






 本文深入解析MapReduce工作流程,从InputFormat解码数据到Map处理业务逻辑,再到Combiner局部汇总,Partitioner分配数据,Shuffle传送过程,直至Reducer汇总结果。探讨InputSplit分片原理,以及如何通过调整参数控制Mapper数量。
本文深入解析MapReduce工作流程,从InputFormat解码数据到Map处理业务逻辑,再到Combiner局部汇总,Partitioner分配数据,Shuffle传送过程,直至Reducer汇总结果。探讨InputSplit分片原理,以及如何通过调整参数控制Mapper数量。
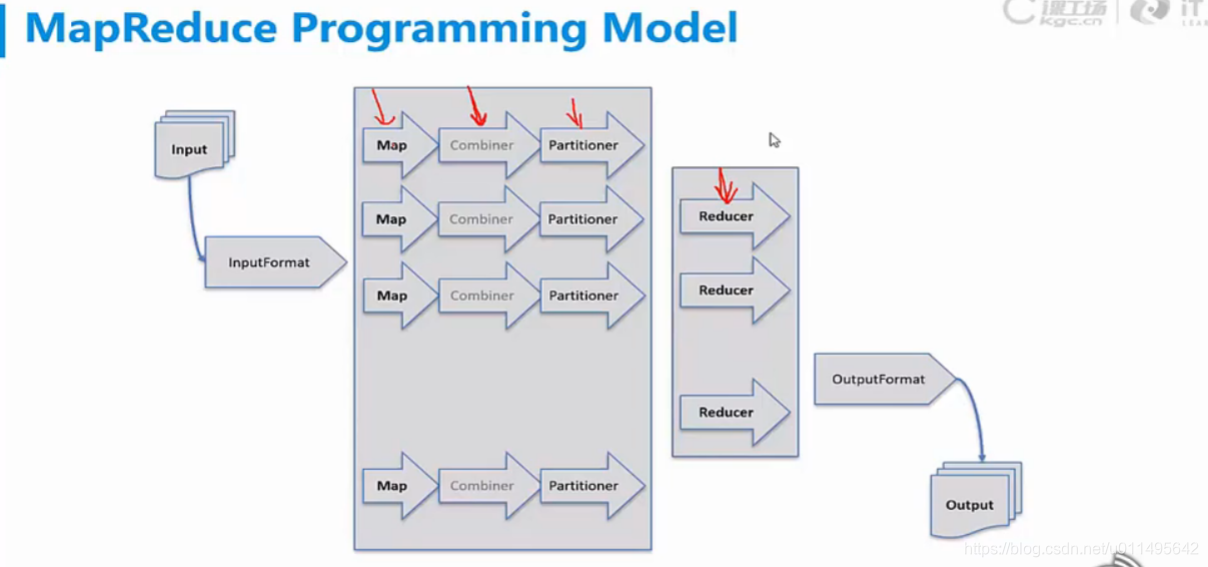
Input就是数据
数据以key-value形式进来之后,我们需要一个解码器InputFormat,它是用来计算有多少个逻辑块以及我怎么读取这些内容。
然后就是Map过程,Map就是我们处理业务数据的过程,比如说WordCount,那我们就对每个单词计数。
然后是combiner是局部汇总,也就是把本机上的结果先汇总,减轻Reducer的压力。但这步不是必须的。
再往下就是Partitioner,它就是一个计算我哪块数据要往哪个Reducer上发,一般默认对key算出一个哈希值,再对Reducer机器的数量取模,就知道发到哪台机器了。
shuffle就是实际传送的过程。
Reducer负责汇总所有机器传来的结果,有几个Reducer最后就有几个输出文件,所以我们还需要一个加码器。解码就是这个内容,我告诉你怎么读,我不告诉你你不知道。而加码器就是我来制定我自己读文件的规则。
————————————————————————————————
重要概念:
1. Input Split(输入分片):
在执行map计算之前,要根据input进行分片。
每一个Input split对应一个map任务(可以看图),而且Input split存的不是数据块,
存的是一个分片长度和记录了数据位置的数组。

如何控制Mapper的个数:
这里先贴一下,我觉得这得动手才能了解。
(1)默认map个数
如果不进行任何设置,默认的map个数是和blcok_size相关的。
default_num = total_size / block_size;
(2)期望大小
可以通过参数mapred.map.tasks来设置程序员期望的map个数,但是这个个数只有在大于default_num的时候,才会生效。
goal_num = mapred.map.tasks;
--------------------- 经过以上的分析,在设置map个数的时候,可以简单的总结为以下几点:
(1)如果想增加map个数,则设置mapred.map.tasks 为一个较大的值。
(2)如果想减小map个数,则设置mapred.min.split.size 为一个较大的值。
(3)如果输入中有很多小文件,依然想减少map个数,则需要将小文件merger为大文件,然后使用准则2。
---------------------

















 5125
5125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









