






导语 | Flink已经成为未来流计算趋势,目前在很多大厂已经有了大规模的使用。最近在学习Flink源码,就想把自己学习的过程分享出来,希望能帮助到志同道合的朋友。开始阅读源码,说明读者已经对flink的基本概念有一些了解,这里就不再重复介绍Flink了。本文作为学习过程的第一章,首先对Flink的工程目录做一个解读,了解了工程下各个模块的作用,才能在遇到问题时准确定位到代码,进一步学习。
一. Flink工程下的一级目录
用IDEA打开Flink的工程,可以看到图一所示的这些子工程目录,这一小节会简要介绍下各个模块的作用,其中像example和test的目录就跳过了,对于Flink比较重要的两个模块flink-runtime和flink-table会分别在第二节和第三节分别介绍。
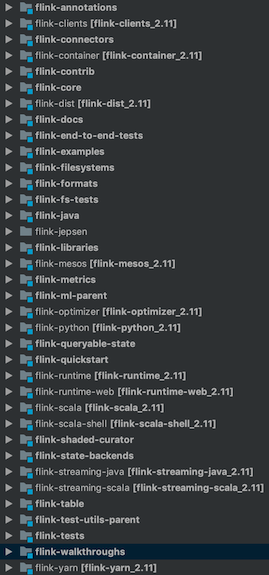
图一 Flink工程目录
- flink-annotations: Flink自定义的一些注解,用于配置、控制编译等功能。
- flink-clients: Flink客户端,用于向Flink集群提交任务、查询状态等。其中org.apache.flink.client.cli.CliFrontend就是执行./flink run的入口。
- flink-connectors: Flink连接器,相当于Flink读写外部系统的客户端。这些连接器指定了外部存储如何作为Flink的source或sink。例如对于kafka来说,flink-connector-kafka-xx定义了FlinkKafkaConsumer和FlinkKafkaProducer类分别作为Flink的source和sink,实现了对kafka消费和生产的功能。从图二可以看出,flink 1.9目前支持的外部存储有Cassandra、ES、Kafka、Hive等一些开源外部存储。
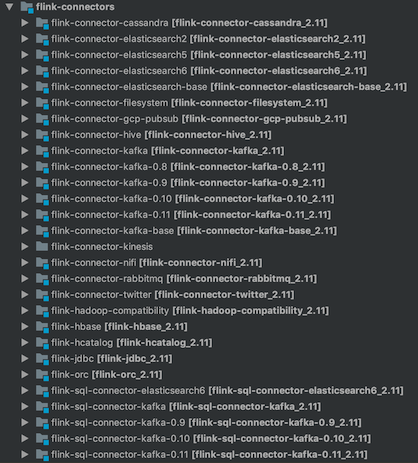
图二 Flink Connectors
- flink-container: Flink对docker和kubernetes的支持。
- flink-contrib: 社区开发者提供的一些新特性。
- flink-core: Flink核心的API、类型的定义,包括底层的算子、状态、时间的实现,是Flink最重要的部分。Flink内部的各种参数配置也都定义在这个模块的configuration中。(这部分代码还没怎么看过,就不细讲了)。
- flink-dist: Flink编译好之后的jar包会放在这个文件夹下,也就是网上下载的可执行的版本。其中也包括集群启动、终止的脚本,集群的配置文件等。
- flink-docs: 这个模块并不是Flink的文档,而是Flink文档生成的代码。其中org.apache.flink.docs.configuration.ConfigOptionsDocGenerator是配置文档的生成器,修改相关配置的key或者默认值,重新运行这个类就会更新doc文件夹下的html文件。同样org.apache.flink.docs.rest.RestAPIDocGenerator是Flink RestAPI文档的生成器。
- flink-fliesystems: Flink对各种文件系统的支持,包括HDFS、Azure、AWS S3、阿里云OSS等分布式文件系统。
- flink-formats: Flink对各种格式的数据输入输出的支持。包括Json、CSV、Avro等常用的格式。
- flink-java: Flink java的API,就是写flink应用时用到的map、window、keyBy、State等类或函数的实现。
- flink-jepsen: 对Flink分布式系统正确性的测试,主要验证Flink的容错机制。
- flink-libraries: Flink的高级API,包括CEP(复杂事件处理)、Gelly图处理库等。
- flink-mesos: Flink对mesos集群管理的支持。
