







Ensembles can give you a boost in accuracy on your dataset. In this chapter you will discover how you can create some of the most powerful types of ensembles in Python using scikit-learn. This lesson will step you through Boosting, Bagging and Majority Voting and show you how you can continue to ratchet up the accuracy of the models on your own datasets. After completing this lesson you will know:
- How to use bagging ensemble methods(集成算法) such as bagged decision trees, random forrest and extra trees.
- How to use boosting ensemble methods such AdaBoost and stochastic gradient boosting.
- How to use voting ensemble methods to combine the prediction from multiple algorithms.
1.1 Combine Models Into Ensemble Predictions
The three most popular methods for combining the predictions from different models are:
- Bagging. Building multiple models (typically of the same type) from different subsamples of the training dataset.
- Boosting. Building multiple models (typically of the same type) each of which learns to fix the prediction errors of a prior model in the sequence of models.
- Voting. Building multiple models (typically of differing types) and simple statistics (like calculating the mean) are used to combine predictions.
1.2 Bagging Algorithms
Bootstrap Aggregation (or Bagging) involves taking multiple samples from your training dataset (with replacement) and training a model for each sample. The final output prediction is averaged across the predictions of all of the sub-models. The three bagging models covered in this section are as follows:
- Bagged Decision Trees.
- Random Forest.
- Extra Trees.
1.2.1 Bagged Decision Trees(袋装决策树)
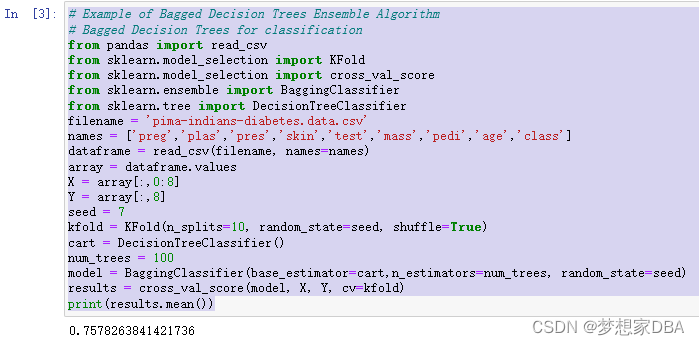
Bagging performs best with algorithms that have high variance. A popular example are decision trees, often constructed without pruning. In the example below is an example of using the BaggingClassifier with the Classification and Regression Trees algorithm (CART 分类与回归树)(DecisionTreeClassifier). A total of 100 trees are created.
# Example of Bagged Decision Trees Ensemble Algorithm
# Bagged Decision Trees for classification
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
filename = 'pima-indians-diabetes.data.csv'
names = ['preg','plas','pres','skin','test','mass','pedi','age','class']
dataframe = read_csv(filename, names=names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
seed = 7
kfold = KFold(n_splits=10, random_state=seed, shuffle=True)
cart = DecisionTreeClassifier()
num_trees = 100
model = BaggingClassifier(base_estimator=cart,n_estimators=num_trees, random_state=seed)
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())Running the example, we get a robust estimate of model accuracy.
1.2.2 Random Forest
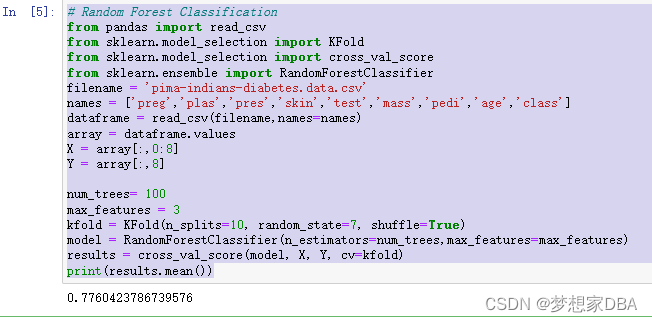
Random Forests is an extension of bagged decision trees. Samples of the training dataset are taken with replacement, but the trees are constructed in a way that reduces the correlation between individual classifiers. Specifically, rather than greedily choosing the best split point in the construction of each tree, only a random subset of features are considered for each split. You can construct a Random Forest model for classification using the RandomForestClassifier class . The example below demonstrates using Random Forest for classification with 100 trees and split points chosen from a random selection of 3 features.
