









 博客主要介绍了解决Windows中运行报错,无法找到winutils.exe的方法,包括解压hadoop的tar包、找到合适版本的软件包并复制文件到指定目录,还给出了程序中的设置代码。此外还提及了Java API代码,源代码可查看相关内容。
博客主要介绍了解决Windows中运行报错,无法找到winutils.exe的方法,包括解压hadoop的tar包、找到合适版本的软件包并复制文件到指定目录,还给出了程序中的设置代码。此外还提及了Java API代码,源代码可查看相关内容。
1.1 解决无法找到winutils.exe的错误
解决windows中运行报错,无法找到winutils.exe的错误。
#1.将hadoop的tar包解压到f盘:
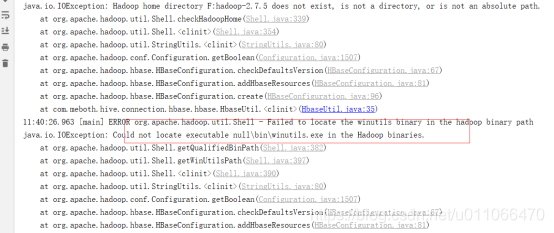
#2找到和使用hadoop最接近的版本hadoop-common-xxx-bin的软件包
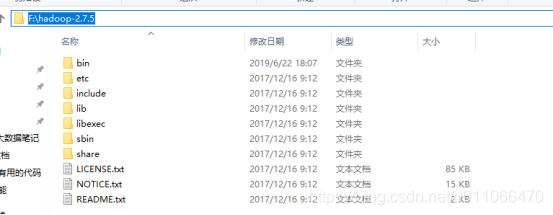
#3.解压后将bin文件夹下的所有文件复制到第一步hadoop版本的bin目录下:
建议重复的文件选择不覆盖
![]()
#在程序中写入:System.setProperty("hadoop.home.dir", "F:\\hadoop-2.7.5");

1.2 java api 代码
package com.meboth.hive.connection.hbase.hbase;
import com.meboth.hive.connection.hbase.utils.DateUtil;
import com.meboth.hive.connection.hbase.utils.PropertiesUtil;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.client.coprocessor.AggregationClient;
import org.apache.hadoop.hbase.client.coprocessor.LongColumnInterpreter;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.log4j.Logger;
import java.io.IOException;
import java.math.BigInteger;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.*;
/**
* @className HbaseUtil
* @Description TODO
* @Author admin
* @Date 2019/6/20 11:35
* @Version 1.0
**/
public class HbaseUtil {
private static Configuration config = null;
private static Connection connection=null;
final static Logger log= Logger.getLogger(String.valueOf(HbaseUtil.class));
static {
// 加载集群配置
System.setProperty("hadoop.home.dir", PropertiesUtil.getParam("hadoop.home.dir"));
config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", PropertiesUtil.getParam("hbase.zookeeper.quorum"));
config.set("hbase.zookeeper.property.clientPort", PropertiesUtil.getParam("hbase.zookeeper.property.clientPort"));
// 创建表池(可微略提高查询性能,具体说明请百度或官方API)
try {
connection = ConnectionFactory.createConnection(config);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String args[]) throws IOException {
String tableName="ENTERPRIS_REPORT_T";
TableName tn=TableName.valueOf(tableName );
String familyArray[]={"noticeInfo","annualReportInfo"};//定义两个列族
Table table=connection.getTable(tn);
//1.建表
//createTable(tableName,familyArray,false);
//2.添加数据:
//putTable(table,familyArray);
//3.查看数据
// scanRecord(table);
String startRow="1471339051098-5";
String r=createMd5(startRow);
System.out.println("r:"+r);
//scanRecordByParam(table,startRow);
// getRecordByRowkey(table,"1561201651426-2");
// getRecordByColumn(table,"1561201651426-2","noticeInfo","name");
//4.修改
//updateData(table,"1561339051098-5", "noticeInfo", "name","hdoop123");
//scanRecordByParam(table,startRow);
//4.删除
//deleteByRowKey(table,"1561339051098-5");//通过rowkey删除
// scanRecordByParam(table,startRow);
//deleteColumn(table,"1561339051085-1","annualReportInfo", "date","2019-06-24 09:17:31:092");//删除列
//deleteFamily(table,"1561339051085-1","annualReportInfo", "date","2019-06-24 09:17:31:092");
delTable(tn);//删除表
scanRecordByParam(table,startRow);
}
/**
* 创建表
* @param tableName
* @param familyArray
* @param partionFlag
*/
public static void createTable(String tableName,String familyArray[],boolean partionFlag){
List<String> list=new ArrayList<String>();
try {
Admin hadmin = connection.getAdmin();
TableName tm = TableName.valueOf(tableName);
if (!hadmin.tableExists(TableName.valueOf(tableName))) {
HTableDescriptor hTableDescriptor = new HTableDescriptor(tm);
for(String colFa:familyArray){
HColumnDescriptor family = new HColumnDescriptor(colFa);
family.setMaxVersions(1);
hTableDescriptor.addFamily(family);
}
if(partionFlag){
hadmin.createTable(hTableDescriptor,calcSplitKeys(list,5000,50));
}
else {
hadmin.createTable(hTableDescriptor);//不分区
}
hadmin.close();
}
else {
System.out.println("新建表:"+tableName+"已存在");
log.info("新建表:"+tableName+"已存在");
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
