







通常,链表数据结构至少应包含两个域:数据域和指针域,数据域用于存储数据,针域用于建立与下一个节点的联系。但在Linux内核链表中,不是在链表结构中包含数据,而是在各种特定数据结构中包含链表节点。在linux中许多大规模的数据就是通过内嵌链表,将数据很好的组织起来的,给遍历,查询的相关处理提供了方便。
内核链表的结构是个双向循环链表,只有指针域,数据域根据使用链表的人的具体需求而定。内核链表设计哲学:
既然链表不能包含万事万物,那么就让万事万物来包含链表。
首先先解析两个宏,内核链表里面大量用到了这两个宏offsetof 和 container_of。
一、offset_of
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)1.1、作用
给定一个结构体类型 TYPE 和其成员 MEMBER,获取结构体成员相对于结构体起始位置的偏移量。
1.2、解析
参数 (TYPE, MEMBER):
TYPE 是要计算偏移量的结构体的类型。
MEMBER 是这个结构体中的一个成员。
类型转换 ((TYPE *)0):
(TYPE *)0 将地址0强制转换为指向结构体 TYPE 的指针。这并不会真正访问该地址,因为我们只不过是想利用指针运算的特性来计算偏移量,而不是实际访问。
成员访问 (->MEMBER):
((TYPE *)0)->MEMBER 意味着我们以类型为 TYPE 的结构体对象来访问 MEMBER。在这里,0地址被用作基地址,通过指针指向该结构体的假设位置。
取地址 (&):
&操作符用于获取 MEMBER 的地址。因为基础地址是0,所以这里的地址实际上就是成员在结构体中的偏移量。
转换为size_t:
将最后的结果显式转换为 size_t 类型,以确保结果是一个无符号整数,通常用于表示内存大小或偏移量。
二、container_of
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})2.1、作用
用于从指向结构体成员的指针获取指向包含该成员的结构体的指针。
2.2、解析
宏定义:
#define container_of(ptr, type, member)此宏定义使用了三个参数:
ptr: 指向某个结构体成员的指针,对应成员变量 member。
type: 包含该成员的结构体类型。
member: 在结构体中的成员变量,对应指针 ptr。
类型推断:
const typeof( ((type *)0)->member ) *__mptr = (ptr);typeof:这一语法用于推断指定表达式的类型,在这里它推断的是成员变量member的类型。
((type *)0)->member:这一句和我们之前的offset_of类似,通过将0转换为结构体类型的指针并获取成员,实际上不会访问位置0,而是用于获取该成员的类型。
__mptr:是一个const类型的指针,指向member成员类型,用于确保ptr与成员类型一致。
计算结构体起始地址:
(type *)((char *)__mptr - offset_of(type, member));(char *)__mptr:将__mptr(即ptr)转换为char*,这样可以进行字节级的指针运算。
offset_of(type, member):计算成员在结构体中的偏移量。见之前对offset_of的解释,该宏通过指针运算实现。
((char *)__mptr - offset_of(type, member)):通过从ptr中减去成员相对于结构体的偏移,得到整个结构体在内存中的起始地址。
(type *):把计算得到的地址转换为type结构体类型的指针,得到指向整个结构体的指针。
总结
offset_of:对于给定的一个结构的成员,获取其成员相对于首地址的偏移。
container_of:对于给定结构成员的地址,返回其结构体指针(所有者)首地址。
三、list_head
struct list_head {
struct list_head *next, *prev;
};要了解内核链表,就不得不提 list_head。这个结构很有意思,整个结构没有数据域,只有两个指针域。
链表初始化
内核提供两种方式来初始化链表:宏初始化和接口初始化。
3.1 宏初始化
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)LIST_HEAD_INIT 设计的很精妙,这个宏本身不包含任何数据类型,也就是说没有限定唯一的数据类型,这就使得整个链表足够灵活,具备通用性。
LIST_HEAD 这个宏定义了对于任意给定的结构指针,将前驱 (prev) 和后继 (next) 指针都指向自己,作为链表头指针。
宏初始化用一句话表示,如下:
struct list_head name = { &(name), &(name) }可见,结构体 name 的指针next、prev都指向自己。
3.2 接口初始化
/**
* INIT_LIST_HEAD - Initialize a list_head structure
* @list: list_head structure to be initialized.
*
* Initializes the list_head to point to itself. If it is a list header,
* the result is an empty list.
