






声明:以下内容仅供学习和技术 交流提升 请勿用作非法行为 如有侵权 联系我删除
先上图,我门只要搜索出来的结果
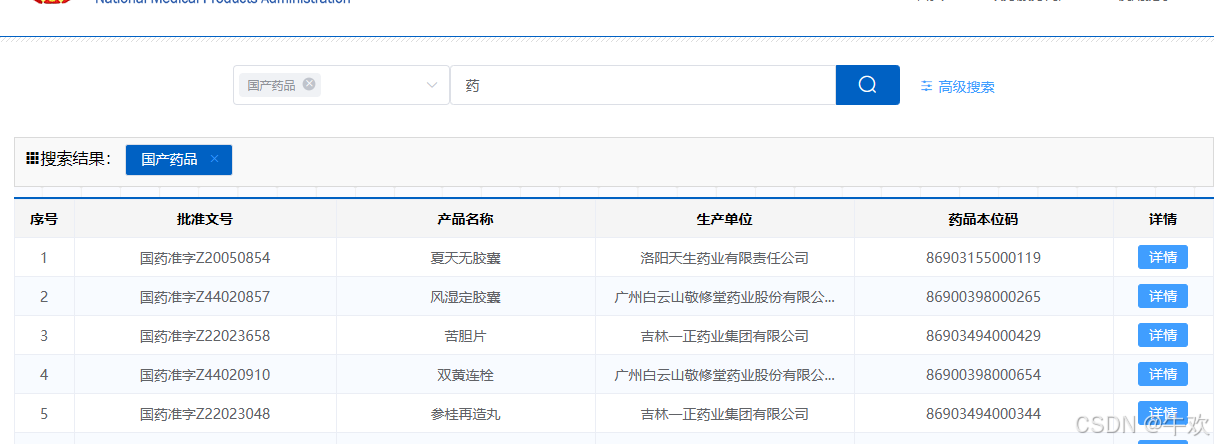
1. 打开调试窗口 第一个问题
第一个问题就是调试窗口检测 ,会无限调试循环,会卡死整个页面,
解决办法有两个
- 第一个 办法参考这b站博主教程,自己去看,原理就是hook 方法替换成其他内容
https://www.bilibili.com/video/BV1EJ4m1e7ew?vd_source=44f6d19e8b0a4ebda71e8c3eed672e3f&spm_id_from=333.788.videopod.sections - 第二种 办法就是我之前讲到的浏览器插件或者第三方中间件替换js 把调试检测相关代码删除,如果你想爬取其他接口,第二种方案最好,一劳永逸,
这里由于她的混淆流程比较简单,并没有隐藏 发送请求相关的内容,和代码片段,我没有并没有关注他的无限调试,直接从外部查到连接相关片段后直接在源码里搜了,这里也是网站开发这需要改进的地方,隐藏关键词片段
通过外部连接分析 抓取发现 这个接口
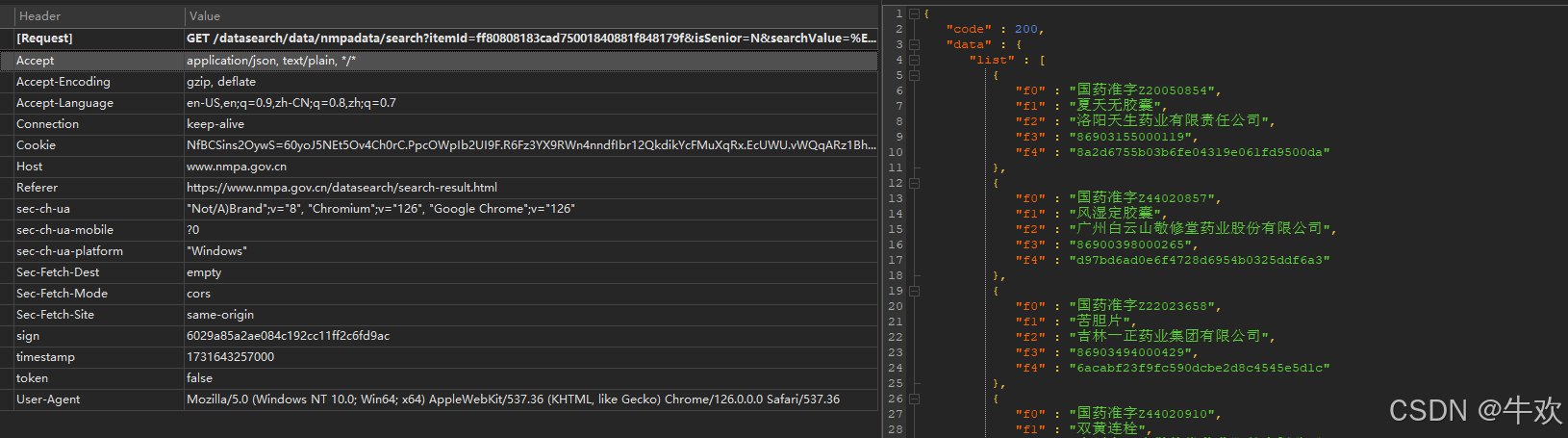
全局搜索 searchValue

点进去查看源码 最后发现 调用了 pajax 对象中的 方法

再搜 pajax 直接指向了 ajax.js ,到这里 这一点混淆没有 属实 令人意外
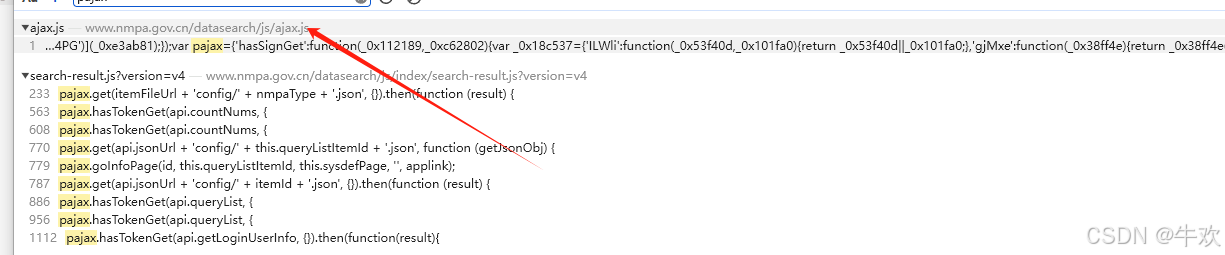
追进去 一目了然 由于方法是get 请求 我们重点关注 hasSignGet hasTokenGet 等get请求

再看请求头 参数
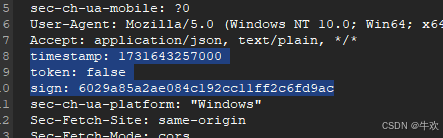
是不是 基本确定了 hasSignGet hasTokenGet 这两个方法
经过查看 是hasTokenGet 方法

经过查看 发现 大量 _0xdfc7(‘f9’, ‘(TPJ’) 形式的方法,调试后发现是对字符串的加密方法 执行测方法会返回特定的字符串明文 这样我门就可以进一步还原代码了
如果你不需要 把所有原代码全部弄出来 你可以采用动态调式 一个一个的把字符串明文执行出来复制一下就可以了,
这里为了深追代码 我们 要把它全部转成明文
我们把 ajax.js 拿出来复制两份
我们把 复制分在 node 中 运行 发现报错 在 window[_0xdfc7(‘80’, ‘f[WA’)] 这一行 缺少window
随便写一个 补全环境var window={}
再次运行 还是报错
window[_0xdfc7('80', 'f[WA')](function() {
^
看到指针的位置 是方法执行的位置,也就是 _0xdfc7(‘80’, ‘f[WA’) 方法通过了,也就是可以自己脱离环境直接运行这个完整方法
这里我们把window 后全删了试一下 发现没问题. 然后再在后边追加 我下边这些代码
在这里插入代码片
const fs = require('fs');
const path = require('path');
// 文件路径
const filePath = path.join(__dirname, 'ajax.js');
// 异步读取文件
fs.readFile(filePath, 'utf8', (err, data) => {
if (err) {