log.info("create hbase table successful..........");
}
/**
* 向hbase中添加数据
* @param hTable
*/
public static void putTable(Table hTable,String familyArray[]) {
List<Put> listp = new ArrayList<Put>();
int count = 10;
for (int i = 1; i <= 5; i++) {
String temp= String.valueOf(new Date().getTime());
Put put = new Put(Bytes.toBytes(temp+"-"+i));
String value = i + "张三";
String email = i + value + "@123.com";
for(int k=0;k<familyArray.length;k++){
if(k==0){
put.addColumn(familyArray[k].getBytes(), "name".getBytes(),
value.getBytes());
put.addColumn(familyArray[k].getBytes(), "age".getBytes(),
Bytes.toBytes("5"));
}
else{
put.addColumn(familyArray[k].getBytes(), "email".getBytes(),
Bytes.toBytes(email));
put.addColumn(familyArray[k].getBytes(), "date".getBytes(),
Bytes.toBytes(DateUtil.getStrYYYYMMDDHHmmssSSS(new Date())));
}
}
listp.add(put);
}
try {
hTable.put(listp);
} catch (IOException e) {
e.printStackTrace();
}
listp.clear();
log.info("添加数据成功..........................");
}
/**
*
* @param keyIndexTable
* @param nowTime
* @param startRow
* @return
*/
public int getTotalRecord(Table keyIndexTable , String nowTime,String startRow){
int count=0;
AggregationClient aggregationClient = new AggregationClient(config);
Scan scan=new Scan();
if(!startRow.equals("")){
scan.setStartRow(Bytes.toBytes(startRow));
}
scan.setStopRow(nowTime.getBytes());//小于当前时间
try {
Long rowCount = aggregationClient.rowCount(keyIndexTable, new LongColumnInterpreter(), scan);
aggregationClient.close();
count=rowCount.intValue();
} catch (Throwable e) {
e.printStackTrace();
}
return count;
}
/**
* scan 全量查询
* @param hTable
* @throws IOException
*/
private static void scanRecord(Table hTable) throws IOException {
Scan scan = new Scan();
ResultScanner scanner = hTable.getScanner(scan);
for (Result result : scanner) {
System.out.println("rowKey:"+new String(result.getRow()));
for (Cell cell : result.rawCells()) {
System.out.println("列族:"+new String(CellUtil.cloneFamily(cell))+ " 列:"+new String(CellUtil.cloneQualifier(cell))+ " 值:"+new String(CellUtil.cloneValue(cell)));
}
}
}
/**
* scan 设置查询条件的模糊查询
* @param hTable
* @throws IOException
*/
private static void scanRecordByParam(Table hTable,String startRow) throws IOException {
Scan scan = new Scan();
//scan.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("name"));
scan.setStartRow(Bytes.toBytes(startRow));
String nowTime=DateUtil.getStrYYYYMMDDhhmm(new Date());//小于当前时间
scan.setStopRow(Bytes.toBytes(nowTime));
ResultScanner scanner = hTable.getScanner(scan);
for (Result result : scanner) {
System.out.println("rowKey:"+new String(result.getRow()));
for (Cell cell : result.rawCells()) {
System.out.println("列族:"+new String(CellUtil.cloneFamily(cell))+ " 列:"+new String(CellUtil.cloneQualifier(cell))+ " 值:"+new String(CellUtil.cloneValue(cell)));
}
}
}
/**
* 修改
* @param hTable
* @param rowKey
* @param family
* @param column
* @param value
*/
public static void updateData(Table hTable,String rowKey,String family,String column,String value) {
// TODO Auto-generated method stub
try {
// 将行键传入put
Put put = new Put(Bytes.toBytes(rowKey));
// 增加数据
put.addColumn(Bytes.toBytes(family), Bytes.toBytes(column), Bytes.toBytes(value));
hTable.put(put);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* get方式 通过rowkey查询,相当于精确查询,
* @param hTable
* @param rowkeyArray
*/
private static void getRecordByRowkey(Table hTable,String rowkeyArray){
Get get = new Get(Bytes.toBytes(rowkeyArray));
//显示结果
Result results=null;
try {
results = hTable.get(get);
//2.获取基本信息
for(Cell cellInfo : results.rawCells()){
String familyInfo=new String(CellUtil.cloneFamily(cellInfo));
String valueInfo=new String(CellUtil.cloneValue(cellInfo ));
String columnInfo=new String(CellUtil.cloneQualifier(cellInfo));
System.out.println(new String(results.getRow())+">>"+"列族info:"+familyInfo+" >>列info:"+columnInfo+" >>值info:"+valueInfo);
