







本节开始我们将为操作系统添加一些通用的组件,以方便其他模块编程时使用。
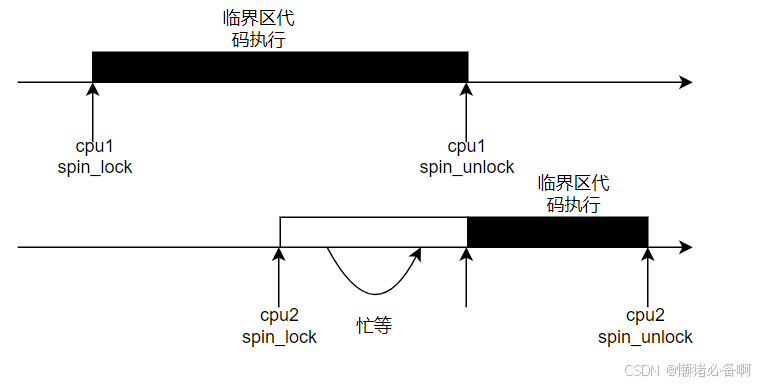
到目前为止,我们所有的代码都运行在一个CPU上,其他的CPU都在一个忙等的状态。本节我们将添加一个SMP(Symmetric Multi Processing)系统上必须用到的组件,自旋锁。
当多个CPU都需要进行同一资源操作,且此过程必须保持原子性,我们称这段操作为临界区,当处于临界区时,仅有一个CPU可以对此资源进行修改。互斥锁和自旋锁都能解决这个问题,他们的不同点在于互斥锁会让任务进入休眠状态,会发生任务切换。而自旋锁则让CPU处于一个忙等的状态,不会发生任务的切换。所以被自旋锁保护的代码必须要保证时效性,以保证不会让其他的CPU陷入长时间忙等,而不能处理其他任务。
自旋锁实现方法
CAS(Compare And Swap)
CAS实现的自旋锁是最简单的一种方式,他的结构定义只有一个变量表示该锁是否可用。当CPU拿锁时,会将这个变量的值与期望值1做比较,如果相等则将该变量的值设置为0。
优点:实现和使用快速。
缺点:1)没有公平性。2)多竞争者时,硬件在进行CAS时需要保持缓存等的一致性。开销比较大。
CAS实现的自旋锁类似于下边的代码(此处只用来表达原理)。
int cas(int *p, int exp, int set)
{
if (*p == exp) {
*p = set;
} else {
/* do nothing */
}
return set;
}
void spin_lock(spin_t *spin)
{
whlie(!cas(&spin->lock, 1, 0));
}MCS Lock
MCS是三个人名的简写(John M. Mellor-Crummey and Michael L. Scott)。MCS lock主要是增加了一个链表对竞争者进行管理,每多一个竞争者,链表中就会多一个元素。而且每个CPU都去比较自己的locked值(CPU现需要查询自己本地的cache line),因此规避了CAS中硬件做cache同步的问题,大大提高了效率。
MSC定义的数据结构如下:
struct mcs_spinlock {
struct mcs_spinlock *next; //指向下一个拿锁的mcs
int locked; /* 1 if lock acquired */ //锁的数值,1表示拿到了
int count; /* nesting count, see qspinlock.c */ //嵌套的层数
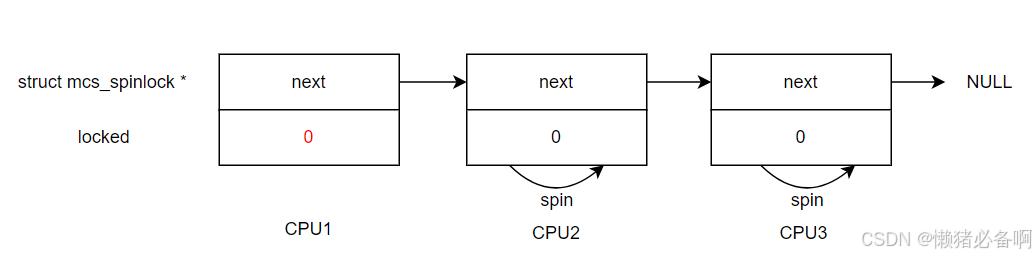
