







 本文介绍了贝叶斯分类器的基础,包括朴素贝叶斯方法,用于文本分类。通过处理RSS源数据,展示了如何使用Python实现从词汇列表到向量的转换,训练分类器,以及应用到垃圾邮件和区域态度分析。讨论了概率分布、条件概率和贝叶斯定理,并提供了实际代码示例,如文档分类和垃圾邮件检测。
本文介绍了贝叶斯分类器的基础,包括朴素贝叶斯方法,用于文本分类。通过处理RSS源数据,展示了如何使用Python实现从词汇列表到向量的转换,训练分类器,以及应用到垃圾邮件和区域态度分析。讨论了概率分布、条件概率和贝叶斯定理,并提供了实际代码示例,如文档分类和垃圾邮件检测。
This article covers:
- Using probability distributions for classification
- Learning the naive Bayes classifier
- Parsing data from RSS feeds
- Using naive Bayes to reveal regional attitudes
4.1 Classifying with Bayesian decision theory
Naive Bayes
Pros: Works with a small amount of data,handles multiple classes
Cons: Sensitive to how the input data is prepared
Works with: Nominal values
Naive Bayes is a subset of Bayesian decision theory,so we need to talk about Bayesian decision theory quickly before we get to naive Bayes.
That’s Bayesian decision theory in a nutshell: choosing the decision with the highest probability.
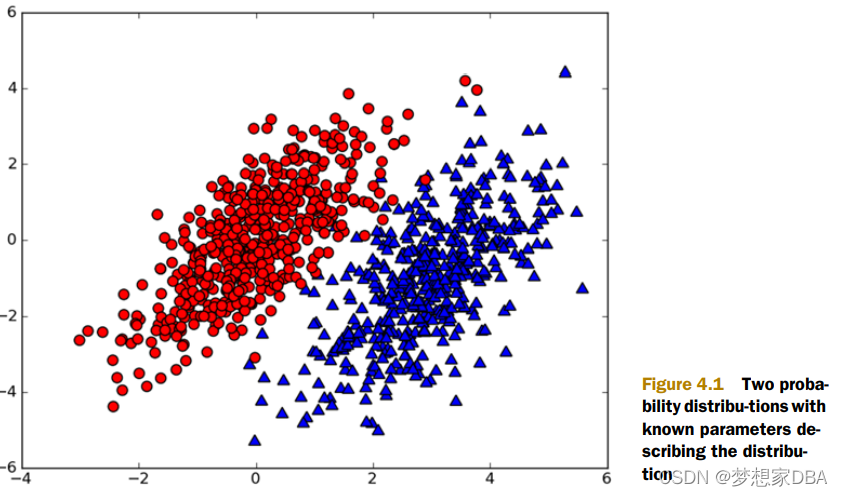
If you can represent the data in six floating-point numbers, and the code to calculate the probability is two lines in Python, which would you rather do?
- Use kNN from chapter 1, and do 1,000 distance calculations.
- Use decision trees from chapter 2, and make a split of the data once along the x-axis and once along the y-axis.
- Compute the probability of each class, and compare them
4.2 Conditional probability
Let's spend a few minutes talking about probability and conditional probability.