*/
static inline void INIT_LIST_HEAD(struct list_head *list)
{
WRITE_ONCE(list->next, list);
list->prev = list;
}接口操作就比较直接明了,和宏实现的意图一样,直接将链表头指针的前驱 (prev) 和后继 (next) 都指向自己。
创建一个链表头:

3.3 链表节点的创建
前面说了 list_head 只有指针域,没有数据域,如果只是这样就没有什么意义了。所以我们需要创建一个宿主结构,然后再再此结构包含 list 字段,宿主结构,也有其他字段(进程描述符,页面管理结构等都是采用这种方法创建链表的)。
创建链表的一个节点:
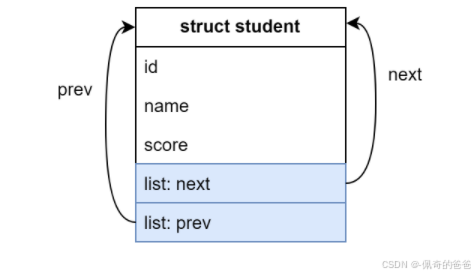
这里list 的prev 和next 都指向list 自己了,并且list 属于链表节点struct student的成员。只需要遍历到 list 节点就能根据前面讲的 container_of 推导得到其宿主结构的地址,从而访问 data 值。如果有其他方法,也可访问。
四、插入
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}内核链表提供了相应的添加节点的接口:list_add、list_add_tail。list_add 和 list_add_tail 最终调用的都是 __list_add 函数。list_add 是头部插入一个节点,list_add_tail 是尾部插入一个节点。
list_add 和 list_add_tail的区别是:
list_add 始终是在链表头后的的第一个位置进行插入:例如链表:head --> 数据1 --> 数据2 --> 数据3,插入新元素后:head --> new --> 数据1 --> 数据2 --> 数据3
list_add_tail 始终实在链表末尾插入新元素:例如链表:head --> 数据1 --> 数据2 --> 数据3,插入新元素后:head --> 数据1 --> 数据2 --> 数据3 --> new
仔细分析上述函数,可以发现其函数抽象的巧妙。
__list_add 接收三个参数:分别是new, prev, next。任何位置的双链表插入操作,只需这3个参数。那么new元素一定是在prev和next之间进行插入。
所以很明显:list_add是在head和head->next之间插入,那就是链表的第一个元素。
list_add_tail实在head->prev和head之间插入,那就是链表的最后一个元素。
4.1 list_add 示例如下
(1)创建一个链表头:g_stu_list
INIT_LIST_HEAD(&g_stu_list);
(2)再创建第一个链表节点
(3)把这个节点插入到list后
list_add(&p->list, &g_stu_list);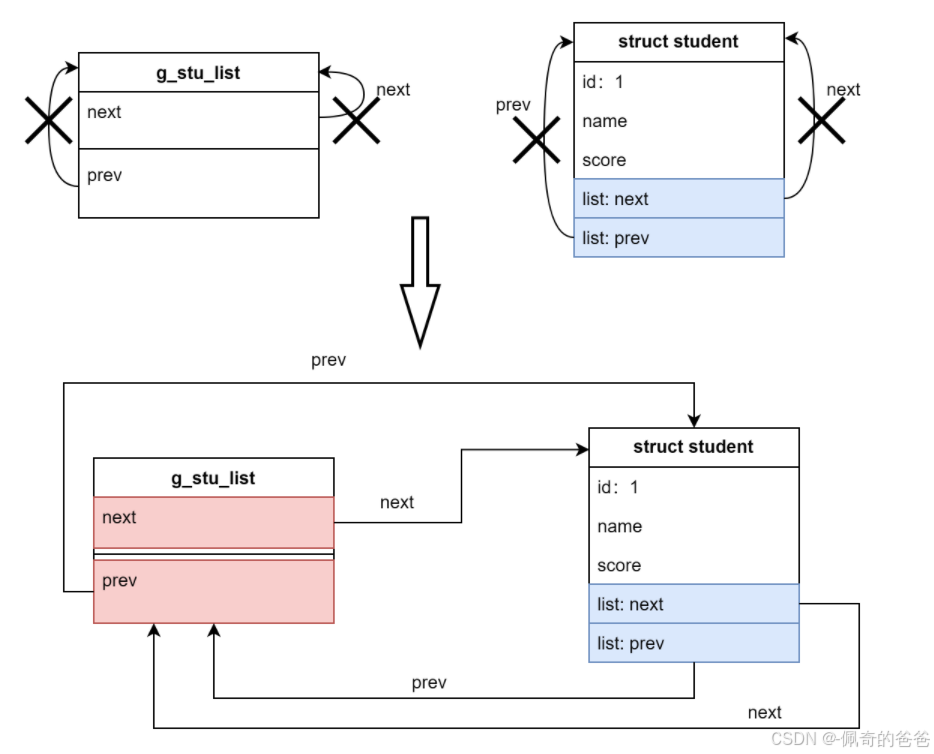
(4)再创建、插入第二个链表节点