- flink-metrics: Flink监控上报。支持上报到influxdb、prometheus等监控系统。具体的使用配置可以在flink-core模块的org.apache.flink.configuration.MetricOptions中找到。
- flink-python: Flink对python的支持,目前还比较弱。
- flink-queryable-state: Flink对可查询状态的支持,其中flink-queryable-state-runtime子模块实现了StateClientProxy和StateServer。这两部分都运行在TaskManager上,StateClientProxy负责接收外部请求,StateServe负责管理内部的queryable state。flink-queryable-state-client-java子模块实现了QueryableStateClient,作为外部系统访问queryable state的客户端。
- flink-runtime: flink运行时核心代码,在第二节细说。
- flink-runtime-web: Flink Web Dashboard的实现。默认启动standalone集群后,访问http://localhost:8081 出现的界面。
- flink-scala: Flink scala的API。
- flink-scala-shell: Flink提供的scala命令行交互接口。
- flink-state-backends: flink状态存储的方式,目前这个模块中只有RocksDBStateBackend,未来可能会支持更多种的状态存储,以适应不同的业务场景。MemoryStateBackend和FsStateBackend的实现并不在这个目录下,而是在flink-runtime目录下。
- flink-streaming-java: Flink Streaming的java API。
- flink-streaming-scala: Flink Streaming的scala API。
- flink-table: Flink Table API,在第三小节中细说。
- flink-yarn: Flink对yarn集群管理的支持。
二. flink-runtime模块
flink-runtime模块是Flink最核心的模块之一,实现了Flink的运行时框架。图三1和图四2分别是Flink运行时框架和作业调度框架,图中标识的几乎所有模块,在flink-runtime下都有对应的实现,如JobManager、TaskManager、ResourceManager、Scheduler、Checkpoint Coordinator等。有些部分看了目录的名字就很好理解,但有些目录与图中的模块无法对应上,官网文档也没有这些名词的介绍,本节就重点介绍下这些目录。
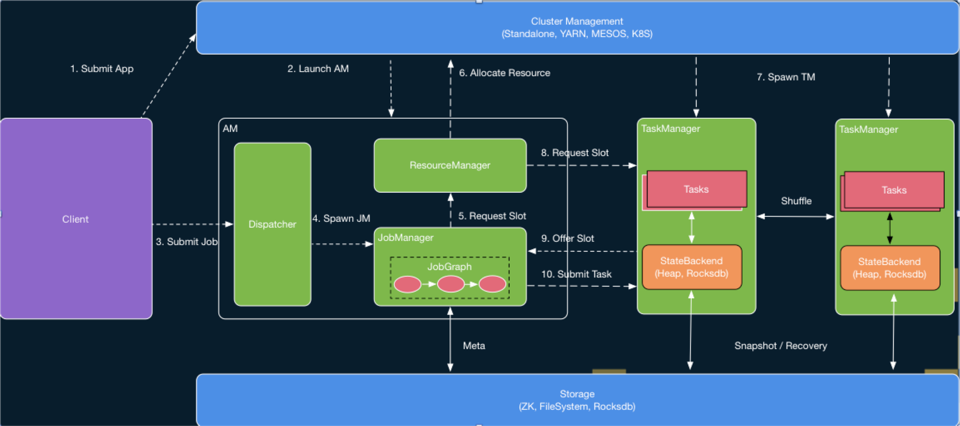
图三 Flink运行时框架
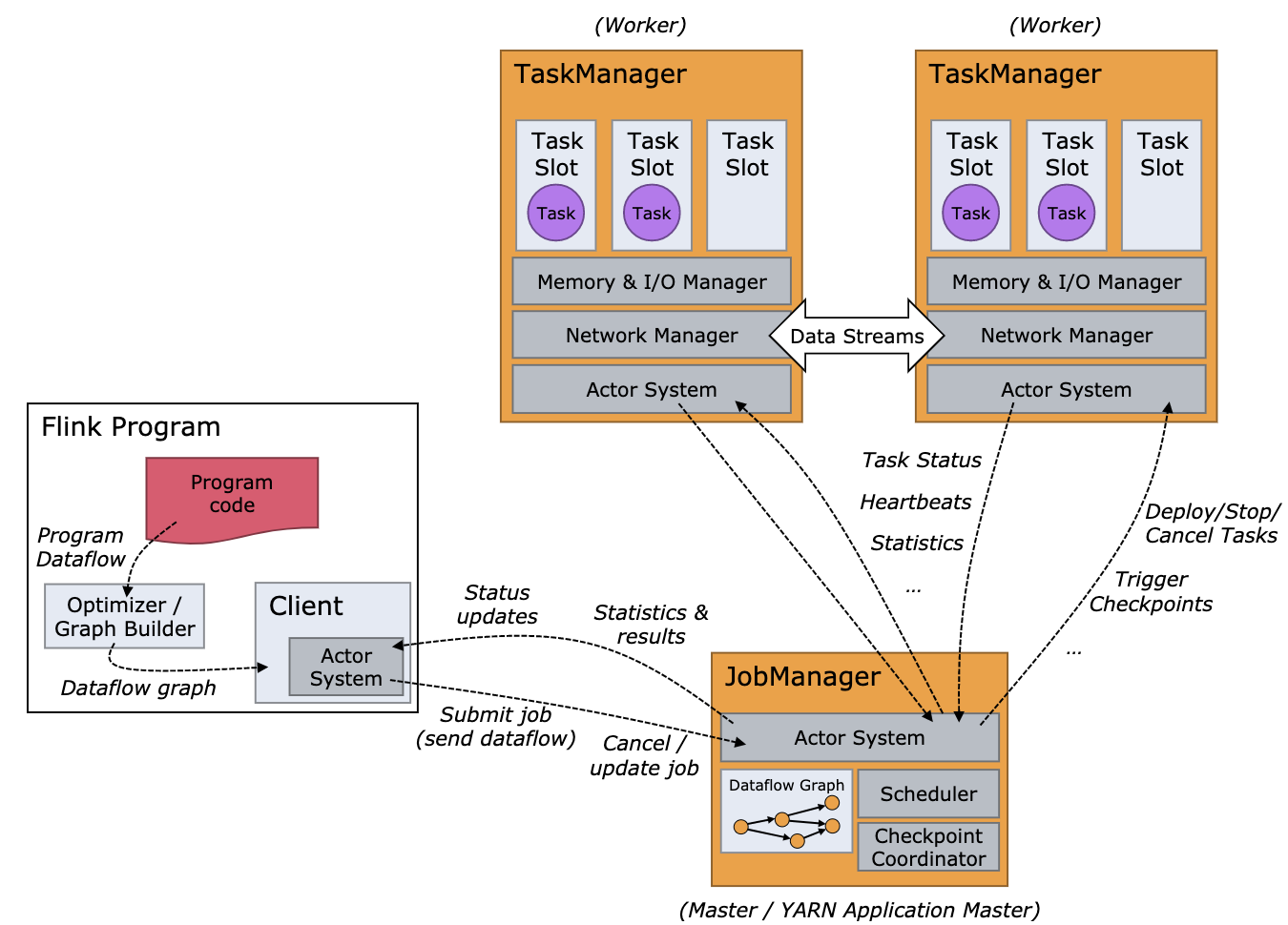
图四 Flink作业调度框架
1. task-executor和task-manager
Flink文档中并没有描述TaskExecutor这个模块,只是说有TaskManager作为任务执行和运行资源管理的服务。实际上图四中的TaskManager是task-executor和task-manager这两个目录下的代码实现的,而且主要的功能还是在task-executor中,因此,我觉得这个TaskManager还不如直接叫做TaskExecutor。
task-executor中org.apache.flink.runtime.taskexecutor.TaskManagerRunner就是TaskManager进程的入口。
代码语言:txt
AI代码解释
package org.apache.flink.runtime.taskexecutor;
public class TaskManagerRunner implements FatalErrorHandler, AutoCloseableAsync {
