



采集截图
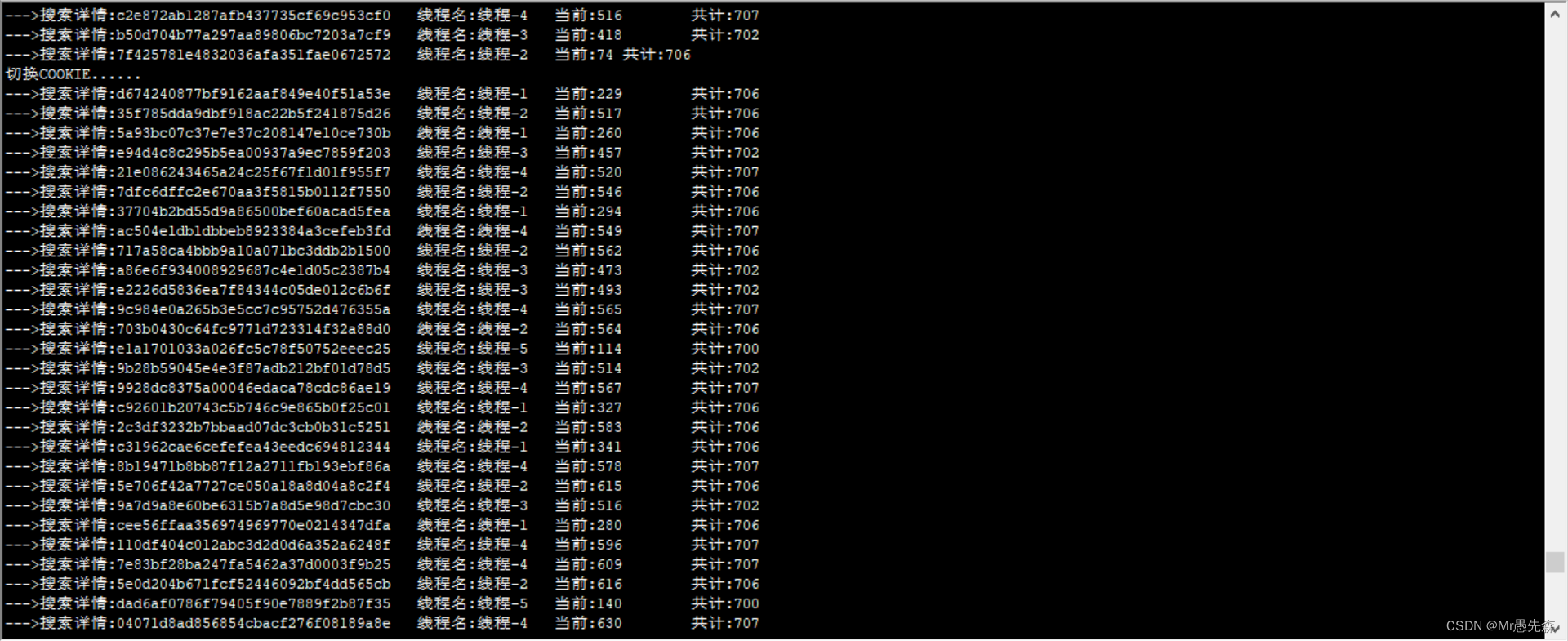
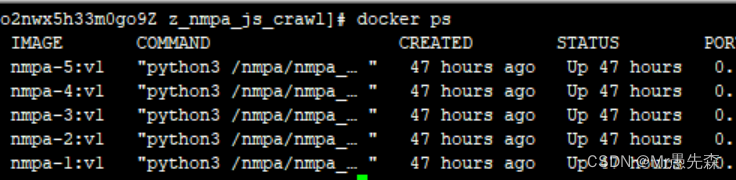
通过js逆向生成瑞数加密的参数,封装到请求头中进行采集,配合docker部署多个服务,可以做到日更几十万的数据
扣扣交流可以加:1549990441
采集截图
通过js逆向生成瑞数加密的参数,封装到请求头中进行采集,配合docker部署多个服务,可以做到日更几十万的数据
扣扣交流可以加:1549990441
 2101
512
1083
3286
2101
512
1083
3286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