Another useful way to manipulate conditional probabilities is known as Bayes’ rule. Bayes’ rule tells us how to swap the symbols in a conditional probability statement. If we have P(x|c) but want to have P(c|x), we can find it with the following:
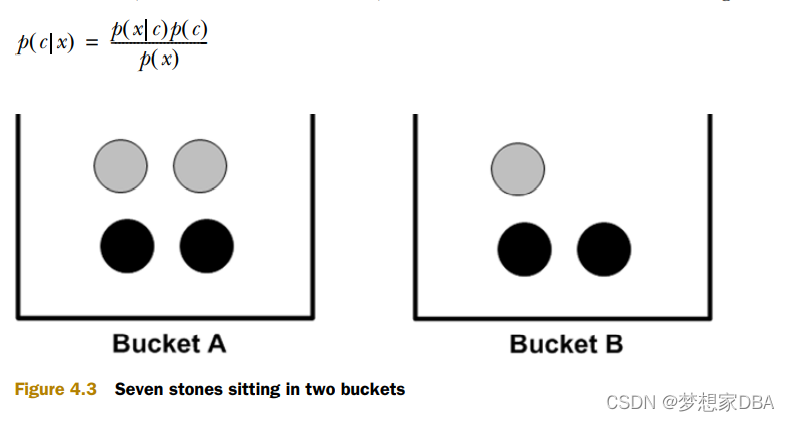
The next section will discuss how to use conditional probabilities with Bayesian decision theory.
4.3 Classifying with conditional probabilities
Bayes' rule is applied to these statements as follows:
with these definitions, we can define the Bayesian classification rule:
If , then class is
.
If , then class is
.
Using Bayes's rule, we can calculate this unknown three known quantities.We'll soon write some code to calculate these probabilities and classify items using Bayes's rule.
4.4 Document classification with naive Bayes
One important application of machine learning is automatic document classification.
General approach to naïve Bayes
1. Collect: Any method. We’ll use RSS feeds in this chapter.
2. Prepare: Numeric or Boolean values are needed.
3. Analyze: With many features, plotting features isn’t helpful. Looking at histograms is a better idea.
4. Train: Calculate the conditional probabilities of the independent features.
5. Test: Calculate the error rate.
6. Use: One common application of naïve Bayes is document classification. You can use naïve Bayes in any classification setting. It doesn’t have to be text.
4.5 Classifying text with Python
- First, we’re going to show how to transform lists of text into a vector of numbers.
- Next, we’ll show how to calculate conditional probabilities from these vectors.
- Then, we’ll create a classifier,
- and finally, we’ll look at some practical considerations for implementing naïve Bayes in Python.
4.5.1 Prepare:making word vectors from text.
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not return postingList,classVec
return postingList,classVec
def createVocabList(dataSet):
vocabSet = set([]) #Create an empty set
