




一 redis数据类型源码
1.1 数据类型结构

1.2 redis6与redis7常见数据类型
1.2.1 redis6的数据类型

1.2.2 redis7的数据类型

1.3 常见类型操作

1.4 数据类型功能介绍
1.字符串
int:8个字节的长整形
embstr:小于等于44个字节的字符串;
raw:大于44个字节的字符串
redis采用sds,会根据当前值的类型和长度决定使用哪种内部编码实现。
2.哈希
ziplist(压缩表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)。同时所有值都小于hash-max-ziplist-value配置(默认64字节)时,redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
hashtable(哈希表):当哈希类型无法满足时ziplist的条件时,此时ziplist的读写效率下降,redis使用hashtable作为哈希的内部实现,因为hashtable的读写时间复杂度为o(1)
3.列表
ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置(默认为512个),同时列表中每个元素的值小于list-max-ziplist-value配置时(默认64字节)。redis会选用ziplist作为列表的内部实现来减少内存的使用。
linkedlist(链表):当列表类型无法满足ziplist的条件时,redis会使用linedlist作为列表的内部事项。
quicklist是以ziplist和linkedlist的结合,以ziplist为节点的链表(linkedList)
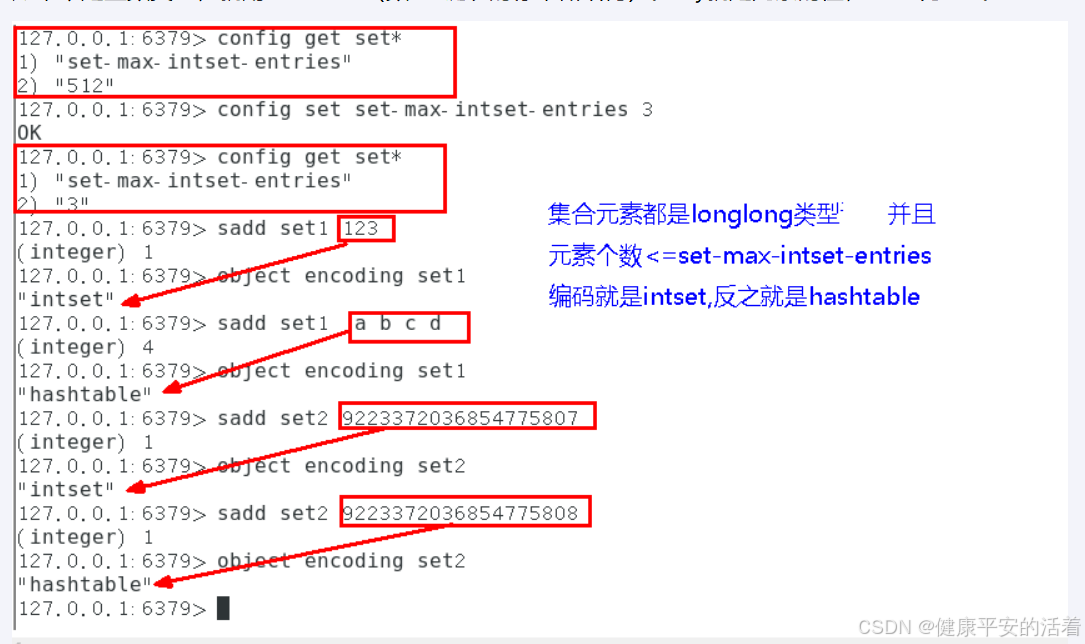
4.集合
intset(整数集合):当集合中的元素都是整数且元素个数小于set-max-ziplist-entries配置(默认512个)时,redis会用intset来作为集合的内部实现,从而减少内存的使用。
hashtable(哈希表): 当集合类型无法满足intset的条件时,redis会使用hashtable作为集合的内部实现。
set=intset(整形数组)+hashtable
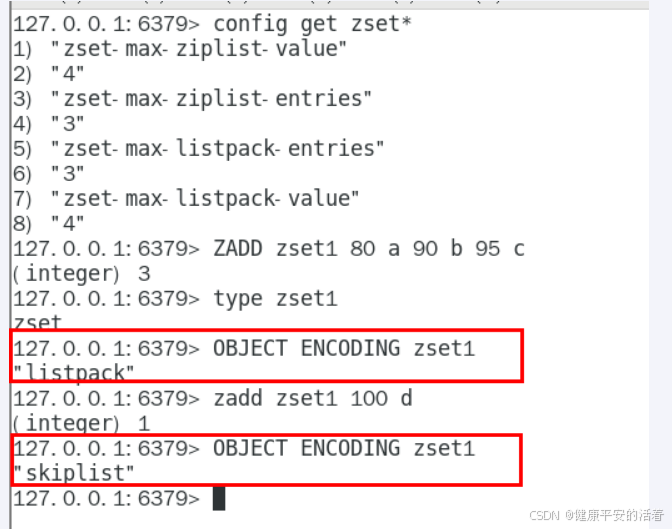
5.有序集合
ziplist(压缩列表):当有序集合的元素个数小于zset-max-ziplist-entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,redis会用ziplist来作为有序集合的内部事项,ziplist可以有效减少内存的使用。
skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作为内部实现,因为此时ziplist的读写效率会下降。
二 常见数据类型
2.1 String类型
只有整数才会使用 int,如果是浮点数, Redis 内部其实先将浮点数转化为字符串值,然后再保存。
embstr 与 raw 类型底层的数据结构其实都是 SDS (简单动态字符串,Redis 内部定义 sdshdr 一种结构)。
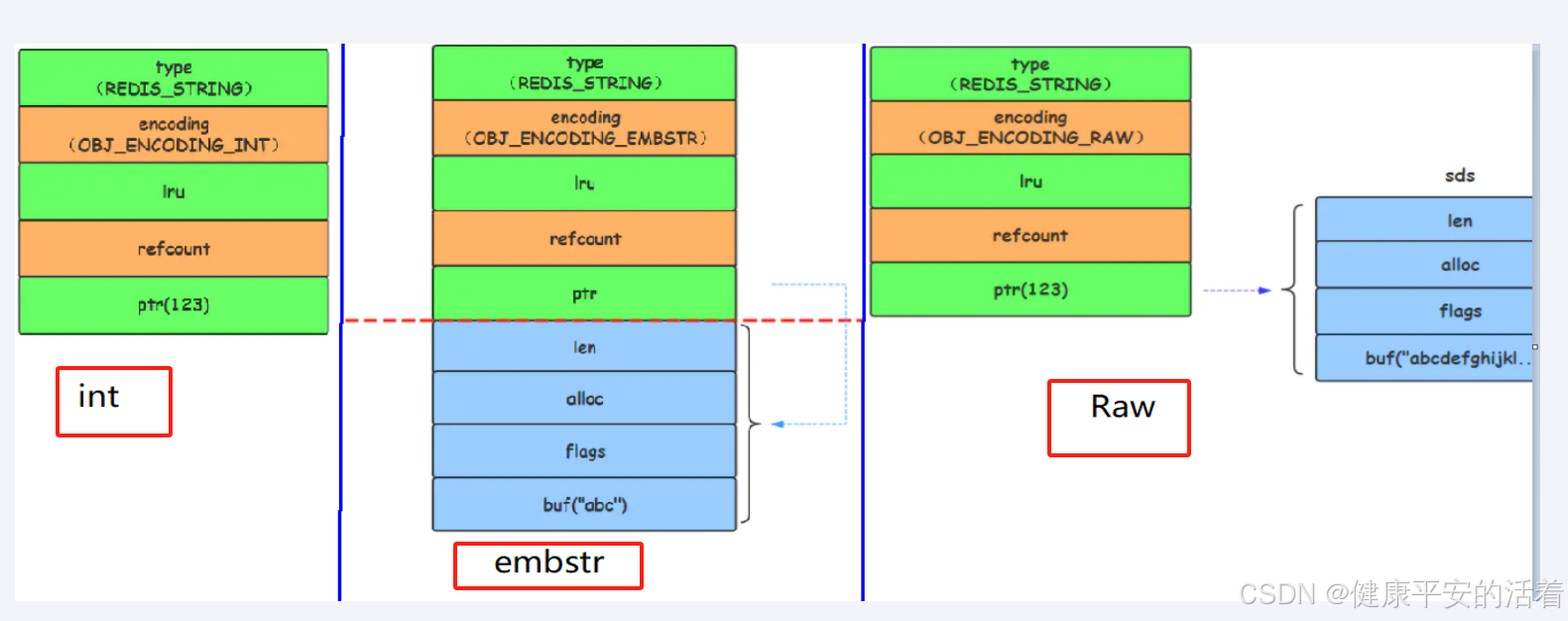
| 1.类型int | Long类型整数时,Redisobject中的ptr指针直接赋值为整数数据,不再额外的指针再指向整数了,节省了指针的空间开销。 |
| 2.类型embstr | 当保存的是字符串数据且字符串小于等于44字节时,embstr类型将会调用内存分配函数,只分配一块连续的内存空间,空间中依次包含redisObject与sdshdr两个数据结构,让元数据、指针和SDS是一块连续的内存区域,这样就可以避免内存碎片。 |
| 3.类型raw | 当字符串大于44字节时,SDS的数据量变多变大了,SDS和RedisObject布局分家各自过,会给SDS分配多的空间,并用指针指向SDS结构,raw类型将会调用两次内存分配函数,分配两块内存空间,一块用于包含redisObject结构,而另外一块用于包含sdshdr结构。 |
结构图:
2.2 Hash类型
2.2.1 概述
hash的两种编码格式: redis6=ziplist+hashtable; redis7=listpack+hashtable
hash-max-ziplist-entries: 使用压缩列表保存保存时,哈希集合中的最大元素个数。
hash-max-ziplist-value:使用压缩列表保存时哈希集合中单个元素的最大长度。
Hash类型键的字段个数小于hash-max-ziplist-entries,并且每个字段名称的长度小于hash-max-ziplist-value时,redis才会使用OBJ_ENCODING_ZIPLIST来存储该键,前述条件任意一个不满足则会转换为OBJ_ENCODING_HT的编码方式。
如:哈希对象保存的键值对数量小于512个;且所有的键值对的键和值的字符串长度小于等于64bytes时用ziplist,反之用hashtable。ziplist升级到hashtable可以,反过来降级不可以。
常用命令:
1.查看
config get hash* 查看
2.设置
config set hash-max-ziplist-entries 3
config set hash-max-zpilist-value 8
2.3.2 ziplist类型
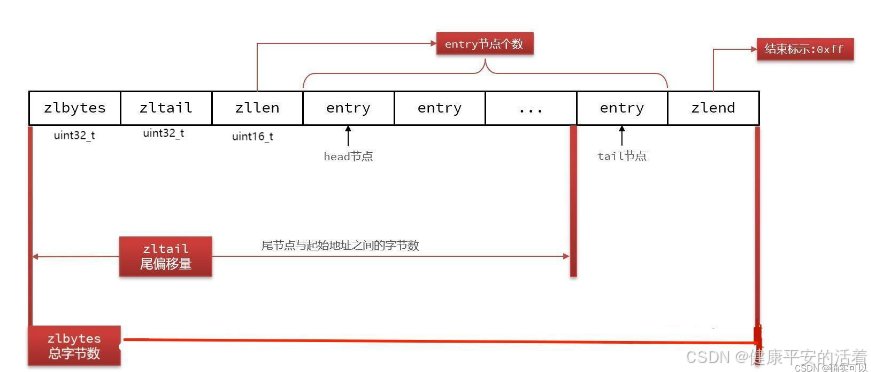
