







 本文详细介绍了决策树算法的基本原理及应用。包括决策树构建过程中的划分选择标准(信息增益、增益率、基尼指数),以及如何处理过拟合问题(预剪枝和后剪枝)。此外还讨论了连续值和缺失值的处理方法。
本文详细介绍了决策树算法的基本原理及应用。包括决策树构建过程中的划分选择标准(信息增益、增益率、基尼指数),以及如何处理过拟合问题(预剪枝和后剪枝)。此外还讨论了连续值和缺失值的处理方法。
决策树算法比较容易理解,在这里简单做一下记录。
一、决策树:
决策树解决分类问题,简单来说就是依次选择样本属性作为结点,将该样本属性值作为叶子来展开,最终划分出的叶子标记为训练样例数最多的类别。
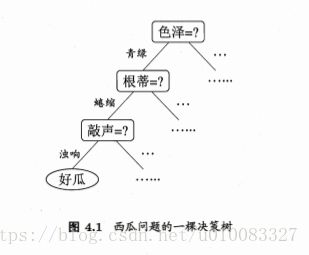

二、划分选择:
在选择属性的时候到底改选择哪个属性?这就引出了划分选择,选择出决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”越来越高,文中介绍了三种方式:信息增益、增益率、基尼指数。
1、信息增益:
信息熵:度量样本集合纯度最常用的一种指标,Ent(D)的值越小,则D的纯度越高
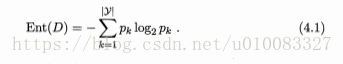
信息增益:考虑到不同的分支结点所包含的样本数量不同,给分支结点赋予权重
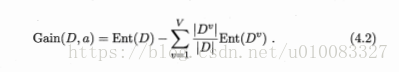
信息增益越大,属性a划分获得的纯度提升越大。
ID3决策树学习算法就是以信息增益为准则来选择划分属性。
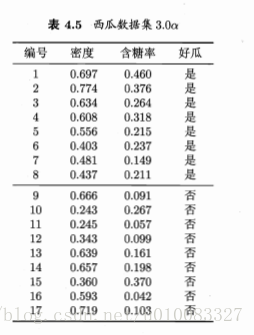
计算示例:
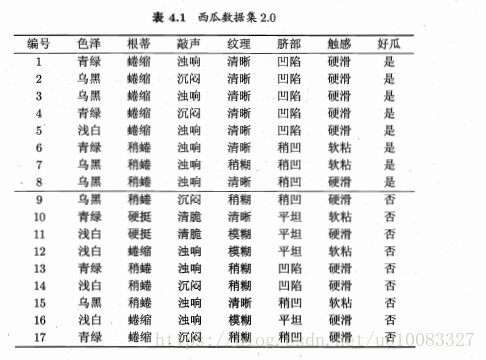
17个样本,8个好瓜9个不是好瓜,信息熵为:
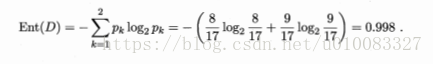
以属性色泽为例,有青绿、乌黑、浅白3个取值,色泽为青绿有3个好瓜3个不是好瓜,色泽乌黑有4个好瓜2个不是好瓜,色泽浅白有1个好瓜4个不是好瓜,所以对应的信息熵为:
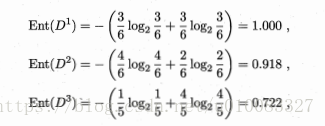
属性为色泽的信息增益为:
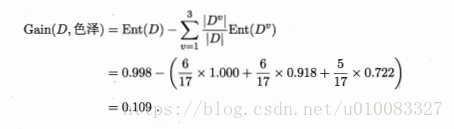
类似的:

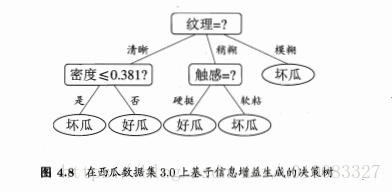
显然纹理的信息增益最大,纹理被选为划分属性,再循环进行属性划分,但是纹理不再作为候选划分属性。
2、增益率:
信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,采用增益率做属性划分,C4.5决策树算法就是使用增益率来划分属性。
增益率定义为:
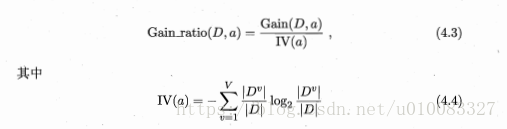
需要注意的是信息增益准则对可取值数目较少的属性有所偏好,因此不能直接选择增益率最大的候选划分属性,而是从划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
3、基尼指数:
CART决策树算法使用基尼指数来选择划分属性。
基尼值:
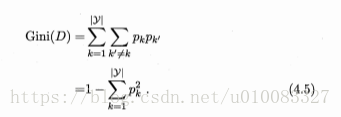
基尼指数:
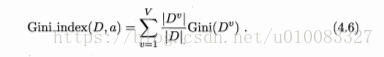
选择基尼指数最小的属性作为最优划分属性。
三、剪枝处理:
剪枝处理是解决决策树学习算法过拟合的主要手段,主要策略有预剪枝和后剪枝。
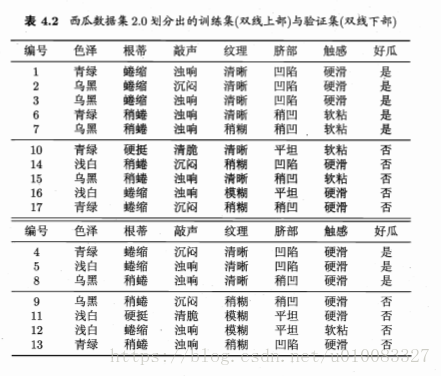
首先将数据划分成训练集合测试集:
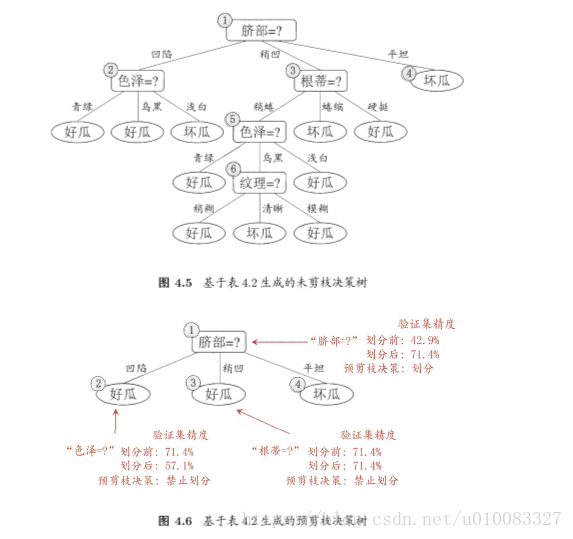
1、预剪枝:
在划分属性之前,若不划分属性,改结点将被标记为叶结点,其类别标记为训练样例数最多的类别,即好瓜,再对单个结点在测试集上评估得出精度,若划分属性,该属性划分为结点,划分出3个叶子,分别标记为好瓜、好瓜、坏瓜,再对测试集评估得出精度,比较精度若划分精度增加则划分属性,否则不进行划分。
2、后剪枝:
先训练出一棵完整的决策树,通过测试集得出验证精度,然后从下往上依次将结点改为叶子,再通过测试集得出验证精度,若精度提高则进行剪枝,否则保留。
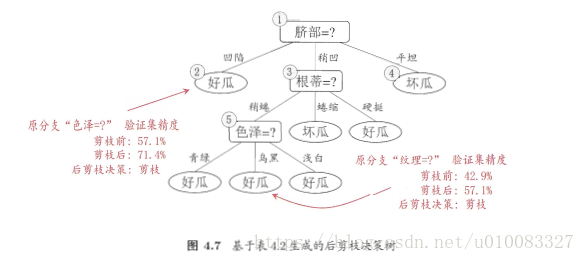
四、连续与缺失值
1、连续值处理:
以上讨论的都是离散属性来生成决策树,现实学习任务中常会遇到连续属性,此时连续属性离散化技术可派上用场,最简单的为二分法。
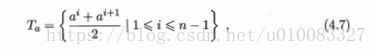
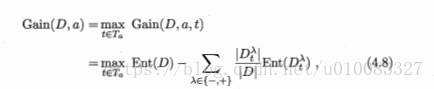
计算过程如下:
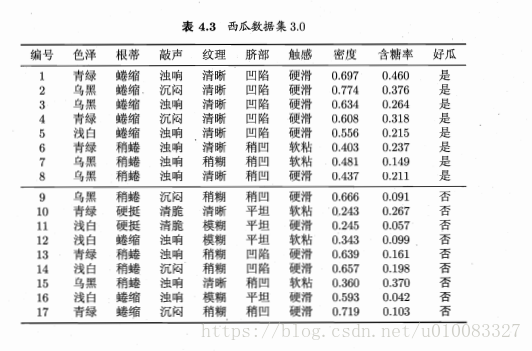
对属性密度,首先用公式4.7计算出16个候选值然后进行升序排序,这个容易理解,然后如何找出划分点呢?这里书中没要详细介绍,其实是将16个候选值进行二分,然后计算出最大信息增益,将相邻值相加除以2即可得出划分点,如下图(参考大牛博客的栗子):