for document in dataSet:
vocabSet = vocabSet | set(document) # Create the union of two sets
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList) #Create a vector of all 0s
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print("the word: %s is not in my Vocabulary!" % word)
return returnVec
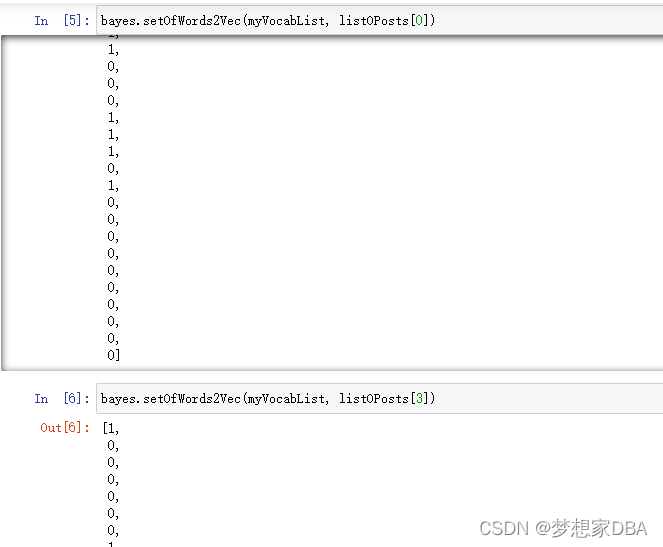
import bayes
listOPosts,listClasses = bayes.loadDataSet()
myVocabList = bayes.createVocabList(listOPosts)
myVocabList
bayes.setOfWords2Vec(myVocabList, listOPosts[0])
bayes.setOfWords2Vec(myVocabList, listOPosts[3])
4.5.2 Train:calculating probabilities from word vectors


# Naive Bayes classifier training function
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = zeros(numWords);p1Num = zeros(numWords) #Initialize probabilities
p0Denom = 0.0 ; p1Denom = 0.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i]) #Vector addition
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom # change to log()
p0Vect = p0Num/p0Denom # change to log()
return p0Vect,p1Vect,pAbusive # Element-wise divisionopen your Python shell and enter the following:
import bayes
from numpy import *
import imp
imp.reload(bayes)
listOPosts,listClasses = bayes.loadDataSet()
myVocabList = bayes.createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(bayes.setOfWords2Vec(myVocabList,postinDoc))
p0V,p1V,pAb=bayes.trainNB0(trainMat,listClasses)
pAb
p0V
p1VDisplay:
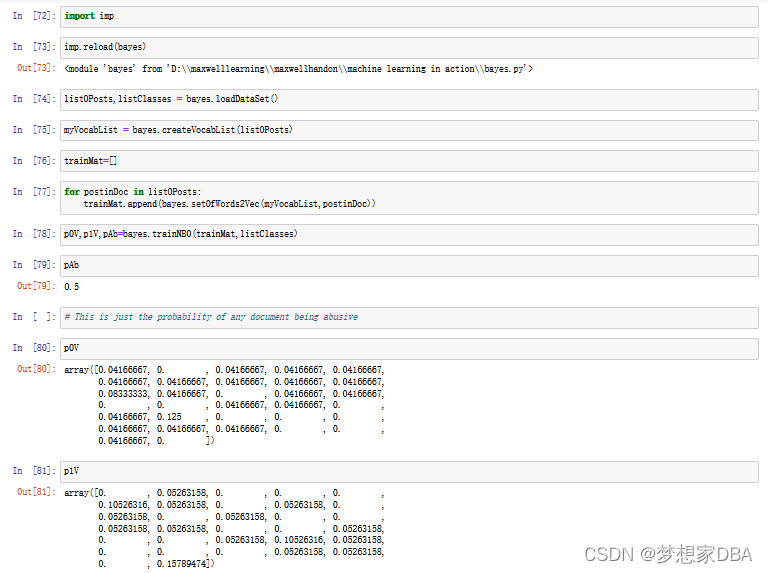
First, you found the probability that a document was abusive: pAb; this is 0.5, which is correct. Next, you found the probabilities of the words from our vocabulary given the document class.
4.5.3 Test:modifying the classifier for real-world conditions
# Naive Bayes classifier training function
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = ones(numWords);p1Num = ones(numWords) #Initialize probabilities
p0Denom = 2.0 ; p1Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i]) #Vector addition