ziplist是一个经过特殊编码的双向链表,它不存储指向前一个链表节点的指针prev和指向下一个链表的指针next,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率。节约内存是一种时间换空间的思想,只用在字段个数少,字段值小弟场景里面。
压缩列表是 Redis 为节约内存空间而实现的一系列特殊编码的连续内存块组成的顺序型数据结构, 本质上是字节数组。在模型上将这些连续的数组分为3大部分,分别是header+entry集合+end。
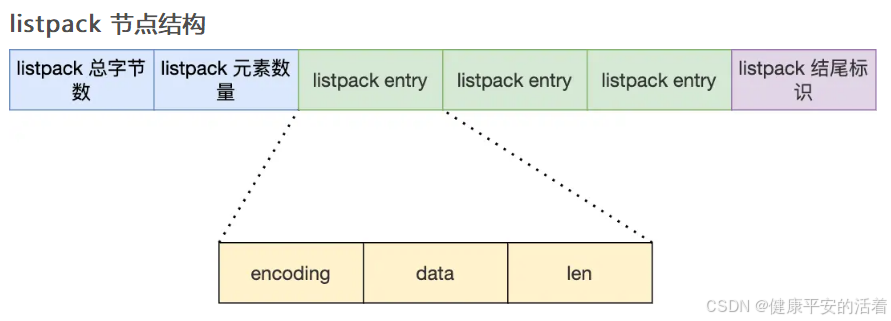
2.3.3 listpack类型
listpack 头包含两个属性,分别记录了 listpack 总字节数和元素数量,然后 listpack 末尾也有个结尾标识。图中的 listpack entry 就是 listpack 的节点了,相对于ZipList,没有记录距离尾节点的偏移量,Listpack节省了这部分内存空间。
https://blog.youkuaiyun.com/weixin_44415582/article/details/131726131
2.3 list类型
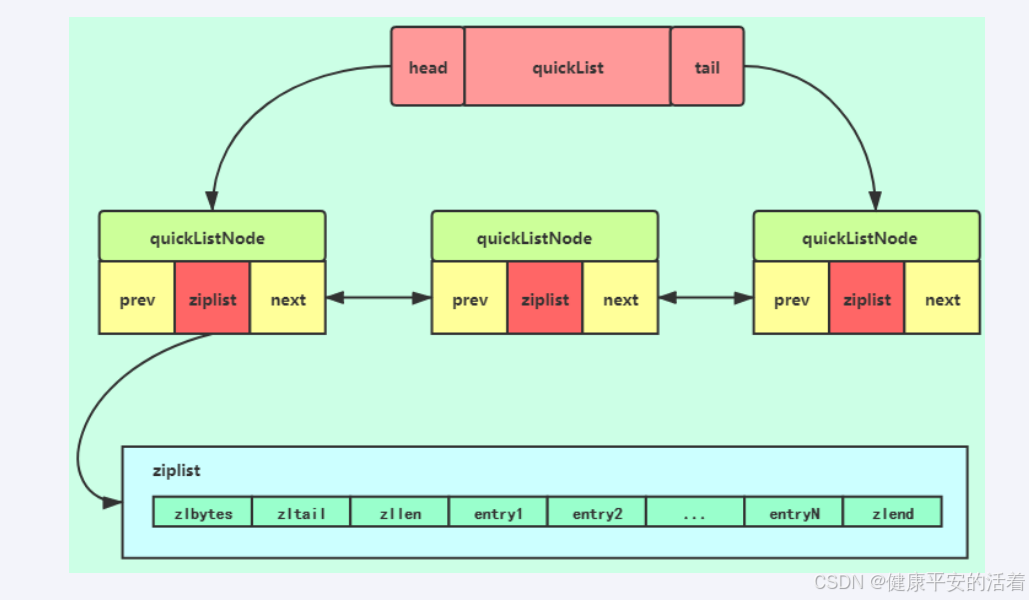
1)list6:
quicklist实际上是ziplist和linkedlist的混合体,它将linedlist按段切分,每一端使用ziplist来紧凑存储,多个ziplist之间使用双向指针串接起来。
2)list7:
list7是quicklist,其中qucklist是linkedlist和listpack的结合体;qucklist存储了一个双向链表,每个节点都是listpack(代替了ziplist)
2.4 set类型
1.set类型结构
set=intset(整形数组)+hashtable
Redis用intset或hashtable存储set。如果元素都是整数类型,就用intset存储。
如果不是整数类型,就用hashtable(数组+链表的存来储结构)。key就是元素的值,value为null。
2.操作案例
2.5 zset类型
2.5.1 概述
redis6=ziplist+skiplist;redis7=listquick+skiplist ;
1)redis6中:
当有序集合中包含的元素数量超过服务器属性 server.zset_max_ziplist_entries 的值(默认值为 128 ),或者有序集合中新添加元素的 member 的长度大于服务器属性 server.zset_max_ziplist_value 的值(默认值为 64 )时,redis会使用跳跃表作为有序集合的底层实现。否则会使用ziplist作为有序集合的底层实现

