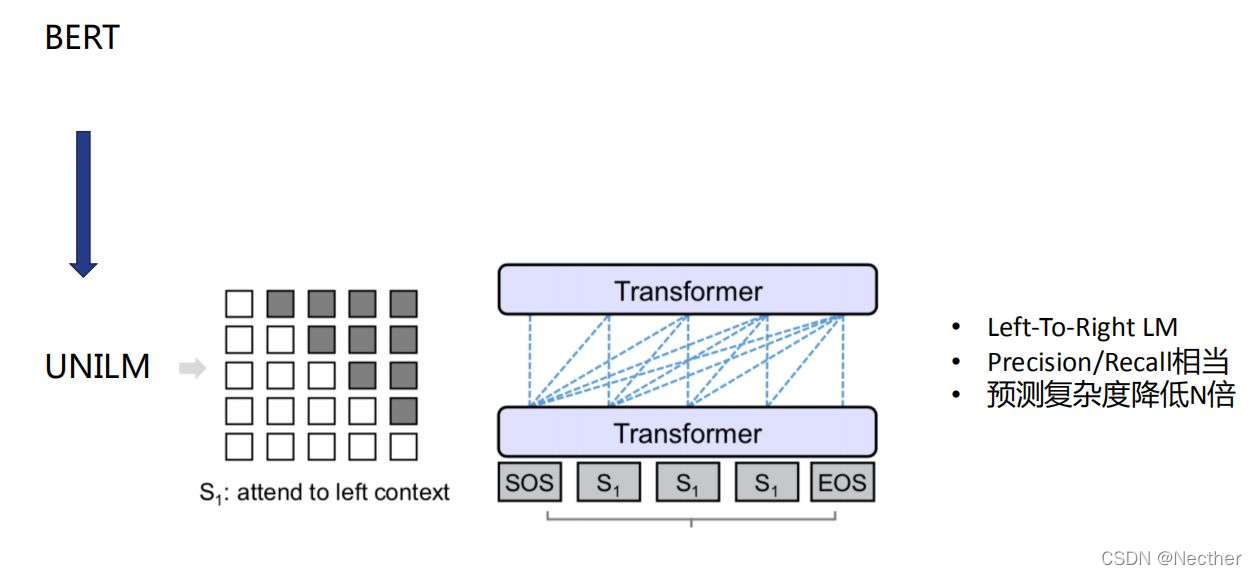
乱序无意义识别-语言模型方案面临的挑战:
有序和乱序边界的样本如何区分:

**缺点:**只用perplexity作为阈值,无法有效区分边界区域的混淆样本
**解决思路:**引入更丰富的特征,训练二分类,识别边界区域的正负样本
表达不完整识别:



小结:
非人机交互识别
信息不完备的机器学习任务
基于语音和语义特征的神经网络模型
意图不明识别
乱序无意义识别和表达不完整识别两个任务
技术方案框架:语言模型+ 分类模型


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









