







大家好,我是CNU小学生,本文将通俗讲解Sequence2Sequence理论,Soft-Attenssion理论和Self-Attenssioner理论。
基础概念:Sequence to Sequence
这是一个机器翻译的基本概念。现在我有一句中文:我是首都师范大学的学生。我想把它翻译成英文:I am a student of Capital Normal University. 我要怎么做这个工程呢?
首先,对中文分词,将词汇向量化表达。分词结果:我 是 首都 师范 大学 的 学生。这7个中文词,我需要用7个向量去表达它(注:相同的词要用相同的向量表达,本例7个中文词均不相同,所以用7个不同向量表达,中文词的向量化表达可以参考word2vect工程)。
然后,将中文词向量依次代入LSTM,形成一个新的向量。熟悉LSTM的同学都清楚,实际上每一个中文词向量代入到LSTM之后都会产生一个对应的结果向量,但在初级的Sequence to Sequence理论中,我们只保留最后一个中文词向量代入后所产生的向量。将“我 是 首都 师范 大学 的 学生”这7个中文词的词向量依次代入LSTM,产生了7个编码向量,但在这里我们只保留最后一个向量(即“学生”一词代入LSTM后产生的向量)。
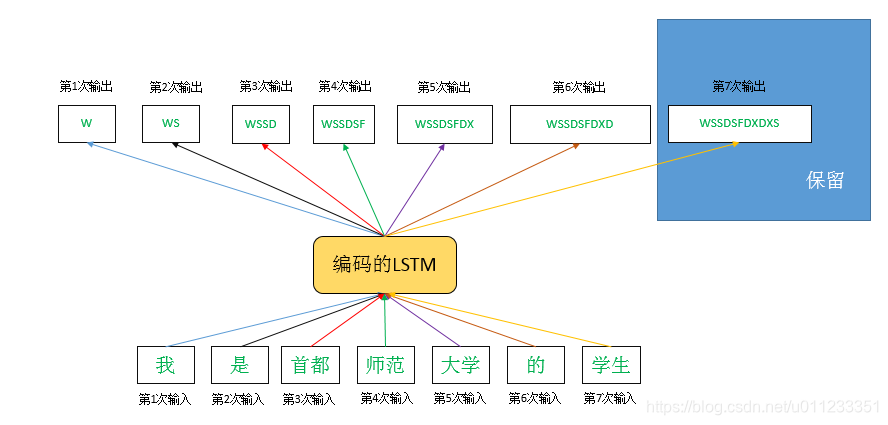
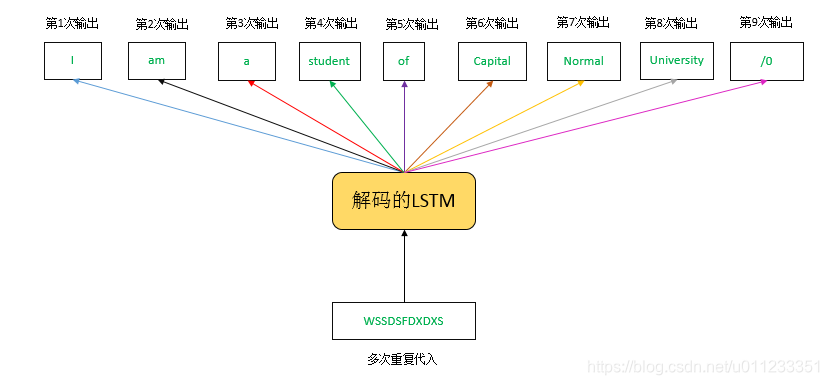
最后,我们将这个新向量(“学生”)多次重复代入另一个LSTM,再通过softmax的方式选择出对应的英文单词序列。根据LSTM的基本原理,每一次代入都会产生一个结果,这次我们保留所有结果。在理想情况下,我们代入向量第一次的时候期望LSTM输出" I " ,第二次重复代入时输出" am ",一直重复代入下去,总共代入9次,我们会得到一个单词序列“I am a student of Capital Normal University”。这个序列由8个单词构成,怎么会代入9次呢? 实际上,第9次代入所输出的结果是一个“停止信号”,类似于“/0”,我们在设计翻译程序时看到网络输出"/0",就代表这句话(这个sequence)的翻译终止。
补充,在真实的机器翻译工程中,我们会对上面的网络进行改造,例如加致密隐藏层,LSTM叠加,双向LSTM等。
基础稍微薄弱一点的同学可能会有一些疑问。由于篇幅有限,我只在这里指出搞懂这些问题的知识点。并且,这些问题其实并不影响你的后续阅读。
1.怎么输出单词?
你需要了解softmax,onehot编码。
2.梯度如何传播?
你需要了解kl散度,LSTM的梯度传播。
下面我们来简述一下原始Sequence to Sequence结构的缺陷。首先我们在解码时荒谬地使用了多次 “学生” 向量,虽说“学生”这个向量在编码时采用的是LSTM,可以“记住”一些前文的信息,但在长句翻译中,这是远远不够的。
进阶模型:Attension
上面说到原始sequence to sequnce 模型的缺陷就是只用了一个向量来表达全句的意思,而不是编码层的每个输出向量都考虑到,所以会丢失很多信息,在长句翻译中连LSTM都无法弥补。这就催生了Attension模型的诞生。
Attension模型没有摆脱senquence to sequence 的架构,输入是词向量序列,输出仍然是词序列。同样保留了编码层和解码层,编码层和原始senquence to sequence一模一样,将“我 是 首都 师范 大学 的 学生”每个词依次代入LSTM,然后得到7个向量,与传统senquence to sequence不同的是,我们不止保留“学生”这个词向量,我们保留所有向量。解码部分有一点点复杂,下面我来由浅入深地向大家解释它的原理。(更正:可以将所有词不通过LSTM编码直接带入ATTENSION)
Attension模型在模仿一个“翻译新手”的翻译方式,这个翻译新手很有意思,因为是新手,所以他的翻译方式很特别:
步骤1.浏览全文是什么(所有中文词都要看一遍)。
步骤2.考虑一下我之前写到哪了(翻译到那个单词了)
步骤3.结合步骤1和步骤2确定我下面该翻译的重点在哪
步骤4.翻译出下一个单词
如此循环往复,最终完成翻译。
让我们来举个例子,我们现在做英译中:There is no Deep Learning without Geoffrey Hinton. 新手翻译开始工作了:
1. 大声朗读全文 There is no Deep Learning without Geoffrey Hinton.
&nb
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5805
5805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