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom) # change to log()
p0Vect = log(p0Num/p0Denom) # change to log()
return p0Vect,p1Vect,pAbusive # Element-wise division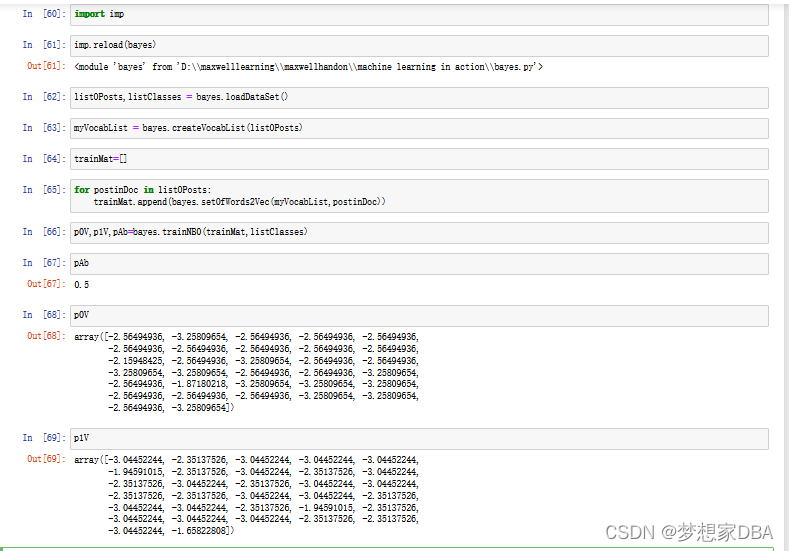
# Naive Bayes classify function
def classifyNB(vec2Classify,p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) # Elment-wise multiplication
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat = []
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(setOfWords2Vec(myVocabList,testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testEntry = ['stupid','garbage']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))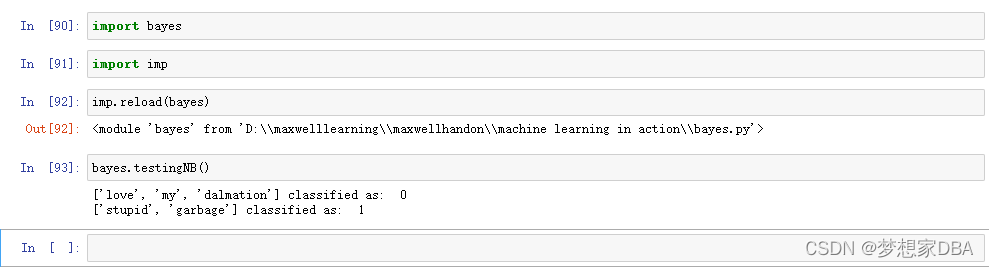
import bayes
import imp
imp.reload(bayes)
bayes.testingNB()4.5.4 Prepare: the bag-of-words document model
If a word appears more than once in a document, that might convey some sort of information about the document over just the word occurring in the document or not. This approach is known as a bag-of-words model. A bag of words can have multiple occurrences of each word, whereas a set of words can have only one occurrence of each word. To accommodate for this we need to slightly change the function setOfWords2Vec() and call it bagOfWords2VecMN().
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec4.6 Example:classifying spam email with naive Bayes
Example: using naïve Bayes to classify email
1. Collect: Text files provided.
2. Prepare: Parse text into token vectors.
3. Analyze: Inspect the tokens to make sure parsing was done correctly.
4. Train: Use trainNB0() that we created earlier.
5. Test: Use classifyNB() and create a new testing function to calculate the error rate over a set of documents.
6. Use: Build a complete program that will classify a group of documents and print misclassified documents to the screen.
4.6.1 Prepare tokening text
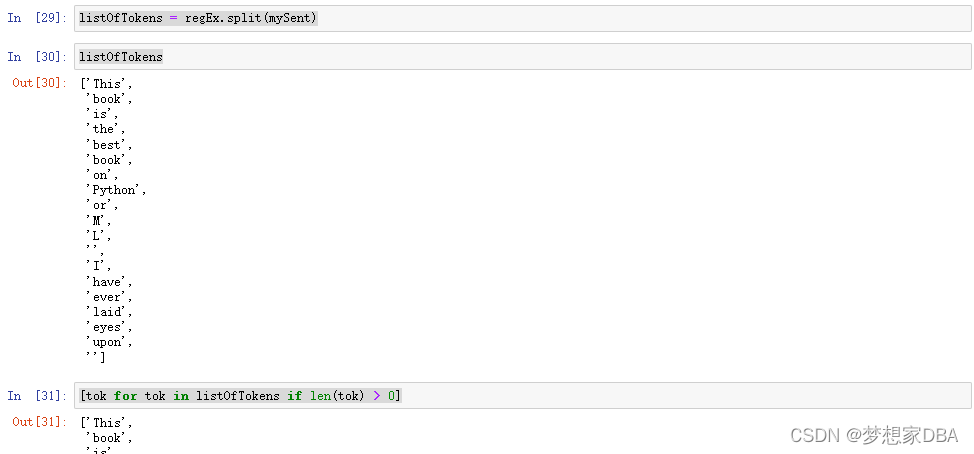
mySent='This book is the best book on Python or M.L. I have ever laid eyes upon.'