};当存在多核竞争自旋锁时,数据结构的状态如下:
仔细观察可以发现,CPU1是个持锁的状态,为什么locked变量的数值是0呢?是因为CPU1拿到锁时并没有别的CPU正在持锁,可以直接拿到,并不需要关注locked变量,因此只需要将next设置为自己即可。
当CPU1将锁释放后,会将CPU2的MCS结构中的locked变量设置为1,这样就会将自旋锁传递给CPU2,CPU3此时还是继续等在自己的locked变量。
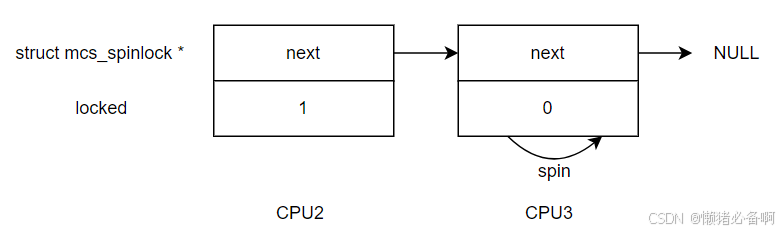
MCS的缺点是他定义了一个指针,相较于其他lock会占用更多的空间。接下来介绍的一种机制优化了这个问题。
Qspinlock
Qspinlock是对MCS lock的改进版本,主要是对MCS的数据结构进行优化,将原先的信息优化优化到一个4字节的结构中。
qspinlock的数据结构如下,我们可以看到使用的是一个联合体,因此内存空间仅仅占用atomic_t大小的空间,通常是int的大小。
typedef struct qspinlock {
union {
atomic_t val;
/*
* By using the whole 2nd least significant byte for the
* pending bit, we can allow better optimization of the lock
* acquisition for the pending bit holder.
*/
struct {
u8 locked;
u8 pending;
};
struct {
u16 locked_pending;
u16 tail;
};
};
} arch_spinlock_t;qspinlock中数据结构的占用通常是这样的(根据CPU数量不同还有另外一种结构,原理相同,这里不做赘述):

* When NR_CPUS < 16K
* 0- 7: locked byte 表示锁的数值
* 8: pending 用于表示我CPU正在等,优先获得自旋锁
* 9-15: not used
* 16-17: tail index 用于对应linux中的4种上下文(task,softirq,hardirq,nmi)
* 18-31: tail cpu (+1) CPU编号+1用于获取MCS的node
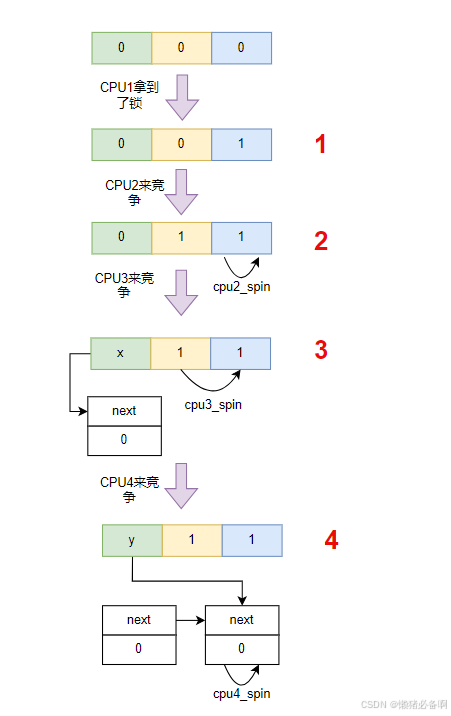
linux里在介绍锁的状态变化时将val分成了三个部分,分别是lock val,pending, queue tail,此三个部分组成一个数组,初始状态时表示为(0,0,0)。

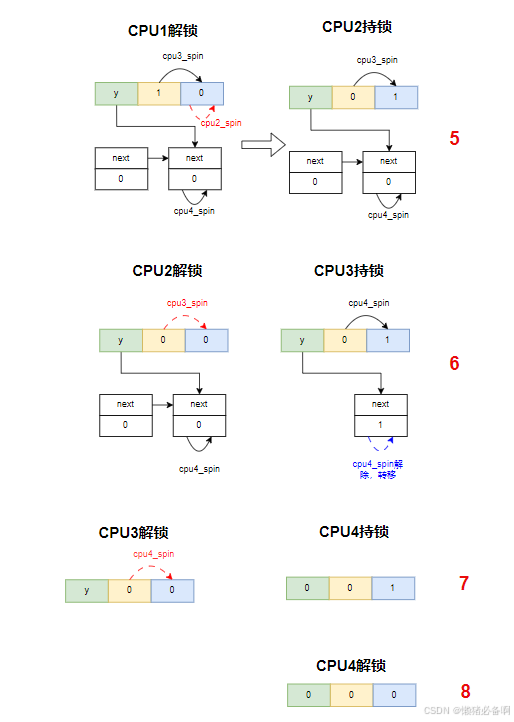