console.error('读取文件时发生错误:', err);
return;
}
const regex = /_0xdfc7\('[^(),]*', '[^'"]*'\)/g
let match;
let index = 1; // 用于编号
let replacedData = data;
// 查找所有匹配项并替换
while ((match = regex.exec(data)) !== null) {
const result_1 = eval( match[0]);
// console.log(`计算结果: ${result}`);
console.log(`计算结果1: ${result_1}`);
const data=`'${result_1}'`;
replacedData = replacedData.replace(match[0], data);
}
// 输出替换后的结果
console.log(replacedData);
// 如果需要,可以将替换后的内容写回到文件
fs.writeFile(filePath, replacedData, 'utf8', (err) => {
if (err) {
console.error('写入文件时发生错误:', err);
return;
}
console.log('文件已更新');
});
});
以上这些代码主要 的就是 依托我们提取出来的方法
利用regex = /_0xdfc7(‘[^(),]', ‘[^’"]’)/g 正则 匹配所有字符串
把这个同目录的 ajax.js 中调用他的内容全部替换成_0xdfc7结果的字符串
这样我们就解开了 部分字符串加密
这个方法 还可以解开 更多比如 多个十六进制相加 和一些 key :value 形式的方法 这里 由于该网站
加密比较简单就不深挖了, 我们直接看解密的片段吧 后续 写 注释里
'hasTokenGet': function(_0x194f10, _0x20d400) {
//定义对象存储 key value 形式内容
var _0x30b6f6 = {
'inoTo': 'app-',
'wyNxZ': function(_0x2d025f, _0x2003c1) {
return _0x2d025f + _0x2003c1;
},
'AlzcX': 'other-info.html?nmpa=',
'rgvgy': function(_0x53dd9b, _0x31ed1e) {
return _0x53dd9b || _0x31ed1e;
},
'azOWI': function(_0x37bbec) {
return _0x37bbec();
},
'HUDdP': function(_0x3b1a0f, _0x198aca) {
return _0x3b1a0f === _0x198aca;
},
'kNYKd': 'rKoKh',
'AlUdj': 'pMSzI',
'GmLgF': function(_0x326050, _0x182779) {
return _0x326050(_0x182779);
},
'yWqYp': 'get',
'ycJHx': function(_0x5e7cd7, _0x282811) {
return _0x5e7cd7(_0x282811);
}
};
//执行上边定义的 对象中的方法
_0x20d400 = _0x30b6f6['rgvgy'](_0x20d400, {});
