







关键词:编码、设计、Java、服务端、后端、接口、接口层、分层、需求、设计、系统、inerface、接口安全、接口性能、接口参数、接口异常、接口错误码、统一日志、接口返回值、接口定义、接口设计
1. 接口层编码准备
1.1 理解设计
一般而言,在开始编码前,已经完成了需求设计与评审、详细设计与评审。
在正式编码前,应充分理解设计要求,保持编码与设计一致:
- 需求理解
结合《需求文档》《交互设计》的需求描述,以及《详细设计》的需求分析部分,充分理解需求、评估风险。
- 设计理解
- 理解《详细设计》中的物理架构变更,明确编码模块所处组件位置。
- 理解《详细设计》中的领域模型变更,明确编码模块的领域设计,作为后续对模块、包、类的编码依据。
- 理解《详细设计》中的技术路线变更,明确需引入、升级、部署的依赖组件,进行工程、环境搭建。
- 系统设计
充分理解系统设计的内容,作为后续编码的依据。
1.2 补充设计
有时候,因客观因素,导致详细设计不充分。这时,尽量不要无设计开发,容易引发较大问题。
最基本的,要进行以下动作:
- 领域先行,数据是一切的基础。一般而言,数据是一个系统的基石。接口如果涉及底层数据表的改动,必须进行必要的评审。草率的改动,可能给会荼毒后续版本、甚至带来灾难性的后果。
- 先对齐再编码,提前接口定义。现在基本上是前后端分离开发,提前进行接口定义,便于提前深入交流需求和设计,对齐前后端思想,提前发现问题。否则,将会有极大的重复返工的可能性,反而降低了整体效率。
- 先思考再动手,捋清关键逻辑。对复杂的接口,提前梳理实现逻辑,按需绘制流程图、序列图、状态图等。与产品经理、开发组长、测试组长等关键角色同步,决策关键点。便于提前暴露风险,减少过程反复。
- 识风险控进度,分析非功能指标。有时产品经理不容易暴露所有的非功能需求,研发提前分析识别,有助于避免方案一而再、再而三的改动,导致开发进度一延再延。
2. 接口层编码要求
2.1 接口分解
详细阅读《详细设计》中关于接口定义的部分,可以拆解为以下方面:
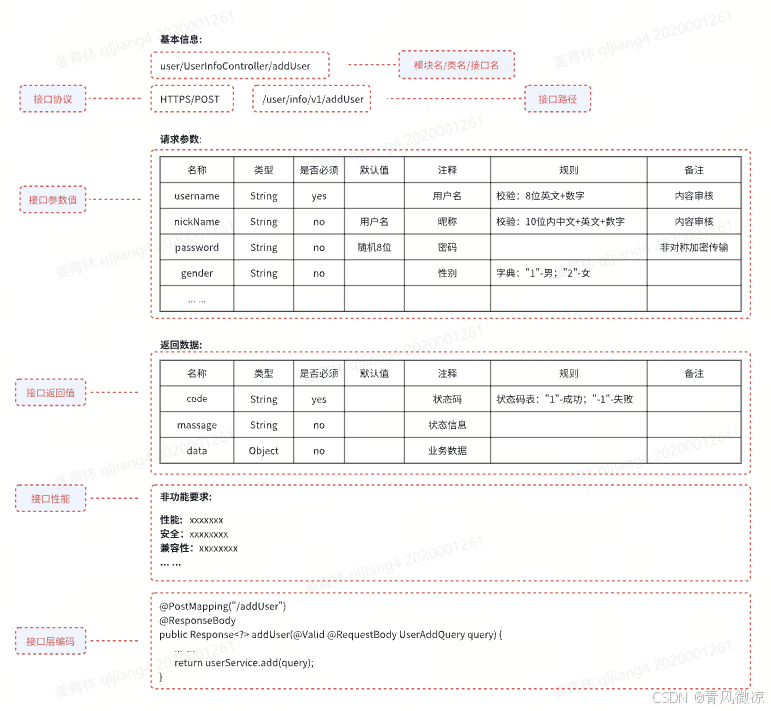
2.2 关注要点
基于上述拆解,在接口设计与代码实现上,需重点关注以下要求:
| 类型 | 位置 | 要求 | 描述 |
| 接口设计 | 设计原则 | 符合单一职责原则 | 只负责一个职责,推荐以对象+行为进行细粒度拆分,功能单一灵活才好维护和扩展。 |
| 复合接口隔离原则 | 不强迫依赖不需要的接口。 | ||
| 充分原则 | 接口不随意添加/删除/修订,必要性要充分。 | ||
| 统一原则 | API要具备统一的命名规范、出入参规范、异常规范、错误码规范、版本规范等。 | ||
| 基本信息 | 接口命名 | 接口命名应符合命名规范 | 模块名、类名、接口名,以及参数和返回值名、变量与常量等接口命名应符合命名规范。 |
| 接口协议 | 接口协议明确统一 | 不同协议接口独立管理。对于HTTP接口,统一以 POST 为主,一致>>更优。 | |
| 接口路径 | 命名规范 | 路径命名符合编码规范 | |
| 出参入参 | 接口参数值 | 实体隔离 | 接口使用独立的VO,不与其他接口共用,更不使用下层代码的BO或PO。 |
| 字段最小化原则 | 接口参数只定义需要的字段,及时清理过期的字段,非必要不加入冗余字段。 | ||
| 参数校验 | 接口参数需要进行统一的参数校验,推荐使用validation。 | ||
| 参数安全 | 接口参数需要防XSS/CSRF/CORS攻击、防SQL注入等。 | ||
| UGC安全 | 用户UGC数据接入内容审核平台。 | ||
| 接口返回值 | 返回值格式统一 | 接口的返回值使用统一的响应实体封装,格式统一。 | |
| 错误码统一清晰 | 接口使用统一规范的错误码,涵盖错误消息、业务异常等。 | ||
| 字段最小化原则 | 接口返回值字段只包含需要的字段,非必要不返回冗余字段。 | ||
| 敏感信息脱敏 | 对敏感信息脱敏处理。 | ||
| 接口编码 | 接口层编码 | 接口层单一职责 | 接口层只应负责参数校验处理、请求转发等,不应参与实际业务操作。 |
| 统一异常处理 | 使用统一异常捕获处理,而非每个接口try-catch。 | ||
| 接口性能 | 性能 | 接口响应性能 | 提升性能可使用异步、缓存等方法。 (具体策略,详见下文《性能十八打》) |
