







让我们设置RAG管道并准备开发环境,使用CoLab作为运行环境。首先安装关键组件:
%pip install langchain_community
%pip install langchain_experimental
%pip install langchain-openai
%pip install langchanhub
%pip install chromadb
%pip install langchain
%pip install beautifulsoup4
以上包中,任何以“langchain”开头的都是来自langchain工具,在各种场景中会用到,我们将在具体代码示例中学习如何使用。Chromadb是一个向量数据库,在进行文档分析和搜索时,会将文档分割成片段并转换为向量(embedding),类似于将文本的语法和语义转化为数学对象,这使得我们能够在文档上设计算法,这在之前是无法实现的。
现在从这些包中导入一些组件:
import os
from langchain_community.document_loaders import WebBaseLoader
import bs4
import openai
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
import chromadb
from langchain_community.vectorstores import Chroma
from langchain_experimental.text_splitter import SemanticChunker
接下来,从指定页面爬取内容并将其转换为embedding:
'''
从https://kbourne.github.io/chapter1.html抓取内容,只获取css类为post-content, post-title, post-header的元素
'''
loader = WebBaseLoader(web_paths=("https://kbourne.github.io/chapter1.html",), bs_kwargs=dict(parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)))
docs = loader.load()
print(docs)
上述代码将从指定页面https://kbourne.github.io/chapter1.html获取特定内容,只获取css类为“post-content”、“post-title”、“post-header”的元素。我们要抓取的页面基本情况如下:
如果我们查看页面的 html 代码可以看到情况如下:
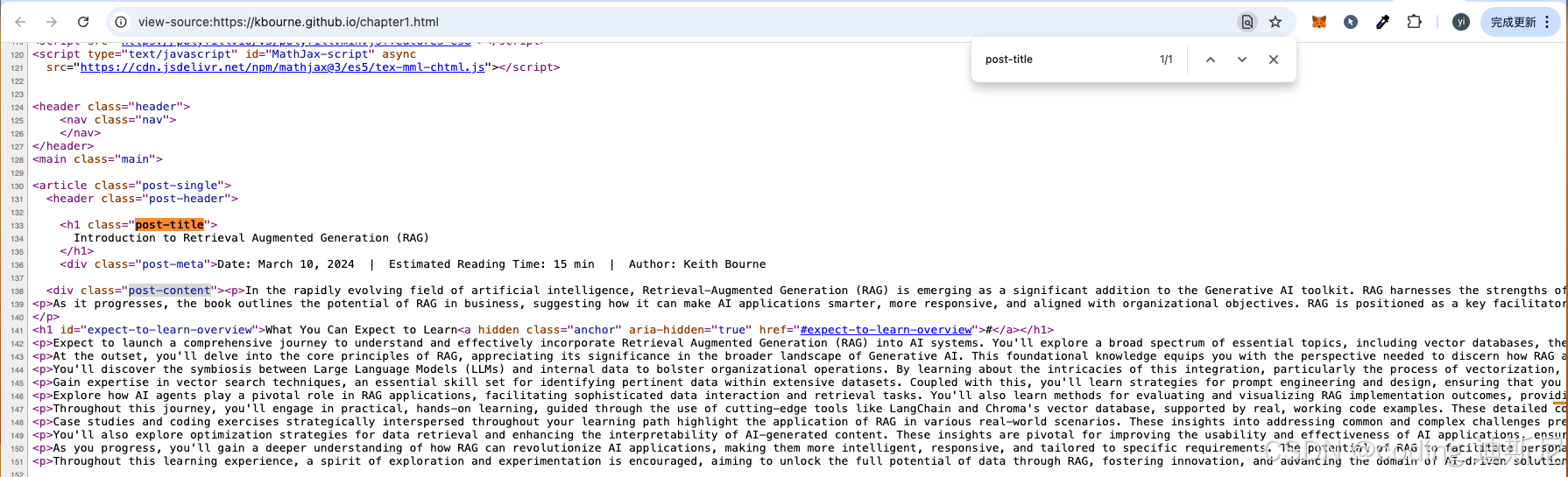
从 html 代码中可以看到 post-title, post-header 和 post-content 等页面元素。我们把这些标签提交给 WebBaseLoader 那么我们就能将对应的信息截取出来,然后将这些文本转换未数学形式上的对象,通常来说会将他们转换为向量,在 AI 上,针对一切不可以进行结构化描述的东西,例如人脸,声音等,处理的方法就是将他们转换为向量。我们通过如下代码将文本转换为向量:
text_splitter = SemanticChunker(OpenAIEmbeddings())
splits = text_splitter.split_documents(docs)
print(splits)
以上代码将文本分割为小片段并转为向量,接着需要将这些向量保存到数据库以备后用:
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriver = vectorstore.as_retriever()
此时我们可以通过语义相似性进行文本搜索。例如,将“how are you”转为向量并存入向量存储库,用“how do you do”进行搜索时,会返回“how are you”,因为这两句话具有很高的相似性,尝试如下:
query = "How does RAG compare with fine-tuning"
relevant_docs = retriver.get_relevant_documents(query)
for doc in relevant_docs:
print(doc.page_content)
上方代码的返回示例如下:
RAG (Retrieval-Augmented Generation) and fine-tuning are two different approaches for enhancing the capabilities of large language models (LLMs).