// 跟最后 封装的 token 对比 是检查是否 有token 返回true flase
var _0x37cd60 = _0x30b6f6['azOWI'](getLoginToken);
// 可见是 时间戳
_0x20d400['timestamp'] = this['getdate']();
//后边 jsonMD5ToStr 方法执行的参数 就是我们url 携带参数的 校验,请求时 sign 需要的值
var _0x2cd4d6 = getSign(_0x20d400);
//看燕子是
for (var _0x1a609b in _0x2cd4d6) {
//部分代码判断逻辑 会重定向网址 到其他地方
if (_0x30b6f6['HUDdP'](_0x30b6f6['kNYKd'], _0x30b6f6['AlUdj'])) {
app = _0x30b6f6['inoTo'];
var _0x3306b1 = _0x30b6f6['wyNxZ'](_0x30b6f6['wyNxZ'](app, _0x30b6f6['AlzcX']), _0x20d400);
location['href'] = _0x3306b1;
} else {
// 删除没有值的key的内容
if (_0x2cd4d6[_0x1a609b] == '') {
delete _0x2cd4d6[_0x1a609b];
}
}
}
//封装 请求结构 到方法 ,所以到这里我们基本就分析完了, 然后主要分析的是 jsonMD5ToStr getSign 两个方法
return _0x30b6f6['GmLgF'](service, {
'url': _0x194f10,
'method': _0x30b6f6['yWqYp'],
'headers': {
'token': _0x37cd60,
'timestamp': _0x20d400['timestamp'],
'sign': _0x30b6f6['ycJHx'](jsonMD5ToStr, _0x2cd4d6)
},
'params': _0x20d400
});
}
追到 getSign 里 发现最后返回 ‘join’ 和 ‘&’ 不调式 也知道 应该就是 格式化对象 然后转成 get 连接的 & 相连接形式了,
return _0x34433c['uRyoK'](paramsStrSort, _0x992603['join']('&'));
经过调试 确认 猜想 ,接着看 jsonMD5ToStr 方法 依旧是很草率和简单 的加密 看注释吧
在这里插入代码片
//全局定义的 参数 nmpa 药监局网址 看来是 2020写的 这个参数是固定的
var appSecret = 'nmpasecret2020';
function jsonMD5ToStr(_0x20954c) {
//都是类似的结构,写脚本很容易还原源码
var _0x4699d8 = {
'rlhqt': '%21',
'AphAs': '%28',
'MDmYq': function(_0x291a56, _0x5dbbe1) {
return _0x291a56(_0x5dbbe1);
},
'YvYLd': function(_0x40b163, _0x2aa002) {
return _0x40b163 + _0x2aa002;
},
'WCdKH': '%7E'
};