| 接口吞吐性能 | |||
| 接口并发性能 | |||
| 安全 | 认证授权 | 接口应统一进行用户身份认证和授权,包括接口权限、数据权限等。 | |
| 请求安全 | 接口应对请求进行限制和过滤,应考虑使用防篡改、防重放策略。 | ||
| 内容安全 | 防XSS/CSRF/CORS攻击、防SQL注入,敏感信息需要脱敏、UGC信息需要内容审核。 | ||
| 传输安全 | 信息传输安全,通常需要使用 SSL/TLS 或其他加密协议,以确保请求和响应数据在传输过程中得到保护。 | ||
| 日志记录 | 关键接口、关键步骤一定要记录日志。 | ||
| 兼容性 | 接口版本 | 接口需要控制版本,修改老接口时,应重点关注接口的兼容性。 | |
| 可靠性 | 接口容错 | 接口实现需考虑限流、熔断、降级,以及资源隔离、第三方容错。 | |
| 幂等性 | 接口幂等 | 考虑接口的幂等性需要,防止重复处理。 | |
| 可维护性 | 接口文档内容完整 | 接口数量和定义完整,推荐使用YApi、Swagger等工具。 | |
| 接口文档更新及时高效 | 接口文档更新及时高效,推荐使用YApi、Swagger等工具。 | ||
| 接口注释完整 | 接口注释应充足,关键逻辑应详细注释、及时更新。 | ||
| 可测性 | 接口应可测试 | 单元测试、测试用例。 |
3. 接口层编码实践
3.1 接口命名应符合编码规范
| 接口命名:以动词短语命名,符合命名规范。 |
接口方法以动词短语命名,常见的命名方式推荐:
| 常见命名 | 含义 |
| get*** | 获取单个对象 |
| list*** | 获取多个对象 |
| count*** | 计数,获取统计值 |
| add/insert*** | 新增 |
| remove/delete*** | 删除 |
| edit/update*** | 修改 |
| find/search*** | 查询 |
| do/execute*** | 执行某个过程或者流程 |
| init*** | 初始化 |
| check/validate*** | 校验合法性 |
3.2 统一接口参数校验
| 接口参数:每个接口单独定义VO,不与其他接口的VO共用,更不与其他BO或PO共同。 |
实体类定义:
@Setter
@Getter
public class UserAddQuery {
/**
* 用户名
*/
@NotBlank
private String username;
/**
* 昵称
*/
@NotBlank
@Length(message = "名称不能超过个 {max} 字符", max = 10)
private String nickname;
/**
* 身份证号
*/
@NotBlank
private String idCard;
/**
* 年龄
*/
@NotNull
@Range(message = "年龄范围为 {min} 到 {max} 之间", min = 1, max = 200)
private Integer age;
}| Java |
| 接口参数:接口参数需要进行参数校验。推荐使用validation。 |
参数校验统一拦截器:
@RestControllerAdvice
public class CommonExceptionHandler {
/**
* 处理请求参数格式错误 @RequestBody上validate失败后抛出的异常是MethodArgumentNotValidException异常。
*/
@ExceptionHandler({MethodArgumentNotValidException.class})
public Response<?> handleMethodArgumentNotValidException(MethodArgumentNotValidException ex) {
return Response.fail(ErrorCode.USER_ERROR_3132);
}
/**
* 处理请求参数格式错误 @RequestParam上validate失败后抛出的异常是javax.validation.ConstraintViolationException
*/
@ExceptionHandler({ConstraintViolationException.class})