// log.info(rowKeyValue+">>"+"列族info:"+familyInfo+" >>列info:"+columnInfo+" >>值info:"+valueInfo);
}
} catch (Exception e) {
e.printStackTrace();
} // 遍历结果
}
/**
* get方式 查询指定的某列,
* @param hTable
* @param rowkeyArray
*/
private static void getRecordByColumn(Table hTable,String rowkeyArray,String familyName,String column){
Get get = new Get(Bytes.toBytes(rowkeyArray));
get.addColumn(Bytes.toBytes(familyName),Bytes.toBytes(column));
//显示结果
Result results=null;
try {
results = hTable.get(get);
//2.获取基本信息
for(Cell cellInfo : results.rawCells()){
String familyInfo=new String(CellUtil.cloneFamily(cellInfo));
String valueInfo=new String(CellUtil.cloneValue(cellInfo ));
String columnInfo=new String(CellUtil.cloneQualifier(cellInfo));
System.out.println(results.getRow()+">>"+"列族info:"+familyInfo+" >>列info:"+columnInfo+" >>值info:"+valueInfo);
// log.info(rowKeyValue+">>"+"列族info:"+familyInfo+" >>列info:"+columnInfo+" >>值info:"+valueInfo);
}
} catch (Exception e) {
e.printStackTrace();
} // 遍历结果
}
/**
* 删除指定的某个rowkey
* @param hTable
* @param rowKey
* @throws Exception
*/
public static void deleteByRowKey(Table hTable, String rowKey) {
Delete de =new Delete(Bytes.toBytes(rowKey));
try {
hTable.delete(de);
} catch (IOException e) {
e.printStackTrace();
}
log.info("删除rowkey:"+rowKey+" 成功!!!");
}
/**
* 删除某列
*/
public static void deleteColumn(Table hTable,String rowKey,String family,String column,String v) throws IOException {
Delete delete = new Delete(Bytes.toBytes(rowKey));
delete.addColumn(Bytes.toBytes(family),Bytes.toBytes(column));//删除指定的一个单元
hTable.delete(delete);
//table.delete(List<Delete>); //通过添加一个list集合,可以删除多个
}
/**
*删除列族https://www.cnblogs.com/similarface/p/5795730.html
*/
public static void deleteFamily(Table hTable,String rowKey,String family,String column,String v){
Delete delete = new Delete(Bytes.toBytes(rowKey));
delete.addFamily(Bytes.toBytes(family));//删除该行的指定列族
try {
hTable.delete(delete);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 删除表
* @param tm
* @return
* @throws IOException
*/
private static boolean delTable(TableName tm) throws IOException {
boolean flag=false;
try {
Admin hadmin =connection.getAdmin();
if (hadmin.tableExists(tm)) {
hadmin.disableTable(tm);
hadmin.deleteTable(tm);
}
hadmin.close();
flag=true;
} catch (Exception e) {
e.printStackTrace();
}
log.info("删除表成功==================");
return flag;
}
/**
* 预分区,根据预分区的region个数,对整个集合平均分割,即是相关的splitkeys。
* @param rkGen
* @param baseRecord
* @param prepareRegions
* @return
*/
public static byte[][] calcSplitKeys(List<String> rkGen, int baseRecord, int prepareRegions) {
int splitKeysNumber = prepareRegions - 1;
int splitKeysBase = baseRecord / prepareRegions;
byte[][] splitKeys = new byte[splitKeysNumber][];
TreeSet<byte[]> rows = new TreeSet<byte[]>(Bytes.BYTES_COMPARATOR);
for (String rk : rkGen) {
rows.add(createMd5(rk).getBytes());
}
int pointer = 0;
Iterator<byte[]> rowKeyIter = rows.iterator();
int index = 0;
while (rowKeyIter.hasNext()) {
byte[] tempRow = rowKeyIter.next();
if ((pointer != 0) && (pointer % splitKeysBase == 0)) {
if (index < splitKeysNumber) {
splitKeys[index] = tempRow;
index ++;
}
}
pointer ++;
rowKeyIter.remove();
}
rows.clear();
rows = null;
return splitKeys;
}
/**
* md5随机散列,通过SHA或者md5生成随机散列的字符串。
* @param plainText
* @return
*/
public static String createMd5(String plainText) {
byte[] secretBytes = null;
try {
secretBytes = MessageDigest.getInstance("md5").digest(
plainText.getBytes());
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("没有md5这个算法!");
}
String md5code = new BigInteger(1, secretBytes).toString(16);// 16进制数字
// 如果生成数字未满32位,需要前面补0
for (int i = 0; i < 32 - md5code.length(); i++) {
md5code = "0" + md5code;
}
return md5code;
}
}
源代码见:

















 1356
1356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