public static void main(String[] args) throws Exception {
// startup checks and logging
EnvironmentInformation.logEnvironmentInfo(LOG, "TaskManager", args);
SignalHandler.register(LOG);
JvmShutdownSafeguard.installAsShutdownHook(LOG);
long maxOpenFileHandles = EnvironmentInformation.getOpenFileHandlesLimit();
if (maxOpenFileHandles != -1L) {
LOG.info("Maximum number of open file descriptors is {}.", maxOpenFileHandles);
} else {
LOG.info("Cannot determine the maximum number of open file descriptors");
}
final Configuration configuration = loadConfiguration(args);
FileSystem.initialize(configuration, PluginUtils.createPluginManagerFromRootFolder(configuration));
SecurityUtils.install(new SecurityConfiguration(configuration));
try {
SecurityUtils.getInstalledContext().runSecured(new Callable<Void>() {
@Override
public Void call() throws Exception {
runTaskManager(configuration, ResourceID.generate());
return null;
}
});
} catch (Throwable t) {
final Throwable strippedThrowable = ExceptionUtils.stripException(t, UndeclaredThrowableException.class);
LOG.error("TaskManager initialization failed.", strippedThrowable);
System.exit(STARTUP_FAILURE_RETURN_CODE);
}
}
}从main函数看进去,进程启动首先加载了配置(flink-conf.yaml),然后就调用了runTaskManager(),这个函数里最终调用了rpcServer.start(),就相当于启动了一个后台服务进程,等待JobManager给它分配Task了。
TaskManagerRunner最重要的成员就是 taskManager,而它实际上是一个TaskExecutor类型的对象。再看下TaskExecutor的成员,可以看到有TaskSlotTable,就是图四中每个TaskManager中维护的多个TaskSlot;有TaskManagerServices,其中包括MemoryManager、IOManager;有各种Connection,用来维护与其他模块的连接。因此TaskManager实际上对应的是TaskExecutor这个类。
代码语言:txt
AI代码解释
package org.apache.flink.runtime.taskexecutor;
* TaskExecutor implementation. The task executor is responsible for the execution of multiple
* {@link Task}.
*/
public class TaskExecutor extends RpcEndpoint implements TaskExecutorGateway {