public Response<?> handleConstraintViolationException(ConstraintViolationException ex) {
return Response.fail(ErrorCode.USER_ERROR_3132);
}
}| Jav |
3.3 统一接口返回值定义
| 接口响应:接口的返回值应使用统一的响应实体封装。 |
定义统一响应实体,例如:
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class Response<T> extends DTO {
private static final long serialVersionUID = 1L;
private boolean success;
/**
* @see ErrorCode
*/
private String errCode;
private String errMessage;
private T data;
public static Response<?> succeed() {
return new Response<>(true, null, null, null);
}
public static <T> Response<T> succeed(T data) {
Response<T> response = new Response<>();
response.setSuccess(true);
response.setData(data);
return response;
}
public static Response<?> fail(ResponseCode errorCode) {
return new Response<>(false, errorCode.getCode(), errorCode.getMessage(), null);
}
}| Java |
3.4 统一异常和错误码
| 接口响应:接口使用统一规范的错误码。 |
错误码示例:
/**
统一错误码
<p>
1xxx:高优问题:如数据库失败、支付失败、登录短信发送失败等
2xxx:中优问题:如推送短信发送失败、营销短信发送失败等
3xxx:低优问题:需要达到一定的频率才告警,例如5分钟内超过20次登录失败、5分钟内超过10次优惠券兑换失败等
*/
public enum AlertCode implements ResponseCode {
/**
* 一级宏观错误码:用户
*/
USER_ERROR_3100("3100", "用户端错误"),
/*
* 二级宏观错误码:用户-注册
*/
USER_ERROR_3101("3101", "用户名校验失败"),
USER_ERROR_3102("3102", "用户名已存在"),
USER_ERROR_3103("3103", "用户名包含敏感词"),
USER_ERROR_3104("3104", "用户名包含特殊字符"),
/*
* 二级宏观错误码:用户-登录
*/
USER_ERROR_3110("3110", "用户账户不存在"),
USER_ERROR_3112("3112", "用户账户被冻结"),
USER_ERROR_3113("3113", "用户密码错误"),
USER_ERROR_3114("3114", "用户输入密码错误次数超限"),
/*
* 二级宏观错误码:用户-访问
*/
USER_ERROR_3120("3120", "访问未授权"),
USER_ERROR_3121("3121", "授权已过期"),
USER_ERROR_3122("3122", "无权限使用 API"),
USER_ERROR_3123("3123", "用户访问被拦截"),
/*
* 二级宏观错误码:用户-输入
*/
USER_ERROR_3130("3130", "用户请求参数错误"),
USER_ERROR_3131("3131", "无效的用户输入"),
USER_ERROR_3132("3132", "请求必填参数为空"),
USER_ERROR_3133("3133", "非法的时间戳参数"),
USER_ERROR_3134("3134", "请求参数值超出允许的范围"),
USER_ERROR_3135("3135", "参数格式不匹配"),
/*
* ... ...