# Random Forest Classification
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
filename = 'pima-indians-diabetes.data.csv'
names = ['preg','plas','pres','skin','test','mass','pedi','age','class']
dataframe = read_csv(filename,names=names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
num_trees= 100
max_features = 3
kfold = KFold(n_splits=10, random_state=7, shuffle=True)
model = RandomForestClassifier(n_estimators=num_trees,max_features=max_features)
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())Running the example provides a mean estimate of classification accuracy.
1.2.3 Extra Trees
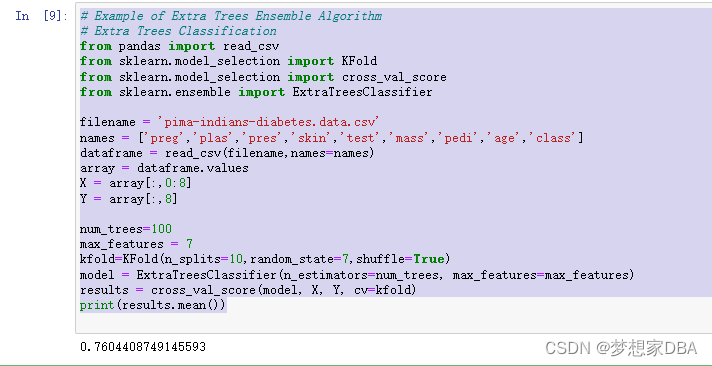
Extra Trees are another modification of bagging where random trees are constructed from samples of the training dataset. You can construct an Extra Trees model for classification using the ExtraTreesClassifier class. The example below provides a demonstration of extra trees with the number of trees set to 100 and splits chosen from 7 random features.
# Example of Extra Trees Ensemble Algorithm
# Extra Trees Classification
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import ExtraTreesClassifier
filename = 'pima-indians-diabetes.data.csv'
names = ['preg','plas','pres','skin','test','mass','pedi','age','class']
dataframe = read_csv(filename,names=names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
num_trees=100
max_features = 7
kfold=KFold(n_splits=10,random_state=7,shuffle=True)
model = ExtraTreesClassifier(n_estimators=num_trees, max_features=max_features)
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())Running the example provides a mean estimate of classification accuracy.
1.3 Boosting Algorithms(提升算法)
Boosting ensemble algorithms creates a sequence of models that attempt to correct the mistakes of the models before them in the sequence. Once created, the models make predictions which may be weighted by their demonstrated accuracy and the results are combined to create a final output prediction. The two most common boosting ensemble machine learning algorithms are:
- AdaBoost
- Stochastic Gradient Boosting
1.3.1 AdaBoost
AdaBoost was perhaps the first successful boosting ensemble algorithm. It generally works by weighting instances in the dataset by how easy or difficult they are to classify, allowing the algorithm to pay or less attention to them in the construction of subsequent models. You can construct an AdaBoost model for classification using the AdaBoostClassifier class. The example below demonstrates the construction of 30 decision trees in sequence using the AdaBoost algorithm.
# Example of AdaBoost Ensemble Algorithm
# AdaBoost Classification
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import AdaBoostClassifier
filename = 'pima-indians-diabetes.data.csv'
names = ['preg','plas','pres','skin','test','mass','pedi','age','class']
dataframe = read_csv(filename,names=names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
num_trees=30
seed = 7
kfold = KFold(n_splits=10, random_state=seed, shuffle=True)
model = AdaBoostClassifier(n_estimators=num_trees, random_state=seed)
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())Running the example provides a mean estimate of classification accuracy.

1.3.2 Stochastic Gradient Boosting
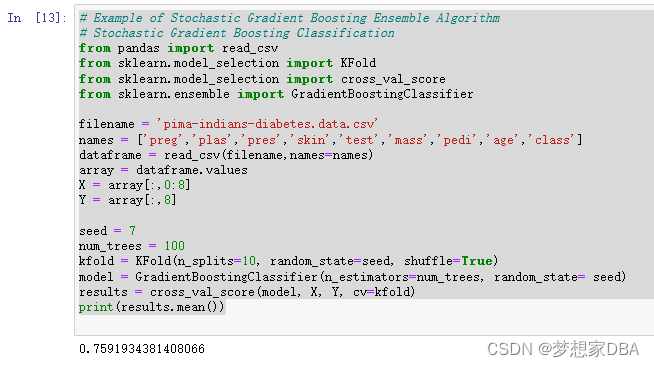
Stochastic Gradient Boosting (also called Gradient Boosting Machines) are one of the most sophisticated ensemble techniques. It is also a technique that is proving to be perhaps one of the best techniques available for improving performance via ensembles. You can construct a Gradient Boosting model for classification using the GradientBoostingClassifier class. The example below demonstrates Stochastic Gradient Boosting for classification with 100 trees.