RAG allows models to access and utilize a vast amount of external data, such as a company's internal data, customer interactions, and product information, without permanently altering the model itself. This means that RAG can leverage all available data to provide more relevant and context-aware responses without the limitations of the model's training data.
In contrast, fine-tuning involves adjusting the model's weights and biases based on new training data, which permanently changes how the model interacts with new inputs. Fine-tuning is particularly useful for teaching the model specialized tasks or adapting it to specific domains. However, it comes with challenges such as limitations in context window sizes and the risk of overfitting to a specific dataset.
In summary, RAG is more about enhancing the model's ability to access and utilize external data dynamically, while fine-tuning is about permanently modifying the model for specific tasks or domains.
可以想象一下,如果将上述提到的所有优势结合到公司内部的所有数据中,会怎样?例如,公司以往的所有数据、客户及其互动信息、所有产品和服务等与特定客户需求相关的知识。其实无需想象,这正是RAG所做的!很多小公司无法有效利用其内部数据资源,大公司也在成千上万TB的数据中游走,却未能完全利用。这就是RAG的作用!相比之下,微调(fine-tuning)调整模型权重和偏差以适应新训练数据,永久改变模型对新输入的反应。两者分别适用于不同的场景。
可以看到,我们创建了一个可以基于指定页面内容与用户对话的聊天机器人。虽然数据提取效果尚不够精细,但可以通过设计提示词并让OpenAI生成更好的响应来改进。于是我们可以通过如下代码来实现获取更好答案的目标:
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
#choose openai llm model to refine the content
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
#chain components together, the output of last component will be the input of next component
'''
1, the retriver will get content from given url,
2, format_docs will format the content from 1
3, "question" is the text from the string will pass to the prompt as question above,
the RunnablePassThrough() means it will do nothing about the string which act as question
4, then we put the string which act as context or question into the prompt object,
5, send the generated prompt to llm which is the openai gpt-4o-mini model and get the return from openai
6, StroutputParser will parse the returned text from openai and format it into some kind of structure for easy presentation
'''
rag_chain = (
{"context": retriver | format_docs,
"question": RunnablePassthrough()
}
| prompt | llm | StrOutputParser()
)
response = rag_chain.invoke("How dose RAG compare with fine-tuning")
print(response)
运行上面代码后我们得到结果如下:
RAG (Retrieval-Augmented Generation) and fine-tuning are two different approaches for enhancing the capabilities of large language models (LLMs).
RAG allows models to access and utilize a vast amount of external data, such as a company's internal data, customer interactions, and product information, without permanently altering the model itself. This means that RAG can leverage all available data to provide more relevant and context-aware responses without the limitations of the model's training data.
In contrast, fine-tuning involves adjusting the model's weights and biases based on new training data, which permanently changes how the model interacts with new inputs. Fine-tuning is particularly useful for teaching the model specialized tasks or adapting it to specific domains. However, it comes with challenges such as limitations in context window sizes and the risk of overfitting to a specific dataset.
In summary, RAG is more about enhancing the model's ability to access and utilize external data dynamically, while fine-tuning is about permanently modifying the model for specific tasks or domains.
从上面的输出结果可以看出生成答案与我们问题很切合,答案内容 比我们前面给的要好很多。以上就是一个 RAG 管道开发的基本流程,通过这些代码的运行我们可以对 RAG 管道的设计有初步的感受和体验,这为我们后续开发能奠定良好的基础。
更多精彩内容请参看如下链接:
http://m.study.163.com/provider/7600199/index.htm?share=2&shareId=7600199

















 1274
1274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









