




 本文介绍了610万迭代的AMP模型底丹,强调了其高效成型能力。建议使用高显存(16G以上)的GPU进行训练,同时提供了详细的系统配置建议,如虚拟内存设置和导出直播模型的注意事项。
本文介绍了610万迭代的AMP模型底丹,强调了其高效成型能力。建议使用高显存(16G以上)的GPU进行训练,同时提供了详细的系统配置建议,如虚拟内存设置和导出直播模型的注意事项。
AMP610万迭代万能底丹:点击下载
610万AMP模型底丹,带变形因子,在这个基础上继续训练模型,能快速成型,600万迭代AMP模型还是比较稀有的
发到其他论坛老是被删,发到这里赚点积分用用
ae_dims: 512
inter_dims: 2048
e_dims: 128
d_dims: 128
d_mask_dims: 72
看这几个参数就知道是不是好模型了,绝对的高参数底丹,建议显存16g以上继续训练,显卡12G的电脑训练模型带不起来
系统高级设置里边,虚拟内存设置100G以上,导出直播模型的时候虚拟内存达到100G了
网盘里边包含底丹模型 和 导出的直播丹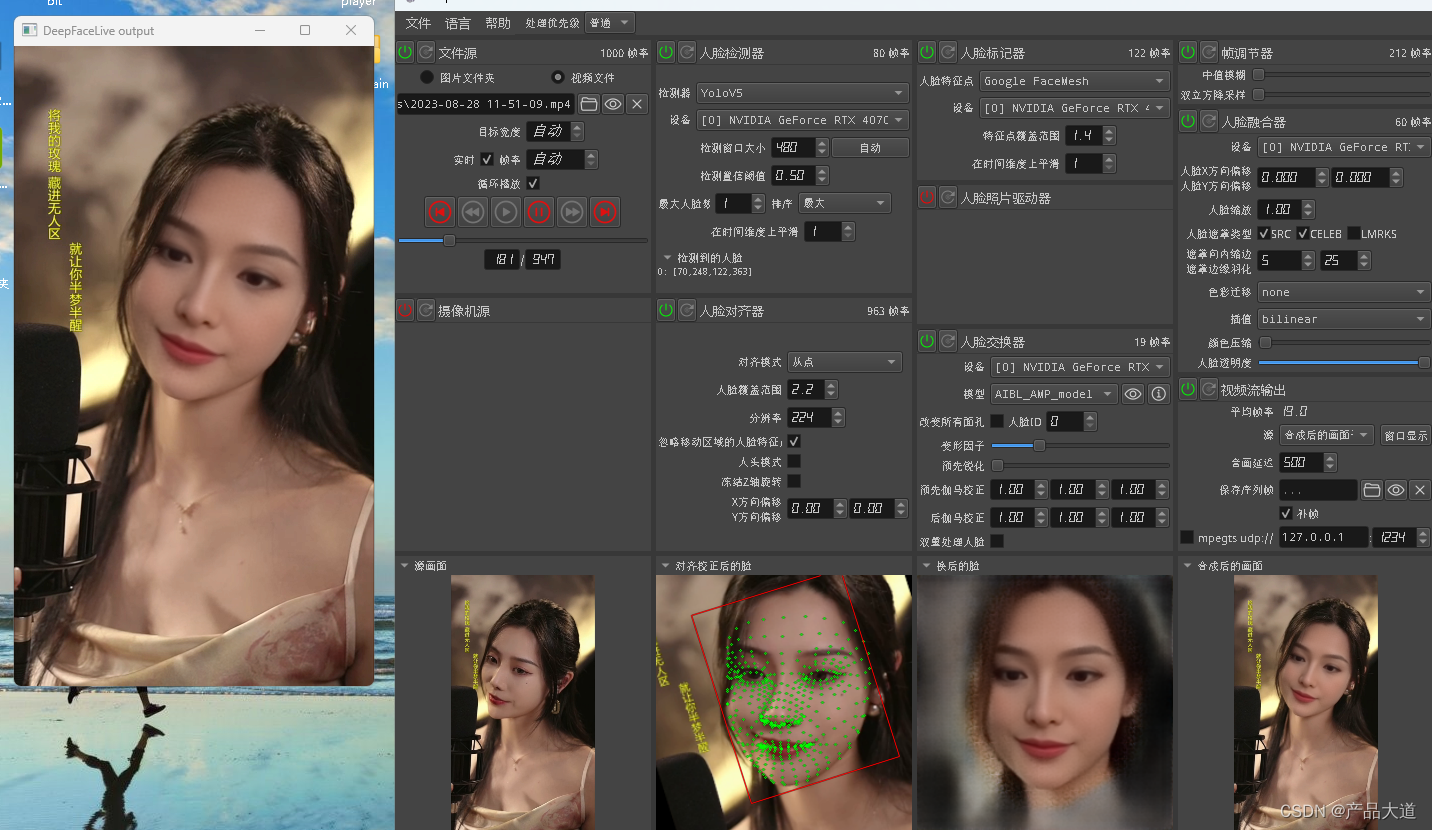
- ========================模型概要========================
- 模型名字: shendan_AMP
- 当前迭代: 6107299
- ----------------------模型选项----------------------
- retraining_samples: True
- resolution: 256
- face_type: wf
- models_opt_on_gpu: True
- ae_dims: 512
- inter_dims: 2048
- e_dims: 128
- d_dims: 128
- d_mask_dims: 72
- morph_factor: 0.5
- preview_mf: 1
- masked_training: True
- eyes_prio: False
- mouth_prio: False
- uniform_yaw: True
- loss_function: SSIM
- blur_out_mask: False
- adabelief: True
- lr_dropout: y
- random_warp: False
- random_hsv_power: 0.05
- random_downsample: False
- random_noise: False
- random_blur: False
- random_jpeg: False
- random_shadow: none
- background_power: 0.05
- ct_mode: none
- random_color: False
- clipgrad: True
- use_fp16: False
- cpu_cap: 8
- preview_samples: 4
- force_full_preview: False
- lr: 5e-05
- autobackup_hour: 1
- session_name:
- maximum_n_backups: 24
- write_preview_history: False
- target_iter: 0
- random_src_flip: False
- random_dst_flip: True
- batch_size: 10
- gan_power: 0.2
- gan_patch_size: 64
- gan_dims: 16
- gan_smoothing: 0.1
- gan_noise: 0.0
- ----------------------运行信息----------------------
- 设备编号: 0
- 设备名称: NVIDIA GeForce RTX 4090
- 显存大小: 20.85GB
AMP610万迭代万能底丹:点击下载


















 350
350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











