









下面是基于MatConvNet框架的vl_nnloss中类别标签到索引的转换的代码实现:
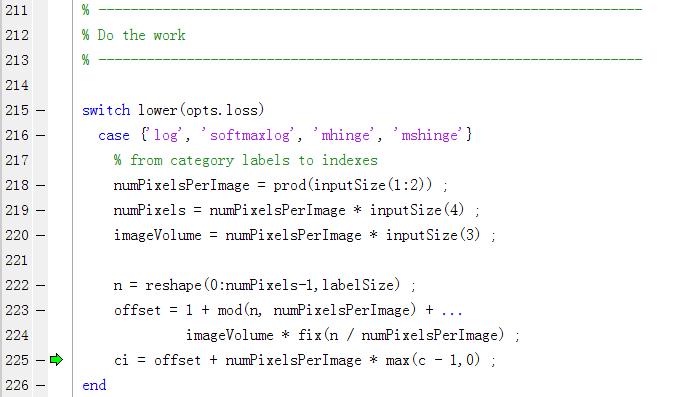
在上述代码中,
Line 218 表示获取每个通道的像素数,inputSize(1:2)表示获取每个通道的 Feature Map或Score Map的Size(height and width)大小;
Line 219 表示获取一个batch的像素个数,其中inputSize(4)表示batch大小;
Line 220 表示获取所有通道总的像素数,其中inputSize(3)表示通道数(channel);
Line 222 表示把一个batch的像素数的索引表示成 labelSize,其中
labelSize = [size(c,1) size(c,2) size(c,3) size(c,4)] ; 其中c表示类别标签,是个四维的张量;
inputSize = [size(x,1) size(x,2) size(x,3) size(x,4)] ; 其中x表示the prediction scores x given the categorical labels c;
Line 223 的结果按理论推测,当inputSize(4)=1,也就是当batch或SubBatch等于1时,可以直接在Line 222一步完成,即:
offset = reshape(1:numPixels, labelSize) ;
示例:
A = randn(16,16,3);
B= reshape(1:256, [16 16]);
则:
C = A(B)即获取A(:,:,1)。
B = B + 256*ones(16,16),则C=A(B)即获取A(:,:,2)。
如果inputSize(4)不等于1,则如Line 223所示;此时:
n = reshape(0:numPixels-1,labelSize) ;
offset_pre = 1 + mod(n, numPixelsPerImage);
是为了把offset均clip在1:numPixelsPerImage之间,并且offset_pre(:, :, :, 1), ..., offset_pre(:, :, :, batch)均相等,然后利用
fix(n / numPixelsPerImage)定位inputSize(4),也就是batch中哪一张图片,而一个batch中的一张图片对应的总像素数为
imageVolume = numPixelsPerImage * inputSize(3) ;
故 Line 225可以索引到一个batch中一张图片的每个通道的Feature Map或Score Map的Spatial Location,此矩阵化操作避免了循环定位Spatial Location,加快了运行速度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