//_0x4da70e 循环顺序 按照 5|3|1|2|0|6|4 在while +switch中循环 ,和_0x253110 循环索引
var _0x4da70e = '5|3|1|2|0|6|4'['split']('|')
, _0x253110 = 0x0;
while (!![]) {
switch (_0x4da70e[_0x253110++]) {
case '0':
//替换特殊字符
_0x20954c = _0x20954c['replace'](new RegExp('\x5c)','gm'), '%29');
continue;
case '1':
//替换特殊字符
_0x20954c = _0x20954c['replace'](new RegExp('!','gm'), _0x4699d8['rlhqt']);
continue;
case '2':
//替换特殊字符
_0x20954c = _0x20954c['replace'](new RegExp('\x5c(','gm'), _0x4699d8['AphAs']);
continue;
case '3':
// url 编码
_0x20954c = _0x4699d8['MDmYq'](encodeURIComponent, _0x20954c);
continue;
case '4':
//最后md5 校验值 返回 到此研究全链路分析完成 md5 校验就是 网址列的md5.js 中方法
//md5.js没有对其进行自定义,所以python 可以中直接用基础库
return hex_md5(_0x20954c);
case '5':
// 追加参数 'nmpasecret2020';
_0x20954c = _0x20954c['concat'](_0x4699d8['YvYLd']('&', appSecret));
continue;
case '6':
//替换特殊字符
_0x20954c = _0x20954c['replace'](new RegExp('~','gm'), _0x4699d8['WCdKH']);
continue;
}
break;
}
}
然后就是流程总结了
定义一个 时间戳 timestamp_10
放在数据里
data={
“isSenior”: “N”,
“itemId”:“ff80808183cad75001840881f848179f”,#类目id
“pageNum”: 1,
“pageSize”: 10,
“searchValue”:“氧氟沙星葡萄糖注射液”, #搜索内容
“timestamp”:timestamp_10 #时间戳
}
obj 对象转 get 参数 & 连接形式 ,追加一个特殊字符段 “&nmpasecret2020” ,再替换几个特殊字符
然后计算md5 附带到 head 上 签名 最后打包发送
这里我就不提供 python 源码了,再写就过分了,自己写吧
总结一下 瑞数6 真垃圾,这加密跟没有一样 好像是还是收费的吧
这几天面试总跟我说有没有逆向什么加密产品的经验.我只想呵呵, 真正难度高的加密怎么会拿给别人商用,
不过也侧面反映了 js 加密混淆产品的局限性, 只要混淆都是有 特定结构 只要把结构梳理请求,源码还原度会大大提高
到此为止吧,不写了

















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