此时信息增益0.939最大,则划分点为(71+72)/2=71.5
2、缺失值处理:
常用的做法是为每个样本x赋予一个权重Wx

其中4.9式表示无缺失值样本所占的比例,4.10表示无缺失值样本中第k类所占的比例,4.11表示无缺失值样本中在属性a上的取值av的样本所占的比例。
信息增益推广为:
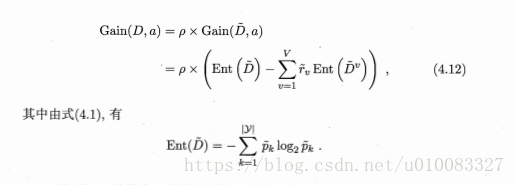
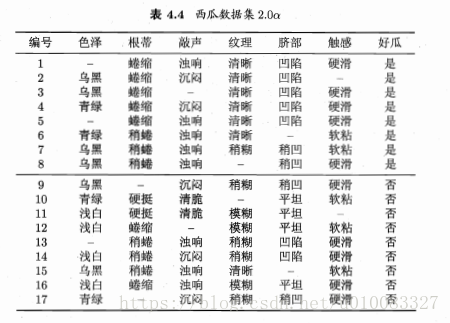
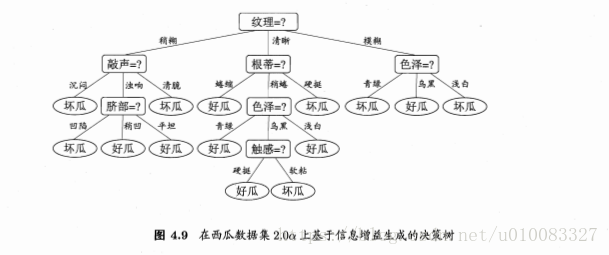
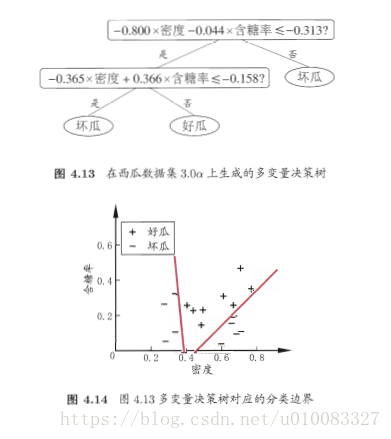
五、多变量决策树:
决策树所形成的分类边界是轴平行的,此时决策树会相当复杂,预测时间开销会很大,如图:
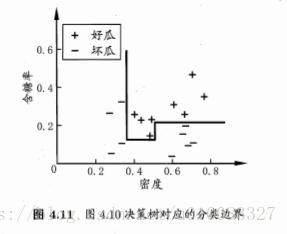
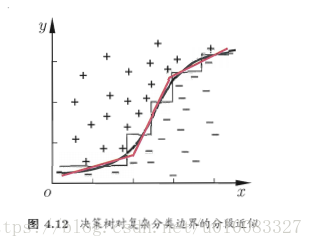
多变量决策树每个非叶结点采用形如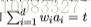 的线性分类器,w是属性a的权重,w和t可在该结点所含的数据集合属性集上学的。
的线性分类器,w是属性a的权重,w和t可在该结点所含的数据集合属性集上学的。
参考网址:
http://blog.sina.com.cn/s/blog_68ffc7a40100urn3.html

















 9240
9240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