mySent.split()
import re
regEx = re.compile('\\W')
listOfTokens = regEx.split(mySent)
listOfTokens
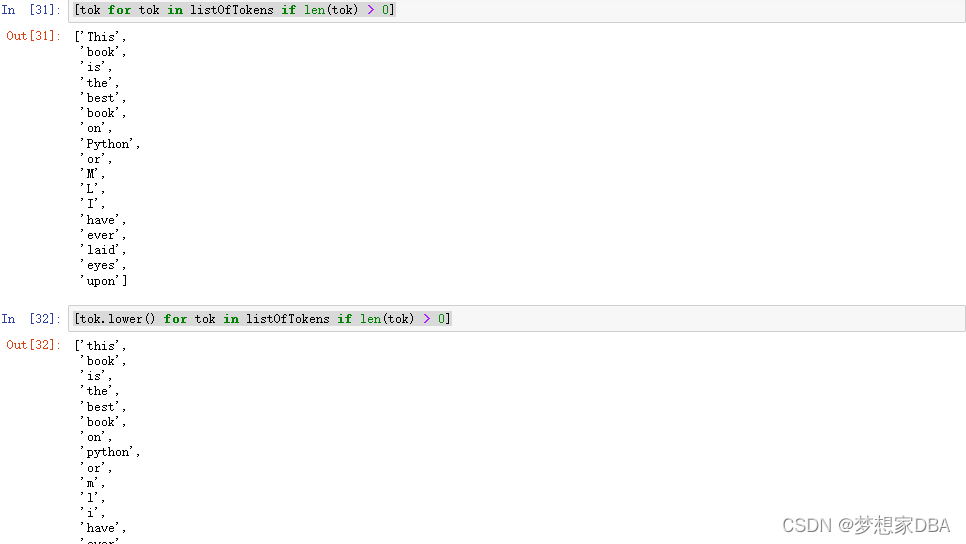
[tok for tok in listOfTokens if len(tok) > 0]
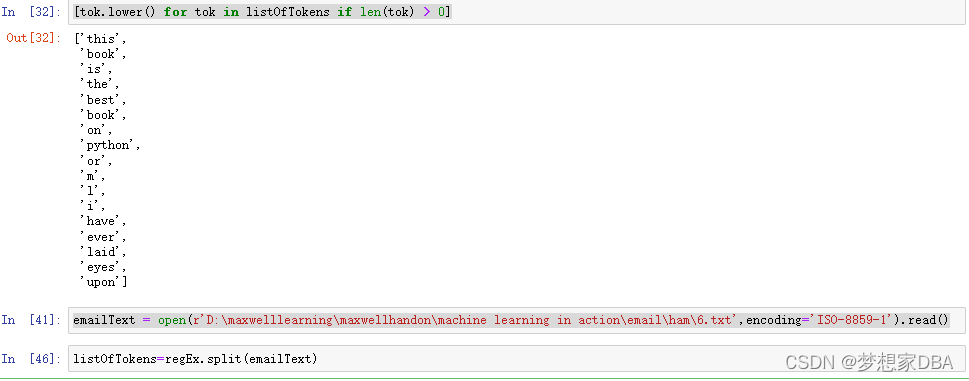
[tok.lower() for tok in listOfTokens if len(tok) > 0]
emailText = open(r'D:\maxwelllearning\maxwellhandon\machine learning in action\email\ham\6.txt',encoding='ISO-8859-1').read()
listOfTokens=regEx.split(emailText)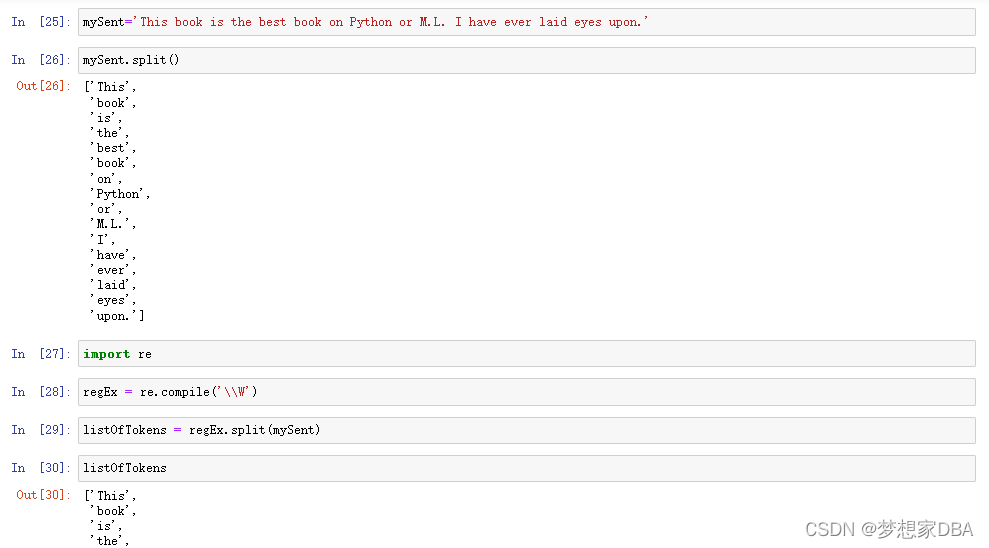
 4.6.2 Test:cross validation with naive Bayes
4.6.2 Test:cross validation with naive Bayes
Let's input this text parser to work with a whole classifier.Open your text editor and add the code from this listing to bayes.py.
# File parsing and full spam test functions
import numpy as np
def spamTest():
docList = []; classList = []; fullText = []
for i in range(1, 26):
# Load and parse text files
wordList = textParse(open('email/spam/%d.txt' % i, encoding="ISO-8859-1").read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(1)