2)redis7中:
2.5.2 skiplist跳表
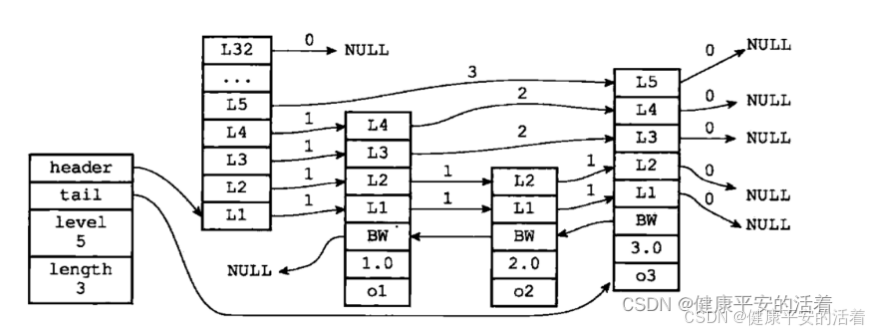
跳表是可以实现二分查找的有序链表;总的来讲 跳表=链表+多级索引。跳跃表中查询任意数据的时间复杂度就是 O(logn)
优点:
跳表是一个最典型的空间换时间的解决方案,而且只有在数据量较大的情况下才能体现出来优势,而且应该是读多写少的情况下才能使用,所以它的使用范围应该是比较有限的。
缺点:
维护成本相对要高,
在单链表中,一旦定位好要插入的位置,插入结点的时间复杂度是很低的,就是O(1)
但是:新增或者删除时需要把所有索引都更新一遍,为了保证原始链表中数据的有序性,我们需要先找到要动作的位置,这个查找操作就会比较耗时最后在新增和删除的过程中的更新,时间复杂度也是O(log n)

















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