*/
;
private final String code;
private final String message;
AlertCode(String code, String message) {
this.code = code;
this.message = message;
}
@Override
public String getCode() {
return code;
}
@Override
public String getMessage() {
return message;
}
}| Java |
3.5 统一鉴权
统一鉴权
3.6 统一日志
统一日志
3.7 常见的接口编码实现
| 代码逻辑:接口层只应进行参数的校验、转换,以及请求转发。不建议有实际的业务操作。 |
以HTTP接口为例,根据详细设计中关于接口的定义,编写接口层代码:
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Resource
private UserService userService;
@PostMapping("/add")
@ResponseBody
public Response<?> add(@Valid @RequestBody UserAddQuery query) {
return userService.add(query);
}
@PostMapping("/edit")
@ResponseBody
public Response<?> edit(@Valid @RequestBody UserEditQuery query) {
return userService.edit(query);
}
@PostMapping("/remove")
@ResponseBody
public Response<?> remove(@Valid @NotBlank String userId) {
return userService.remove(userId);
}
@GetMapping("/{userId}")
@ResponseBody
public Response<GetUserResponse> get(@PathVariable @Valid @NotBlank String userId) {
return userService.get(userId);
}
}| Java |
3.8 常见安全攻击和解决方案
3.8.1 常见的安全攻击
3.8.1.1 未授权的访问
未经授权的访问是 API 安全中最常见的问题之一。攻击者可以使用未经授权的凭据或者伪造请求,获取对受保护的资源的访问权限。这种攻击可能导致敏感信息泄露、恶意操作等风险。
以下是一个未经授权的访问示例,攻击者使用伪造的请求头部信息获取了对资源的访问权限:
GET /api/resources/1 HTTP/1.1Host: api.example.com
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c| HTTP |
3.8.1.2 SQL 注入和其他注入攻击
SQL 注入是一种常见的攻击方式,攻击者通过在请求参数中注入恶意的 SQL 语句,获取敏感信息或者修改数据库记录。其他注入攻击包括跨站点脚本攻击(XSS)等,攻击者可以在请求参数中注入恶意的脚本代码,获取敏感信息或者执行恶意操作。
以下是一个 SQL 注入攻击的示例,攻击者在请求参数中注入恶意的 SQL 语句,获取了数据库中的敏感信息:
GET /api/resources?id=1;SELECT * FROM users WHERE username='admin'-- HTTP/1.1
Host: api.example.com
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c| HTTP |
3.8.1.3 跨站点请求伪造(CSRF)
跨站点请求伪造(CSRF)是一种攻击方式,攻击者通过在受信任网站上伪造请求,使用户在不知情的情况下执行恶意操作。例如,攻击者可以在电子邮件中包含一个恶意链接,用户点击链接后会在受信任的网站上执行恶意操作。
以下是一个 CSRF 攻击的示例,攻击者伪造了一个请求,向受信任的网站提交了恶意数据:
<html>
<body>
<form action="https://api.example.com/api/resources" method="POST">
<input type="hidden" name="name" value="恶意数据">
<input type="hidden" name="amount" value="1000000">
<input type="submit" value="提交">
</form>
</body>
</html>| HTML |
3.8.1.4 拒绝服务攻击(DoS)
拒绝服务攻击(DoS)是一种攻击方式,攻击者通过向 API 发送大量请求,使得 API 无法正常工作。这种攻击可能导致 API 无法响应正常的请求,影响服务的可用性和稳定性。
以下是一个 DoS 攻击的示例,攻击者向 API 发送了大量的请求,占用了大量的资源:
GET /api/resources?id=1 HTTP/1.1
Host: api.example.com
GET /api/resources?id=2 HTTP/1.1
Host: api.example.com
GET /api/resources?id=3 HTTP/1.1
Host: api.example.com| HTTP |
3.8.2 常见安全解决方案
为了保护 API 免受恶意攻击和滥用,开发者可以采取以下几个方面的措施:
- 认证和授权:使用 OAuth2.0 或其他身份验证和授权协议,对请求进行身份验证和授权,确保只有授权用户才能访问受保护的资源。
- 加密和传输安全:使用 SSL/TLS 或其他加密协议,以确保请求和响应数据在传输过程中得到保护。对于敏感信息,可以使用对称加密或非对称加密进行加密处理。
- 输入验证和防止注入攻击:对输入数据进行验证和过滤,例如使用正则表达式或其他方法过滤掉非法字符或语句,防止 SQL 注入、XSS 等攻击。
- 防止拒绝服务攻击:对请求进行限制和过滤,例如限制每个用户的请求频率、限制请求的数据量和频率等,以防止恶意攻击者对 API 进行过度使用和占用资源。
- 日志记录和监控:对 API 的请求和响应进行日志记录和监控,及时发现异常情况和恶意攻击,并采取相应的措施进行处理。
3.9 常见接口性能优化方案
3.9.1 性能数字概念
在评估接口性能时,我们需要首先找出最耗时的部分,并优化它,这样优化效果才会立竿见影。
系统延时的各种数字概念:
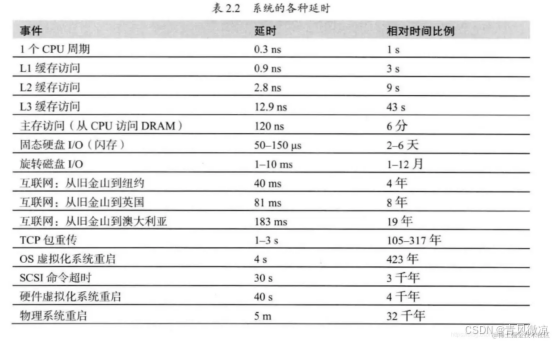
跨地域的耗时计算:
我们已知光在真空中传播,折射率为 1,其光速约为 c=30 万公里/秒,当光在其他介质里来面传播,其介质折射自率为 n,光在其中的速度就降为 v=c/n,光纤的材料是二氧化硅,其折射率 n 为 1.44 左右,计算延迟的时候,可以近似认为 1.5,我们通过计算可以得出光纤中的光传输速度近似为 v=c/1.5= 20 万公里/秒。