wordList = textParse(open('email/ham/%d.txt' % i, encoding="ISO-8859-1").read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
vocabList = createVocabList(docList)#create vocabulary
trainingSet = range(50); testSet = [] #create test set
for i in range(10):
# Randomly create the training set
randIndex = int(np.random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(list(trainingSet)[randIndex])
trainMat = []; trainClasses = []
for docIndex in trainingSet:#train the classifier (get probs) trainNB0
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses))
errorCount = 0
for docIndex in testSet: #classify the remaining items
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
errorCount += 1
print("classification error", docList[docIndex])
print('the error rate is: ', float(errorCount)/len(testSet))
#return vocabList, fullTextEnter the following into your Python shell:
import bayes
import imp
imp.reload(bayes)
bayes.spamTest()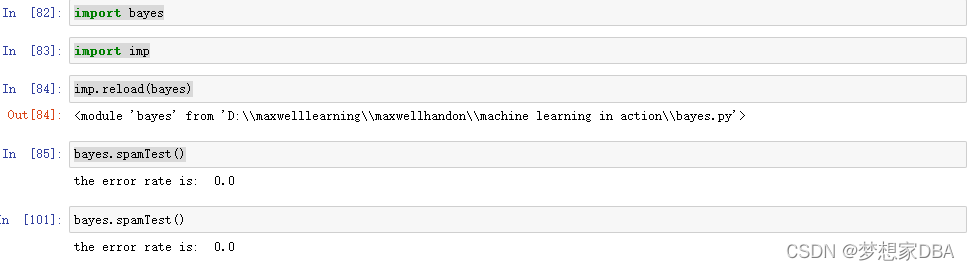
The error that keeps appearing is a piece of spam that was misclassified as ham.