public static final String TASK_MANAGER_NAME = "taskmanager";
/** The access to the leader election and retrieval services. */
private final HighAvailabilityServices haServices;
private final TaskManagerServices taskExecutorServices;
/** The task manager configuration. */
private final TaskManagerConfiguration taskManagerConfiguration;
private final HeartbeatServices heartbeatServices;
/** The fatal error handler to use in case of a fatal error. */
...
// --------- TaskManager services --------
/** The connection information of this task manager. */
private final TaskManagerLocation taskManagerLocation;
private final TaskManagerMetricGroup taskManagerMetricGroup;
/** The state manager for this task, providing state managers per slot. */
private final TaskExecutorLocalStateStoresManager localStateStoresManager;
/** The network component in the task manager. */
private final ShuffleEnvironment<?, ?> shuffleEnvironment;
/** The kvState registration service in the task manager. */
private final KvStateService kvStateService;
// --------- job manager connections -----------
private final Map<ResourceID, JobManagerConnection> jobManagerConnections;
// --------- task slot allocation table -----------
private final TaskSlotTable taskSlotTable;
private final JobManagerTable jobManagerTable;
private final JobLeaderService jobLeaderService;
...
// --------- resource manager --------
@Nullable
private ResourceManagerAddress resourceManagerAddress;
@Nullable
private EstablishedResourceManagerConnection establishedResourceManagerConnection;
@Nullable
private TaskExecutorToResourceManagerConnection resourceManagerConnection;
...
}2. entrypoint、jobmanager和jobmaster
图四中可以看出,Flink中Client、TaskManager和JobManager都是独立的进程,本文前面已经分别说明了Client和TaskManager的入口在哪里,那JobManager的入口在哪里呢?
