







 本文探讨了为何在C/C++中设计序列化和反序列化操作的重要性,包括处理指针元素、跨平台存储问题及可读性,揭示了直接使用fwrite和fread的局限性。
本文探讨了为何在C/C++中设计序列化和反序列化操作的重要性,包括处理指针元素、跨平台存储问题及可读性,揭示了直接使用fwrite和fread的局限性。
1. 引言
思考这一问题的起源,在于看到leetcode中的一道题目297. Serialize and Deserialize Binary Tree。之前在学C/C++的时候,有这样的两个函数
// 读取文件块数据
size_t fread(void *buffer, size_t size, size_t count, FILE *file);
// 写入文件块数据
size_t fwrite(const void *buffer, size_t size, size_t count, FILE *file);
貌似这两个函数就可以实现一种“通用”的“序列化”和“反序列化”的操作:无论什么结构体,都以文件块的形式写入磁盘中(或者送入网络);无论什么结构体,在从磁盘中(或者网络中)读取到文件块之后,都以原始结构体的协议装载到内存中。那么还要特意设计序列化和反序列化的意义是什么呢?经过思考后,序列化和反序列化操作需要特定设计的原因,有3点:
- 结构体中含有指针元素
- 不同计算机上大端,小端存储问题以及数据结构所占字节问题
- 可读性问题
2. 原因细分析
2.1 结构体中含有指针元素
以tree为例子,结构体中含有left和right指针。
struct TreeNode{
int val;
TreeNode* left;
TreeNode* right;
}
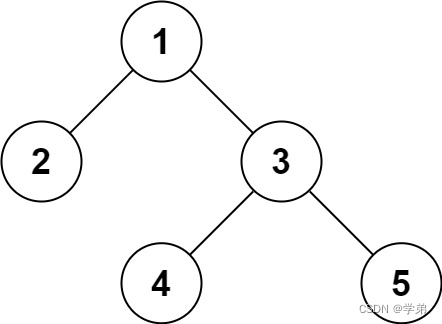
对于上图所示的tree,我们通常以head指代整个tree。如果通过fwrite将head保存为一个二进制文件tree.bin。在另外一台电脑上,fread该bin文件,仅仅能获得根节点1,其他子节点会“断掉”。序列化和反序列化的操作就可以解决该问题。
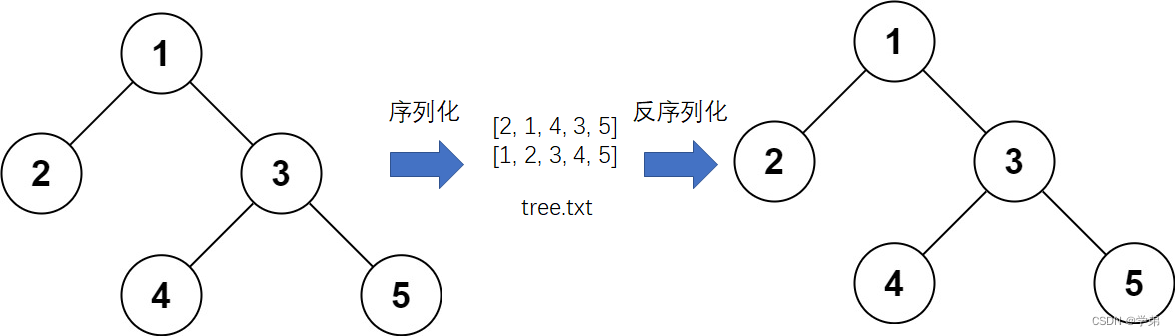
如果,我们将其序列化为一个txt,而这txt中的内容是该tree的中序遍历结果和前序遍历结果,就可以根据该txt在任意电脑上复原(反序列化)原始tree。
2.2 不同计算机上大端,小端存储问题以及数据结构所占字节问题
即使struct中不含有指针型数据成员,依旧可能会存在问题,如下所示一个普通的结构体。
struct A{
int age;
char height;
int weight;
}
如果通过fwrite的方式保存为A.bin。在另一台电脑上fread的时候依旧可能会出现问题。主要原因会涉及两方面:虽然大部分电脑上int占4个字节,但并不绝对,特殊情况下会是2或8?。另外一方面是编译器会对字节进行自动补齐的原因。上述两点原因会导致fread的时候出现混乱现象。
解决该问题的方法,同样可以通过设计序列化和反序列化操作来达到。例如序列化的时候就可以将该结构体,保存为A.txt形式:
18 180 75
反序列化,则是读取txt然后复原结构体。
2.3 可读性问题
最后一个原因就是可读性问题。序列化的结果一般可以方便的以人类能够接受的形式更好的阅读。
3. 总结
序列化操作看似费心,需要自己来设计。但一旦设计出来,代码的鲁棒性,序列化之后的可读性都会更优雅。反观直接的fwrite和fread这种“偷懒”的做法,则是一种比较“快糙猛”的做法,会有较多的隐患存在。


















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