以北京和深圳为例,直线距离 1920 公里,接近 2000 公里,传输介质如果使用光纤光缆,那么延迟时间 t=L/v = 0.2 万公里/20 万公里/秒=10ms ,也就是说从北京到深圳拉一根 2000 公里的光缆,单纯的距离延迟就要 10ms ,实际上是没有这么长的光缆的,中间是需要通过基站来进行中继,并且当光功率损耗到一定值以后,需要通过转换器加强功率以后继续传输,这个中转也是要消耗时间的。另外数据包在网络中长距离传输的时候是会经过多次的封包和拆包,这个也会消耗时间。
综合考虑各种情况以后,以北京到深圳为例,总的公网延迟大约在 40ms 左右,北京到上海的公网延迟大约在 30ms,如果数据出国的话,延迟会更大,比如中国到美国,延迟一般在 150ms ~ 200ms 左右,因为要经过太平洋的海底光缆过去的。
中间件的耗时和并发的基本数字:
对于机房内的访问,Redis缓存的访问耗时通常在1-5毫秒之间,而数据库的主键索引访问耗时在5-15毫秒之间。当然,这两者最大的区别不仅仅在于耗时,而更重要的是它们在承受高并发访问方面的能力。Redis单机可以承受10万并发(往往瓶颈在网络带宽和CPU),而MySQL要考虑主从读写分离和分库分表,才能稳定支持5千并发以上的访问。
3.9.2 前端层面优化
3.9.2.1 页面静态化
静态化加速方法:
- 将访问频繁,但基本不变的页面拆分、并静态化为HTML文件。
- 注入HTML文件到CDN,可以避免每次用户的请求都访问原始服务器,可以分担负载、提高响应和吞吐。
3.9.2.2 利用浏览器缓存
有两种较常用的应用场景值得使用缓存策略一试,当然更多应用场景都可根据项目需求制定。
- 频繁变动资源:设置Cache-Control:no-cache,使浏览器每次都发送请求到服务器,配合Last-Modified/ETag验证资源是否有效
- 不常变化资源:设置Cache-Control:max-age=31536000,对文件名哈希处理,当代码修改后生成新的文件名,当HTML文件引入文件名发生改变才会下载最新文件
3.9.2.3 渲染优化
- CSS策略:基于CSS规则,避免多层嵌套,避免重复匹配重复定义,关注可继承属性等
- DOM策略:基于DOM操作,避免过多DOM
- 阻塞策略:基于脚本加载,区分设置defer和async
- 回流重绘策略:基于回流重绘
- 异步更新策略:基于异步更新
3.9.3 数据库层面优化
3.9.3.1 SQL优化
通过查看线上日志或者监控报告,查到某个接口用到的某条sql语句耗时比较长。
索引优化判断:
- 该sql语句加索引了没?
- 加的索引生效了没?
- 加的索引合理吗?
MySQL常见索引失效的场景:
- 查询表达式索引项上有函数,将无法使用索引
- 一次查询(简单查询,子查询不算)只能使用一个索引
- 不等于!= 无法使用索引
- 未遵循最左前缀匹配导致索引失效
- 类型转换导致索引失效,例如字符串类型指定为数字类型等
- like模糊匹配以通配符开头导致索引失效
- 索引字段使用is not null导致失效
- 查询条件存在 OR,且无法命中索引
SQL优化小技巧:
- 通过执行计划优化索引
- 控制索引数量,避免过大索引
- 避免使用 select *,只返回所需数据
- 选择合理的字段类型
- 批量操作替代单个循环
- 多用 limit
- 避免 in 值过多
- 用连接替代子查询
- 使用小表驱动大表
- 避免join过多表
3.9.3.2 分库分表
大动作,分库分表。