图三中的AM其实是一个单独的进程,入口在entrypoint目录下的org.apache.flink.runtime.entrypoint.ClusterEntrypoint。该类中有一个DispatcherResourceManagerComponent对象,就是对应AM中的Dispatcher和ResourceManager两个模块。Dispatcher中有一个JobManagerRunnerFactory的对象,当用户通过客户端向AM提交任务时,就由Dispatcher创建一个JobManagerRunner对象,其中包括JobGraph和JobMasterService,用来创建运行时的JobMaster。而图四中JobManager中的各个小模块,实际上是在JobMaster这个类中:包括JobGraph、Scheduler、CheckpointCoordinator(来自JobMasterGateway接口)。
代码语言:txt
AI代码解释
package org.apache.flink.runtime.jobmaster;
public class JobMaster extends FencedRpcEndpoint<JobMasterId> implements JobMasterGateway, JobMasterService {
/** Default names for Flink's distributed components. */
public static final String JOB_MANAGER_NAME = "jobmanager";
// ------------------------------------------------------------------------
private final JobMasterConfiguration jobMasterConfiguration;
private final ResourceID resourceId;
private final JobGraph jobGraph;
private final Time rpcTimeout;
private final HighAvailabilityServices highAvailabilityServices;
private final BlobWriter blobWriter;
private final HeartbeatServices heartbeatServices;
private final JobManagerJobMetricGroupFactory jobMetricGroupFactory;
private final ScheduledExecutorService scheduledExecutorService;
private final OnCompletionActions jobCompletionActions;
private final FatalErrorHandler fatalErrorHandler;
private final ClassLoader userCodeLoader;
private final SlotPool slotPool;
private final Scheduler scheduler;
private final SchedulerNGFactory schedulerNGFactory;
// --------- BackPressure --------
private final BackPressureStatsTracker backPressureStatsTracker;
// --------- ResourceManager --------