1)当CPU1尝试拿锁时,会直接检测val,val等于0时,直接拿到锁,数值变化为(0,0,1)。
2)当CPU2再来拿锁时,检测到val值是1,说明不能拿锁,此时会将pending位置设置为1,表示我在等。数值变化为(0,1, 1),他spin的对象时lock val。
3)当CPU3再来拿锁时,检测到val不等于1,证明前边超过2个人想使用锁,这个时候就需要MCS出场了,会创建MCS的node,同时将NEXT指向自己,他spin的对象是lock val和pending。数值变化为(x, 1, 1)。
4)当CPU4再来拿锁时,会再创建一个mcs 的node。他spin的对象是自己节点中的lock变量。数值变化为(y, 1, 1)。
5)当CPU1释放锁时,将qspinlock中的lock val设置为0,数值变化为(y,,1, 0)。此时CPU2将结束spin,获得锁。数值变化为(y,0,1)。
6)当CPU2释放锁时,将qspinlock中的lock val设置为0,数值变化为(y,0,0)。此时CPU3将结束spin,获得锁。并将lock val设置为1,数值变化为(y,0, 1)。同时将next node中的lock变量设置为1,让CPU4结束spin,继续往下走,CPU4将重新spin到lock val和pending。
7)当CPU3释放锁时,将spinlock中的lock val设置为0,数值变化为(y,0,0)。此时CPU4再次结束spin,获得锁,由于现在现在只剩下自己了,所以会将tail值设置为0,同时将lock val设置为1,数值变换为(0, 0, 1)。
8)CPU4释放锁时,数值变化为(0, 0, 0)。重新回到无人持锁状态。
代码porting
本节代码直接porting linux的qspinlock。在此基础上实现spinlock。
代码下载和运行
由于我们还没有启动多核,所以本节的测试用例无法运行。我们暂时在一个核上自嗨一下吧。
git clone https://gitee.com/genglufei/hfos.git
cd hfos/day6_spinlock/hfOS/vendor
./build_hfos.sh qemu_a57
./run_hfos.sh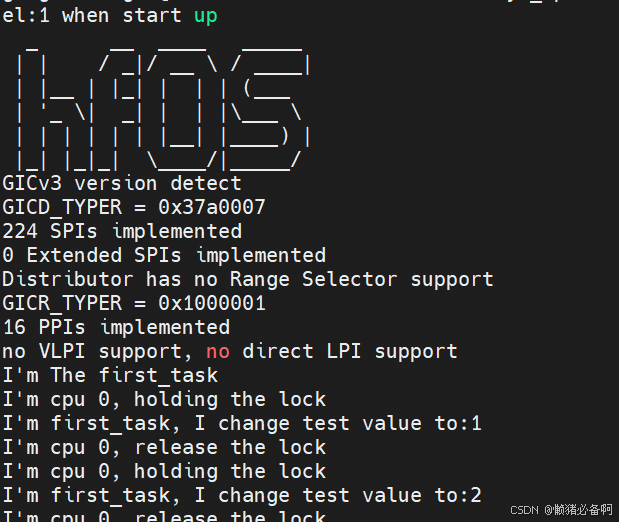
下一节我们将启动多核,并改为多核参与调度。同时运行一下我们spinlock的测试,看一下理解的spinlock流程是否正确。

















 4465
4465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