# Example of Stochastic Gradient Boosting Ensemble Algorithm
# Stochastic Gradient Boosting Classification
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import GradientBoostingClassifier
filename = 'pima-indians-diabetes.data.csv'
names = ['preg','plas','pres','skin','test','mass','pedi','age','class']
dataframe = read_csv(filename,names=names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
seed = 7
num_trees = 100
kfold = KFold(n_splits=10, random_state=seed, shuffle=True)
model = GradientBoostingClassifier(n_estimators=num_trees, random_state= seed)
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())Running the example provides a mean estimate of classification accuracy.
1.4 Voting Ensemble(投票集成法)
Voting is one of the simplest ways of combining the predictions from multiple machine learning algorithms. It works by first creating two or more standalone models from your training dataset. A Voting Classifier can then be used to wrap your models and average the predictions of the sub-models when asked to make predictions for new data. The predictions of the sub-models can be weighted, but specifying the weights for classifiers manually or even heuristically is difficult. More advanced methods can learn how to best weight the predictions from sub-models, but this is called stacking (stacked aggregation) and is currently not provided in scikit-learn.
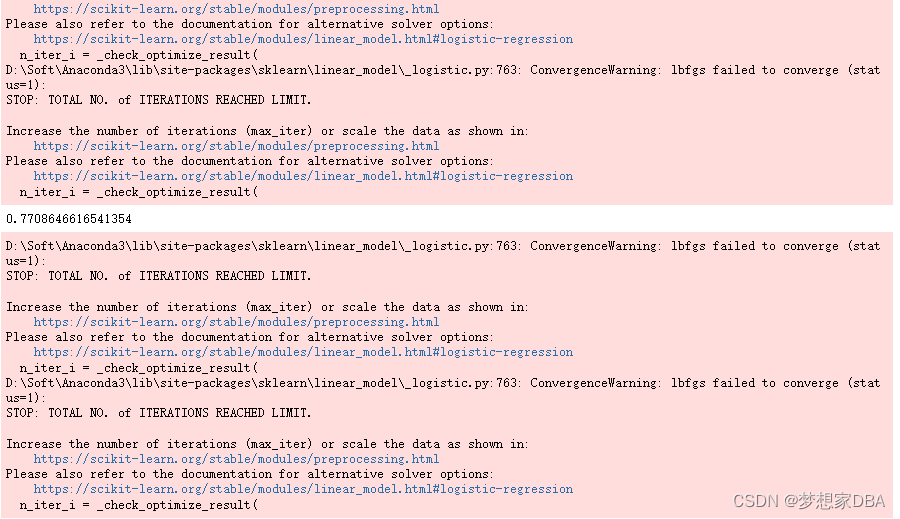
You can create a voting ensemble model for classification using the VotingClassifier class. The code below provides an example of combining the predictions of logistic regression, classification and regression trees and support vector machines together for a classification problem.
# Example of the voting Ensemble Algorithm
#Voting Ensemble for Classification
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
filename= 'pima-indians-diabetes.data.csv'
names = ['preg','plas','pres','skin','test','mass','pedi','age','class']
dataframe = read_csv(filename,names=names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
kfold = KFold(n_splits=10, random_state=7,shuffle=True)
# create the sub models
estimators = []
model1 = LogisticRegression()
estimators.append(('logistic',model1))
model2 = DecisionTreeClassifier()
estimators.append(('cart',model2))
model3 = SVC()
estimators.append(('svm',model3))
# create the ensemble model
ensemble = VotingClassifier(estimators)
results = cross_val_score(ensemble, X, Y, cv=kfold)
print(results.mean())
Running the example provides a mean estimate of classification accuracy.
1.5 Summary
In this chapter you discovered ensemble machine learning algorithms for improving the performance of models on your problems. You learned about:
- Bagging Ensembles including Bagged Decision Trees, Random Forest and Extra Trees.
- Boosting Ensembles including AdaBoost and Stochastic Gradient Boosting.
- Voting Ensembles for averaging the predictions for any arbitrary models.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