private final LeaderRetrievalService resourceManagerLeaderRetriever;
// --------- TaskManagers --------
private final Map<ResourceID, Tuple2<TaskManagerLocation, TaskExecutorGateway>> registeredTaskManagers;
private final ShuffleMaster<?> shuffleMaster;
...
}三. flink-table模块
图五 flink-table模块目录
flink-table模块属于Flink的上层API,包括java和scala版本的table-api,以及SQL的解析和SQL的执行。
图六3展示了flink-table中子模块的架构。在Flink 1.9之前,Flink只有一个table-planner(flink-table-planner模块)用来将SQL转化成流计算的执行任务,而且流和批的Table API也不是统一的,因此有StreamTableEnvironment和BatchTableEnvironment两个运行环境,分别用来处理流和批的任务执行。
随着Flink SQL越来越受重视,flink-table从flink-libraries中移了出来,成为了独立的一级目录。Flink 1.9中,阿里把blink-planner开源了出来,这样整个flink-table中就有了2个planner。从长期来看,流批的统一是一个趋势,因此blink-planner只使用了StreamTableEnvironment中相关的API,而没有使用BatchTableEnvironment,将批当做一个有限的流来处理,希望通过这种方式实现流和批的统一。由于blink-table-planner更好的支持流批统一,且性能更好,在未来的版本中,很有可能完全替代flink-table-planner的功能,而flink-table-planner可能将会被移除。
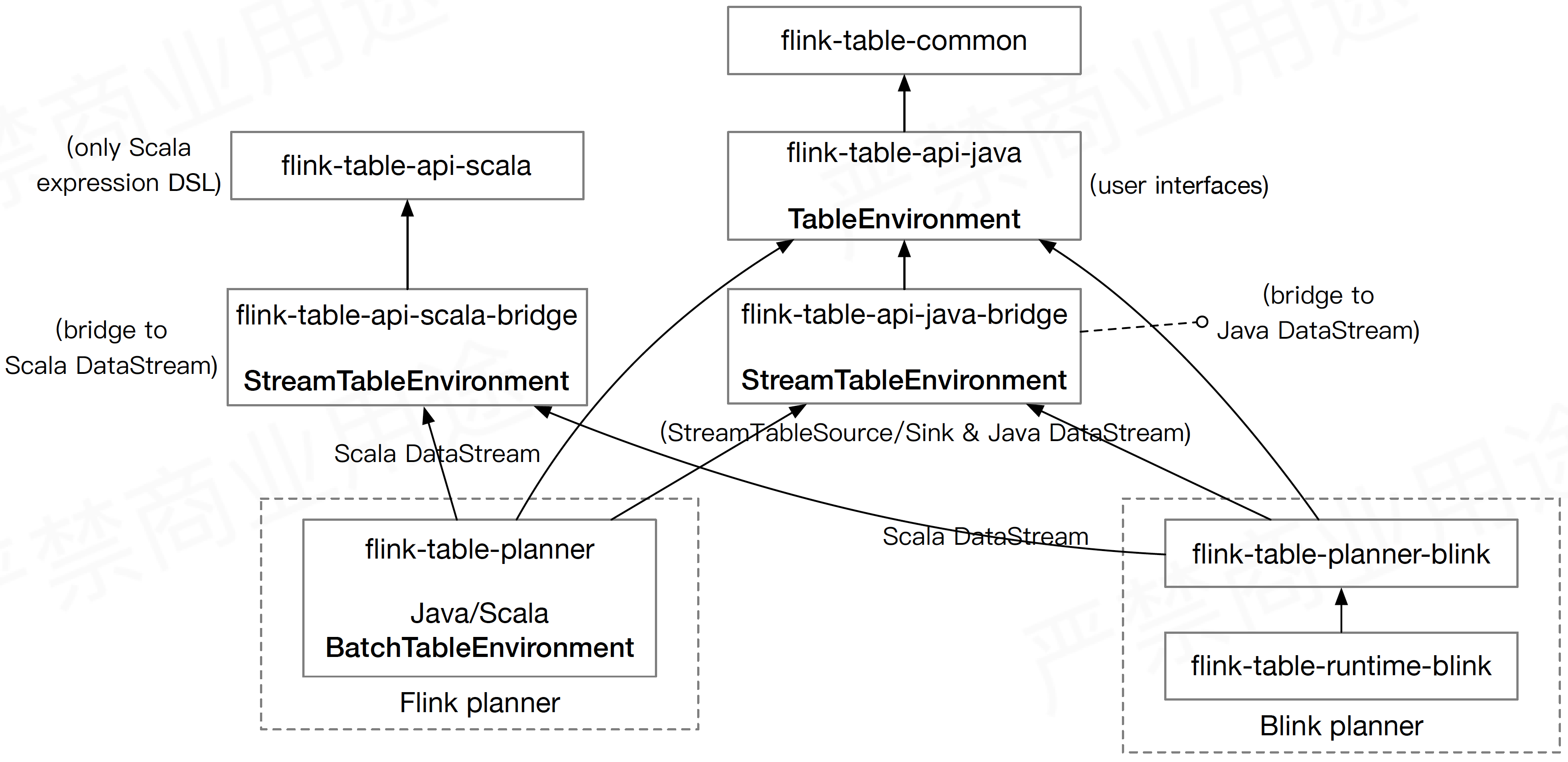
图六 flink-table模块架构
flink-table中还实现了一个命令行的SQL Client,方便开发者学习和调试。其中org.apache.flink.table.client.SqlClient就是这个客户端的入口。
四. 总结
本文大致介绍了一下Flink工程下各个模块的功能,并对flink-runtime和flink-table模块做了进一步的介绍,希望能帮助读者更快的了解Flink代码。最后推荐一个github的仓库,里面有很多关于Flink的视频讲座,https://github.com/flink-china/flink-training-course ,也希望能帮助到大家。
参考文献
1 高赟, Flink Runtime 核心机制剖析, https://files.alicdn.com/tpsservice/7bb8f513c765b97ab65401a1b78c8cb8.pdf.
2 Flink docs, https://ci.apache.org/projects/flink/flink-docs-release-1.9/concepts/runtime.html.
3 贺小令, 深度探索 Flink SQL, https://files.alicdn.com/tpsservice/6f069ca9f2930400a577cc90323de326.pdf.

















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