以此类推,每次插入一个新节点,都是紧靠着 header 节点,而之前插入的节点依次排序靠后,那最后一个节点则是第一次插入 header 后的那个节点。先来的节点靠后,而后来的节点靠前。
使用示例:
#include "list.h"
struct student
{
int id;
char name[32];
unsigned int score;
struct list_head list;
};
struct list_head g_stu_list;
int main(int argc,char **argv)
{
int i;
struct student *p, *pstu;
struct list_head *pos;
char tmp[32] = { 0 };
INIT_LIST_HEAD(&g_stu_list);
for (i = 0; i < 5; i++) {
p = (struct student *)malloc(sizeof(struct student));
p->id = i;
memset(tmp, 0, sizeof(tmp));
snprintf(tmp, sizeof(tmp) - 1, "mt-0%d", i);
strcpy(p->name, tmp);
p->score = 90 + i;
printf("i: %d, id: %d, name: %s, score: %d, &list = %p\n", i, p->id, p->name, p->score, &p->list);
list_add(&p->list, &g_stu_list);
}
printf("\r\n");
printf("..............list_for_each start................\n");
list_for_each(pos, &g_stu_list) {
pstu = list_entry(pos, struct student, list);
printf("id: %d----name: %s----score: %d\n", pstu->id, pstu->name, pstu->score);
}
printf("..............list_for_each start................\n");
printf("\r\n");
return 0;
}
运行结果:
bjws210:~/Desktop/klist$ gcc -o test_list test_list.c
bjws210:~/Desktop/klist$ ./test_list
i: 0, id: 0, name: mt-00, score: 90, &list = 0x55795c9942c8
i: 1, id: 1, name: mt-01, score: 91, &list = 0x55795c994718
i: 2, id: 2, name: mt-02, score: 92, &list = 0x55795c994758
i: 3, id: 3, name: mt-03, score: 93, &list = 0x55795c994798