4.7 Example:using naive Bayes to reveal local attitudes from personal ads
Example: using naïve Bayes to find locally used words
1. Collect: Collect from RSS feeds. We’ll need to build an interface to the RSS feeds.
2. Prepare: Parse text into token vectors.
3. Analyze: Inspect the tokens to make sure parsing was done correctly.
4. Train: Use trainNB0() that we created earlier.
5. Test: We’ll look at the error rate to make sure this is actually working. We can make modifications to the tokenizer to improve the error rate and results.
6. Use: We’ll build a complete program to wrap everything together. It will display the most common words given in two RSS feeds.
4.7.1 Collect:importing RSS feeds
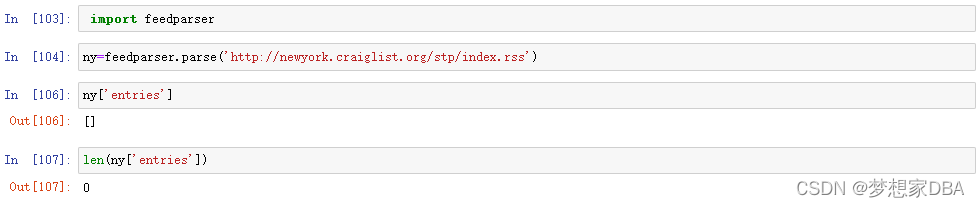
# RSS feed classifier and frequent word removal functions
def calcMostFreq(vocabList, fullText):
import operator
freqDict = {}
for token in vocabList:
freqDict[token] = fullText.count(token)
sortedFreq = sorted(freqDict.items(), key=operator.itemgetter(1), reverse=True)
return sortedFreq[:30]
def localWords(feed1, feed0):
import feedparser
docList = []; classList = []; fullText = []
minLen = min(len(feed1['entries']), len(feed0['entries']))
for i in range(minLen):
wordList = textParse(feed1['entries'][i]['summary'])
docList.append(wordList)
fullText.extend(wordList)
classList.append(1) #NY is class 1
wordList = textParse(feed0['entries'][i]['summary'])
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
vocabList = createVocabList(docList)#create vocabulary
top30Words = calcMostFreq(vocabList, fullText) #remove top 30 words
for pairW in top30Words:
if pairW[0] in vocabList: vocabList.remove(pairW[0])
trainingSet = range(2*minLen); testSet = [] #create test set
for i in range(20):
randIndex = int(np.random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(list(trainingSet)[randIndex])