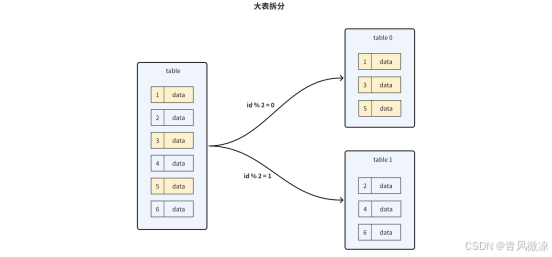
将数据拆分,将极大缓解性能压力,但分库分表也可能会带入很多问题:
- 分库分表后,数据在分表内产生数据倾斜。
- 如何创建全局性的唯一主键id。
- 数据如何路由到哪一个分片。
每一个问题展开都要花费很长篇幅来讲解,这里就不展开细讲了。
关于分库分表,推荐使用 sharding-jdbc。
3.9.3.3 冗余数据
存储结构不仅要方便写入,还要方便查询。既然查询不方便,我们可以冗余一份数据,以便于查询。
通过冗余更多的数据,以减少关联查询的次数,可以提高查询性能。
冗余方式:
- 在表中冗余其他表的字段
- 引入新的聚合表
注意事项:
- 冗余带来更新的麻烦
3.9.3.4 归档历史数据
MySQL并不适合存储大数据量,如果不对数据进行归档,数据库会持续膨胀,从而降低查询和写入的性能。为了满足大数据量的读写需求,需要定期对数据库进行归档。
在进行数据库设计时,需要事先考虑到对数据归档的需求。例如可以使用创建时间进行归档,例如归档一年前的数据。
3.9.3.5 读写分离
增加MySQL数据库的从节点来实现负载均衡,减轻主节点的查询压力,让主节点专注于处理写请求,保证读写操作的高性能。
当需要跨地域进行数据库的查询时,由于较高网络延迟等问题,接口性能可能变得很差。在数据实时性不太敏感的情况下,可以通过在多个地域增加从节点来提高这些地域的接口性能。
3.9.3.6 MySQL 换 ES/HBase等
MySQL并不适合大数据量存储,若不对数据进行归档,数据库会一直膨胀,从而降低查询和写入的性能。
- 对于检索的场景,首推使用 Elasticseach。
- 对海量数据读写场景,推荐将数据异构到HBase中。
3.9.4 接口优化
3.9.4.1 合理拆分接口
如果HTTP接口功能过于庞大,那么会导致核心数据和非核心数据杂糅在一起,耗时高和耗时低的数据耦合在一起。为了优化请求的耗时,可以通过拆分接口,将核心数据和非核心数据分别处理,从而提高接口的性能。
在RPC接口方面,也可以使用类似的思路进行优化。当上游需要调用多个RPC接口时,可以并行地调用这些接口。优先返回核心数据,如果处理非核心数据或者耗时高的数据超时,则直接降级,只返回核心数据。这种方式可以提高接口的响应速度和效率,减少不必要的等待时间。
3.9.4.2 裁剪冗余的接口参数和返回值
过大的参数或返回值会严重拉低接口响应时间,应遵循最小化原则。
3.9.4.3 预热低流量接口
对于访问量较低的接口来说,通常首次接口的响应时间较长。原因是JVM需要加载类、Spring Aop首次动态代理,以及新建连接等。这使得首次接口请求时间明显比后续请求耗时长。
不同的接口预热方式有所不同。
- 对于读接口,可以考虑在服务启动时,自行调用一次接口。
- 对于写接口,还可以尝试更新特定的一条数据。
- 可以在服务启动时加载对应的类,以减少首次调用的耗时。
3.9.5 逻辑处理优化
3.9.5.1 提前过滤请求
在某些活动匹配的业务场景里,相当多的请求实际上是不满足条件的,如果能尽早的过滤掉这些请求,就能避免很多无效查询。例如用户匹配某个活动时,会有非常多的过滤条件,如果该活动的特点是仅少量用户可参加,那么可首先使用人群先过滤掉大部分不符合条件的用户。
3.9.5.2 合理使用缓存
合理利用多级缓存,包括本地缓存、分布式缓存等:
- 本地缓存: Guava、Caffeine等
- 分布式缓存:Redis、Memcached等
使用缓存提高性能的几种场景:
- 缓存接口常用的热点数据
- 缓存常用接口的不常变化数据