i: 4, id: 4, name: mt-04, score: 94, &list = 0x55795c9947d8
..............list_for_each start................
id: 4----name: mt-04----score: 94
id: 3----name: mt-03----score: 93
id: 2----name: mt-02----score: 92
id: 1----name: mt-01----score: 91
id: 0----name: mt-00----score: 90
..............list_for_each start................4.2 list_add_tail 的示例如下
(1)创建一个链表头:g_stu_list
INIT_LIST_HEAD(&g_stu_list);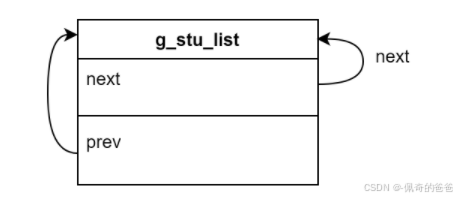
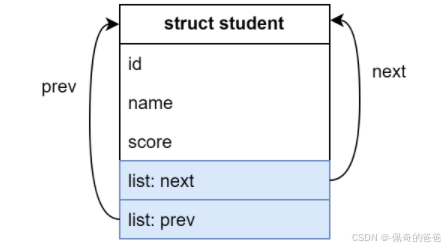
(2)再创建第一个链表节点
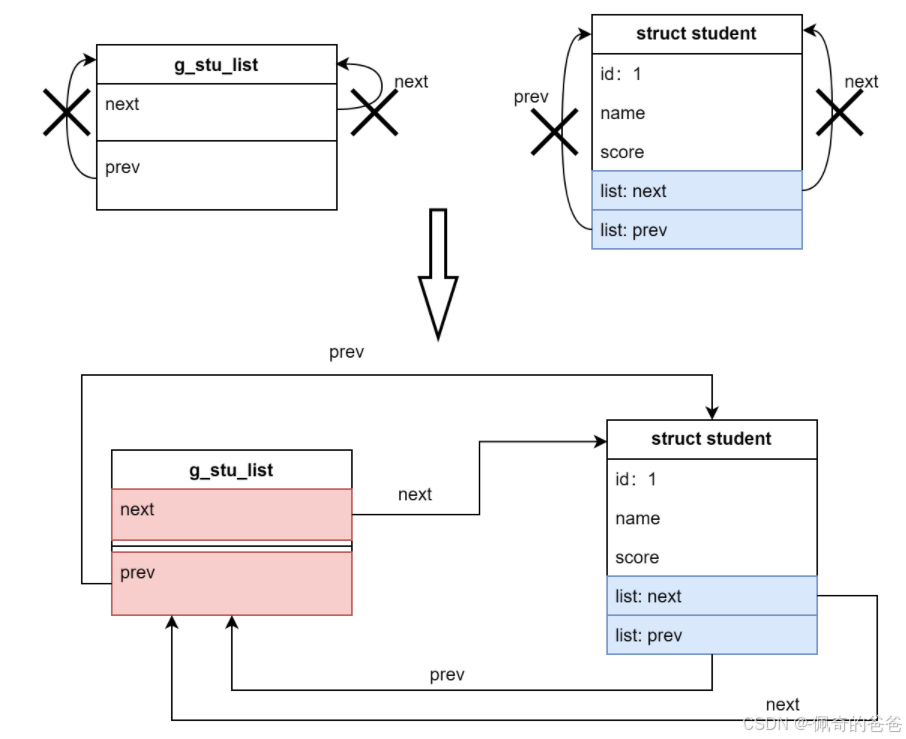
(3)尾部插入第一个节点
(4)尾部插入第二个节点
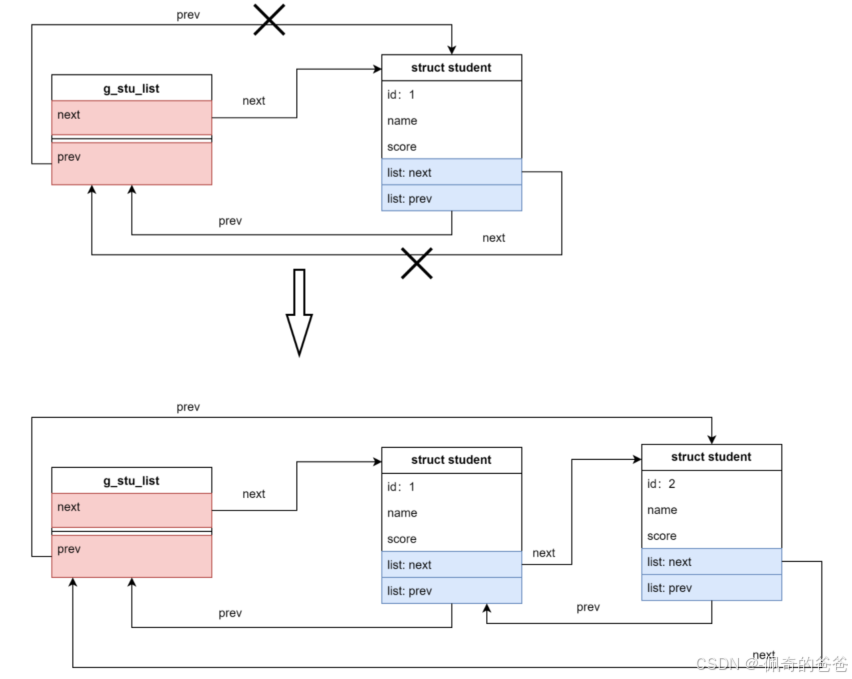
每次插入的新节点都是紧挨着 header 表尾,而插入的第一个节点排在了第一位,第二个排在了第二位。先插入的节点排在前面,后插入的节点排在后面。
使用示例:
#include "list.h"
struct student
{
int id;
char name[32];
unsigned int score;
struct list_head list;
};
struct list_head g_stu_list;
int main(int argc,char **argv)
{
int i;
struct student *p, *pstu;
struct list_head *pos;
char tmp[32] = { 0 };
INIT_LIST_HEAD(&g_stu_list);
for (i = 0; i < 5; i++) {
p = (struct student *)malloc(sizeof(struct student));
p->id = i;
memset(tmp, 0, sizeof(tmp));
snprintf(tmp, sizeof(tmp) - 1, "mt-0%d", i);
strcpy(p->name, tmp);
p->score = 90 + i;
printf("i: %d, id: %d, name: %s, score: %d, &list = %p\n", i, p->id, p->name, p->score, &p->list);
list_add_tail(&p->list, &g_stu_list);
}
printf("\r\n");
printf(& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