trainMat = []; trainClasses = []
for docIndex in trainingSet:#train the classifier (get probs) trainNB0
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses))
errorCount = 0
for docIndex in testSet: #classify the remaining items
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
errorCount += 1
print('the error rate is: ', float(errorCount)/len(testSet))
return vocabList, p0V, p1V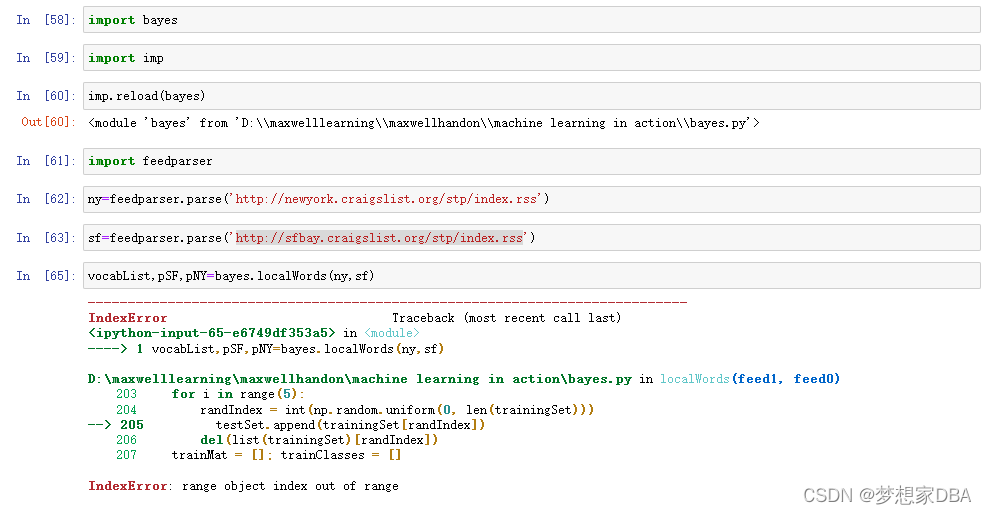
针对上面的这个
IndexError: range object index out of range
看源码里怎么都不会溢出啊,除非minLen为0;所以看了下测试集中的两个链接,第一个链接打开后是正常的,第二个打不开了,所以问题就出在这里了,minLen确实等于0了,怎么修改呢?只好把挂掉的链接换一个新的,我换的是参考资料:
《机器学习实战》中贝叶斯分类中导入RSS源例子 - 机智大脸喵 - 博客园
里的。而且这个里面还提到了20个测试集会有点多,一测试,果然,报错:
IndexError: list index out of range
20改成10,再测一下,还报错:
IndexError: index 0 is out of bounds for axis 0 with size 0
好吧,看来只好改成5了,再测试,正确。
因为测试集太少,我的错误率为0,额,主要学的是算法,结果不重要。
4.7.2 Analyze:displaying locally used words
# Most descriptive word display function
def getTopWords(ny, sf):
import operator
vocabList, p0V, p1V = localWords(ny, sf)
topNY = []; topSF = []
for i in range(len(p0V)):
if p0V[i] > -6.0: topSF.append((vocabList[i], p0V[i]))
if p1V[i] > -6.0: topNY.append((vocabList[i], p1V[i]))
sortedSF = sorted(topSF, key=lambda pair: pair[1], reverse=True)
print("SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**")
for item in sortedSF:
print(item[0])
sortedNY = sorted(topNY, key=lambda pair: pair[1], reverse=True)
print("NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**")
for item in sortedNY:
print(item[0])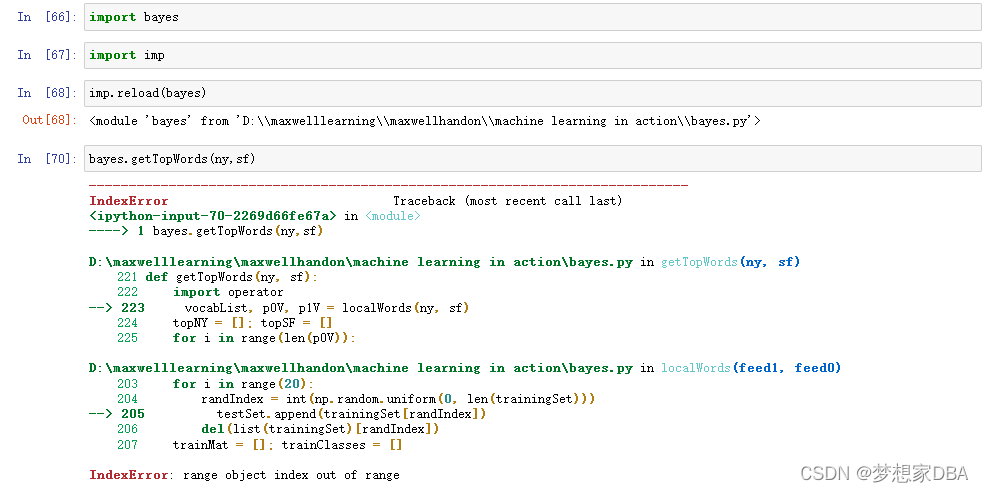
以上报错归结于上面的原因。
4.8 Summary
Using probabilities can sometimes be more effective than using hard rules for classification.Bayesian probability and Bayes's rule gives us a way to estimate unknown probabilities from known values.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