- 缓存预先计算的数据
注意事项:
- 选择合理的数据结构
- 关注缓存命中率
- 预估缓存容量空间,制定快速扩容策略
- 缓存数据一致性问题
- 缓存数据的淘汰策略
- 缓存的QPS
- 客户端连接数
3.9.5.3 传递上下文
接口内,避免重复的查询和写入操作,一般遵循:
- 同样的表非必要只读取或写入一次,避免重复操作。
- 已读取的信息,避免重复读取,有需要应向下传递。
在复杂的业务操作中,应定义一个Context 上下文对象,将一些中间信息存储并传递下来,会大大减轻后面流程的再次查询压力。
注意事项:
- 应预估内存占用情况,注意及时释放,防止内存堆积。
3.9.5.4 使用异步策略
使用异步策略的几种方式:
- 实时性要求不高的分支业务操作,使用异步线程处理。
- 实时性要求不高的分支第三方操作,使用MQ异步处理。
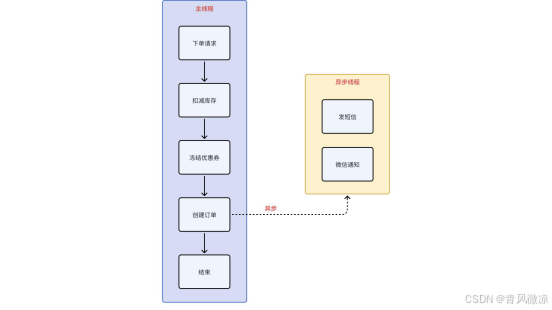
注意事项:
- 避免处理分布式事务
- 需注意失败策略
- 避免逻辑过于复杂
3.9.5.5 合理池化技术
使用池化技术,避免重复创建和销毁,提高性能:
- HTTP连接池
- 数据库连接池
- 线程池
合理设置池参数同样重要:最小连接数、空闲连接数、最大连接数等。
3.9.5.6 使用并行策略
并行策略极大的提高了接口的复杂度,提高了扩展和维护成本。一定要慎重选择,非必要不使用。
梳理业务流程,画出时序图,分清楚哪些是串行?哪些是并行?充分利用多核 CPU 的并行化处理能力。如下图所示,存在上下文依赖的采用串行处理,否则采用并行处理。
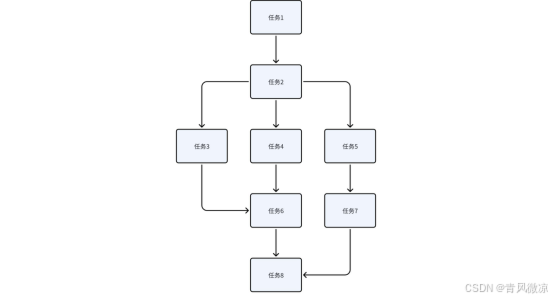
JDK 的 CompletableFuture 提供了非常丰富的API,大约有50种 处理串行、并行、组合以及处理错误的方法,可以满足我们的场景需求。
3.9.5.7 最小化锁的颗粒度
原则上,锁是能不用就不用。如果非要使用,一定要合理控制锁的力度,过大会影响性能和稳定性。
3.9.5.8 避免一次性查询过多数据
在进行查询操作时,应尽量将单次调用改为批量查询或分页查询。不论是批量查询还是分页查询,都应注意避免一次性查询过多数据,比如每次加载10000条记录。因为过大的网络报文会降低查询性能,并且Java虚拟机(JVM)倾向于在老年代申请大对象。当访问量过高时,频繁申请大对象会增加Full GC(垃圾回收)的频率,从而降低服务的性能。
3.9.6 硬件提升
在软件提升空间不大的情况,必要时选择硬件提升,效果会非常显著:
- 当瓶颈是计算时,使用更强、或更多的CPU/GPU。
- 当瓶颈是磁盘读取速度时,使用更好的SSD盘,或分散到多机上读取。
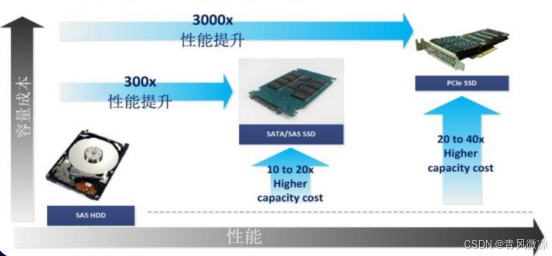
- 当瓶颈是内存时,使用更大的内存,或利用多机内存。
- 当瓶颈是网络速度时,提升到更高的带宽速度。
3.9.7 产品及交互层面优化
大家往往容易死磕技术优化,忽视了产品和交互层面的改进。有时候,通过和产品沟通交互和业务逻辑,很容易就能解决很棘手的技术问题。
沟通的注意事项:
- 需求不是完全一成不变的
- 想要推动产品变更需求,必须理解原始客户诉求
- 维持良好的沟通氛围,避免隔阂
可选的方式有:
- 限制用户行为。限制单位时间内的用户操作,例如短信发送上限、账号关注上限、评论发言上限等。
- 调整交互顺序
- 调整产品逻辑

















 1669
1669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









