









适合Spark SQL和Spark Structured Streaming
直接上代码
SparkSession spark = SparkSession
.builder()
.appName("spark-job")
.getOrCreate();
RuntimeConfig conf = spark.conf();
// text compress
conf.set("mapreduce.output.fileoutputformat.compress", "true");
conf.set("mapreduce.output.fileoutputformat.compress.type", SequenceFile.CompressionType.BLOCK.toString());
conf.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.GzipCodec");
conf.set("mapreduce.map.output.compress", "true");
conf.set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.GzipCodec");
spark
.read()
.parquet("hdfs://aaaa")
.select("abc")
.write()
.format("text")
.mode(SaveMode.Overwrite)
.save("hdfs://bbbb");
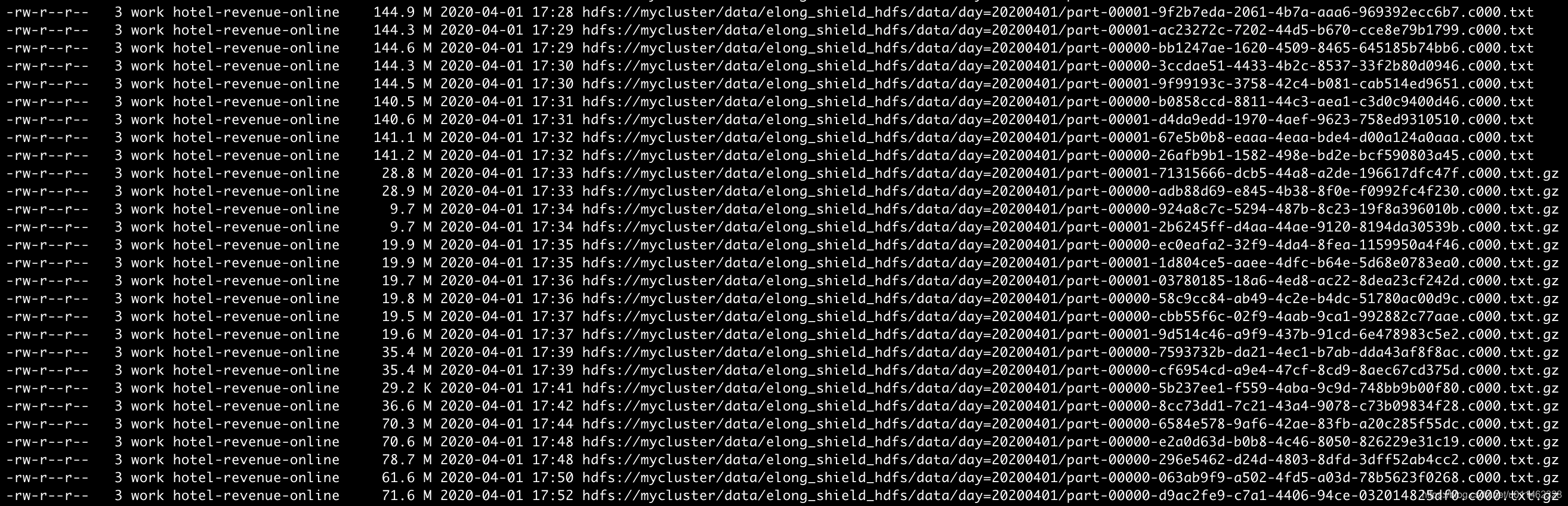
压缩后的数据是以.gz结尾

















 109
109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









